
Layers in the deep learning model can be considered as the architecture of the model. There can be various types of layers that can be used in the models. All of these different layers have their own importance based on their features. Like we use LSTM layers mostly in the time series analysis or in the NLP problems, convolutional layers in image processing, etc. A dense layer also referred to as a fully connected layer is a layer that is used in the final stages of the neural network. This layer helps in changing the dimensionality of the output from the preceding layer so that the model can easily define the relationship between the values of the data in which the model is working. In this article, we will discuss the dense layer in detail with its importance and work. The major points to be discussed in this article are listed below.

Let’s begin with these discussion points one by one.
What is a Dense Layer?
In any neural network, a dense layer is a layer that is deeply connected with its preceding layer which means the neurons of the layer are connected to every neuron of its preceding layer. This layer is the most commonly used layer in artificial neural network networks.
The dense layer’s neuron in a model receives output from every neuron of its preceding layer, where neurons of the dense layer perform matrix-vector multiplication. Matrix vector multiplication is a procedure where the row vector of the output from the preceding layers is equal to the column vector of the dense layer. The general rule of matrix-vector multiplication is that the row vector must have as many columns like the column vector.
The general formula for a matrix-vector product is:

Where A is a (M x N) matrix and x is a (1 ???? N) matrix. Values under the matrix are the trained parameters of the preceding layers and also can be updated by the backpropagation. Backpropagation is the most commonly used algorithm for training the feedforward neural networks. Generally, backpropagation in a neural network computes the gradient of the loss function with respect to the weights of the network for single input or output. From the above intuition, we can say that the output coming from the dense layer will be an N-dimensional vector. We can see that it is reducing the dimension of the vectors. So basically a dense layer is used for changing the dimension of the vectors by using every neuron.
As discussed before, results from every neuron of the preceding layers go to every single neuron of the dense layer. So we can say that if the preceding layer outputs a (M x N) matrix by combining results from every neuron, this output goes through the dense layer where the count of neurons in a dense layer should be N. We can implement it using Keras, in the next part of the article we will see some of the major parameters of the dense layer using Keras with their definitions.
Dense Layer from Keras
Keras provide dense layers through the following syntax:
tf.keras.layers.Dense(
units,
activation=None,
use_bias=True,
kernel_initializer="glorot_uniform",
bias_initializer="zeros",
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
Keras Dense Layer Hyperparameters
As we can see a set of hyperparameters being used in the above syntax, let us try to understand their significance.
- Units: Units are one of the most basic and necessary parameters of the Keras dense layer which defines the size of the output from the dense layer. It must be a positive integer since it represents the dimensionality of the output vector.
- Activation: In neural networks, the activation function is a function that is used for the transformation of the input values of neurons. Basically, it introduces the non-linearity into the networks of neural networks so that the networks can learn the relationship between the input and output values.
If in this Keras layer no activation is defined it will consider the linear activation function. The following options are available as activation functions in Keras.- Relu function (
activation = activations.relu) – rectified linear unit activation function - Sigmoid function(
activation = activations.sigmoid) – Sigmoid activation function, sigmoid(x) = 1 / (1 + exp(-x)). - Softmax function(
activation = activations.softmax) – softmax converts a vector of value to a probability distribution. - Softplus function(
activation = activations.softplus) – Softplus activation function, softplus(x) = log(exp(x) + 1). - Softsign function(
activation = activations.softplus) – Softsign activation function, softsign(x) = x / (abs(x) + 1). - Tanh function(
activation = activation.tanh) – Hyperbolic tangent activation function - Selu function(
activation = activations.selu) – Scaled Exponential Linear Unit (SELU). - Elu function(
activation = activations.elu) – Exponential Linear Unit. - Exponential function(
activation = activations.exponential) – Exponential Activation function.
- Relu function (
- use_bias:
Use_Biasparameter is used for deciding whether we want a dense layer to use a bias vector or not. It is a boolean parameter if not defined then use_bias is set to true. - kernel_initializer : This parameter is used for initializing the kernel weights matrix. The weight matrix is a matrix of weights that are multiplied with the input to extract relevant feature kernels.
- bias_initializer: This parameter is used for initializing the bias vector. A bias vector can be defined as the additional sets of weight that require no input and correspond to the output layer. By default, it is set as zeros.
- Kernel regularizer: This parameter is used for regularization of the kernel weight matrix if we have initialized any matrix in the kernal_initializer.
- bias_regularizer: This parameter is used for regularization of the bias vector if we have initialized any vector in the bias_initializer. By default, it is set as none.
- Activity_regularizer: This parameter is used for the regularization of the activation function which we have defined in the activation parameter. It is applied to the output of the layer. By default, it is set as none.
- kernal_constraint: This parameter is used to apply the constraint function to the kernel weight matrix. By default, it is set as none.
- Bias_constraint: This parameter is used to apply the constraint function to the bias vector. By default, it is set as none.
Basic Operations with Dense Layer
As we have seen in the parameters we have three main attributes: activation function, weight matrix, and bias vector. Using these attributes a dense layer operation can be represented as:
Output = activation(dot(input, kernel) + bias)
Where if the input matrix for the dense layer has a rank of more than 2, then dot product between the kernel and input along the last axis of the input and zeroth axis of the kernel using the tf.tensordot calculated by the dense layer if the use_bias is False.
How to Implement the Dense Layer?
In this section of the article, we will see how to implement a dense layer in a neural network with a single dense layer and a neural network with multiple dense layers.
A sequential model with a single dense layer.
import tensorflow
model = tensorflow.keras.models.Sequential()
model.add(tensorflow.keras.Input(shape=(16,)))
model.add(tensorflow.keras.layers.Dense(32, activation='relu'))
print(model.output_shape)
print(model.compute_output_signature)Output:

