



It is very crucial for the machine learning enthusiasts to know and understands the basic and important machine learning algorithms in order to keep themselves up with the current trend. In this article, we list down 10 basic algorithms which play very important roles in the machine learning era.
1| Logistic Regression
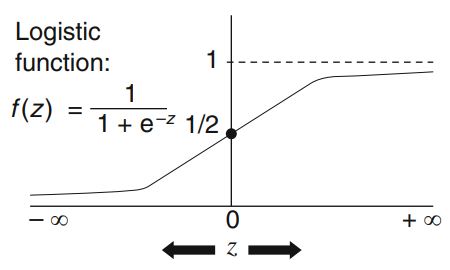
Logistic regression, also known as the logit classifier is a popular mathematical modelling procedure used in the analysis of data. Regression Analysis is used to conduct when the dependent variable is binary i.e. 0 and 1. In Logistic Regression, logistic function is used to describe the mathematical form on which the logistic model is based. The reason behind the popularity of the logistic model is that the logistic function estimates that the variable must lie between 0 and 1.
Click here to learn more.
2| K-Nearest Neighbours
K-Nearest Neighbours is one of the most essential classification algorithms. It is also known as the lazy learning as the function is only approximated locally and all the computations are deferred until classification. The algorithm selects the k nearest training samples for a test sample and then predicts the test sample with the major class amongst k nearest training samples.
Click here to learn more.
3| Naive Bayes
This simple classification algorithm is based on the Bayes Theorem. The algorithm aims to calculate the conditional probability of an object with a feature vector which belongs to a particular class. It is called “Naive” because it makes the assumption that the occurrence of a certain feature is independent of the occurrence of other feature.
Click here to learn more.
4| Support Vector Machines
Support Vector Machine is a supervised learning technique which represents the datasets as points. The main goal of SVM is to construct a hyperplane which divides the datasets into different categories and the hyperplane should be at the maximum margin from the various categories. This algorithm helps in removing the over-fitting nature of the samples and provides better accuracy.
Click here to learn more.
5| Random Forest
Random Forests are basically the combination of tree predictors where each tree depends on the values of a random vector that are sampled independently and with the same distribution for all the trees in the forest. This technique is easy to use as well as flexible because it can be both used for classification and regression tasks.
Click here to learn more.
6| Linear Regression
Linear Regression analysis estimates the coefficients of the linear equation which involves one or more independent variables where the variable which you want to predict is known as the dependent variable and the variable which you are using to predict the other variables is called the independent variable. The simple linear regression is a model which has a single regressor x which has a relationship with a response y that is a straight line.
Hence y=A.x+B; where A is the intercept and B is the slope.
Click here to learn more.
7| Neural Network
This set of the algorithm is modelled by imitating the human brain which interprets the sensory data through a kind of machine perceptions, labelling or clustering raw inputs. The neural networks can be used as a clustering or classification layer on top of the data which is stored and managed.
Convolution Neural networks are deep artificial neural networks which are used to classify images, cluster them by similarity as well as perform object recognition within scenes. They are algorithms that can identify faces, individuals, street signs, tumors, platypuses and many other aspects of visual data.
Recurrent Neural Networks are specially used for processing sequential data such as sound, time series, or written natural languages. This technique differs from the feedforward networks because they include a feedback loop.
Click here to learn more.
8| PCA
Principal Component Analysis forms the basis for multivariate data analysis. This statistical method converts a set of observations of possible correlated variables into a set of values of linearly uncorrelated variables. This method is helpful in evaluating the minimum number of factors for the maximum variance in the data.
Click here to learn more.
9| K-Means Clustering
The K-means clustering is a method which is commonly used to automatically partition a dataset into k groups. The algorithm proceeds by selecting the k initial cluster centres and the iteratively filtering them as each instance are assigned to its closest cluster centre whereas each cluster centre is updated to the mean of its constituent. And finally, the algorithm converges when there is no further change in assignment of instances to clusters. This method is popular for cluster analysis in data mining.
Click here to learn more.

Fig: K-means Convergence
10| Linear Discriminant Analysis
This method is basically used for classification of data as well as dimensionality reduction. LDA can easily handle the case where the within-class frequencies are unequal and their performances have been examined on randomly generated test data. This method also helps to better understand the distribution of the feature data.
Click here to learn more.














































