Here in the output, we can see that the output of the model is a size of (None,32) and we are using a single Keras layer and the signature of the output from the model is a sequential object.
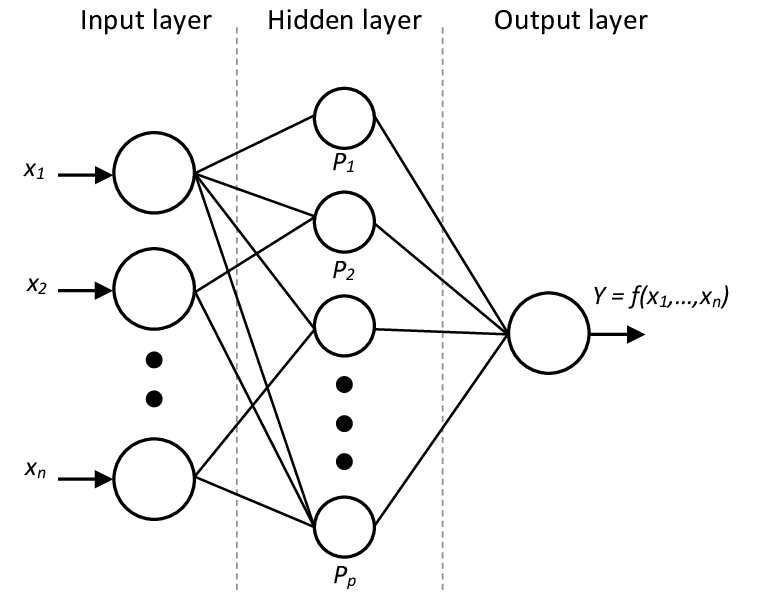
The above image represents the neural network with one hidden layer. If we consider the hidden layer as the dense layer the image can represent the neural network with a single dense layer.
A sequential model with two dense layers:
model1 = tensorflow.keras.models.Sequential()
model1.add(tensorflow.keras.Input(shape=(16,)))
model1.add(tensorflow.keras.layers.Dense(32, activation='relu'))
model1.add(tensorflow.keras.layers.Dense(32))
print(model1.output_shape)
print(model1.layers)
print(model1.compute_output_signature)Output:

Here in the output, we can see that the output shape of the model is (None,32) and that there are two dense layers and again the signature of the output from the model is a sequential object.
After defining the input layer once we don’t need to define the input layer for every dense layer.
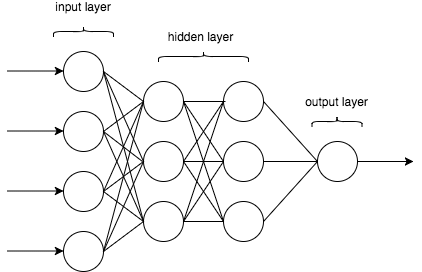
The above image represents the neural network with one hidden layer. If we consider the hidden layer as the dense layer the image can represent the neural network with multiple dense layers.
In the model we are giving input of size (None,16) to the dense layer and asking the dense layer to provide the output array of shape (32, None) by using the units parameter as 32, also in both sequential models are using the ReLU activation function.
If the input for a dense layer is of shape (batch_size, …, input dim) then the output from the dense layer will be of shape (batch size, units).
Note – the dense layer is an input layer because after calling the layer we can not change the attributes because as the input shape for the dense layer passes through the dense layer the Keras defines an input layer before the current dense layer.
Final words
Here in the article, we have seen what is the intuition behind the dense layer. We have also seen how it can be implemented using Keras. We looked at the hyper parameters of the Keras dense layer and we understood their importance. Since it is a fundamental part of any neural network we should have knowledge about the different basic layers along with the dense layer.




