





This article is intended as a research brief on Apache Tez, an emerging open source technology. Tez is useful for a number of applications which need to execute a series of Map-Reduce jobs (chaining). By executing the series of MR tasks as a single job and cutting down the consequent intermediate reads and writes from/to HDFS, Tez can execute a Directed Acyclic Graph (DAG) of MR jobs very efficiently. It is the basis for Hive 13 or Stinger, the upcoming version of Hive and can speed up Pig scripts significantly.
Motivation
Hadoop, the open source implementation of the Google Map-Reduce paper [1], has enabled end users to process large amounts of data. Consequently, it has been used in several contexts, both for use cases that are well suited for it and also for uses cases where it has been force-fitted. Data crunching, especially the embarrassingly parallel kind is ideally suited for Hadoop.
However, it has been observed by a number of researchers that Hadoop 1.0 (the plain MR version of Hadoop) is not well suited for real-time scenarios [2] or for machine learning involving iterative processing [3] [4] [5]. By iterative processing, we mean the following kind, as depicted in the figure below.

The main reason why Hadoop 1.0 is not well suited to iterative processing is the repeated read/write from/to the Hadoop Distributed File System (HDFS) for every iteration – there are no long lived MR jobs and every iteration has to be realized as a fresh MR job, with data being initialized by reading from HDFS and written back to HDFS at the end of the iteration. Moreover, the termination condition for iteration, which may itself involve certain computation, may also have to be realized as a separate MR job.
With the advent of Hadoop 2.0 or Hadoop Yet Another Resource Negotiator (YARN), the need for executing a workflow or a DAG of MR jobs becomes critical. It should be noted that Hadoop YARN separates out the processing paradigm (MR) from the resource management functions, which were tied up together in Hadoop 1.0. Thus, in Hadoop YARN, the resource management functionality is handled by the YARN resource manager, while several frameworks can work on top of YARN. The possible frameworks that may work on top of YARN include Spark for iterative processing, Storm for real-time processing, GraphLab/Giraph for graph processing as can be evidenced from the diagram given below [8]:
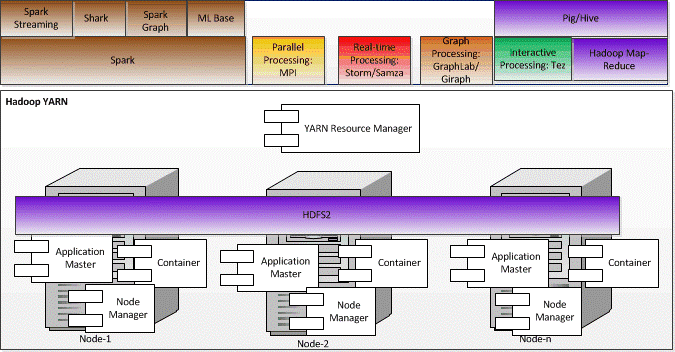
Thus, one can say that Hadoop YARN has enabled several processing frameworks to co-exist and process HDFS data in various ways. Consequently, this motivates the need for an application that can efficiently execute a DAG of tasks. The vanilla Hadoop 1.0 way of expressing DAG as a chain of individual MR jobs can significantly impact the efficiency.
This is where Tez fits in – it provides a framework for executing DAG of tasks efficiently. For instance, a single SQL query or a simple PIG script can be executed as a single DAG in Apache Tez.
Apache Tez
Tez allows an application to be modeled as a data flow – with edges representing movement of data, while vertices represent data processing tasks. It should be noted that high level query languages such as Pig and Hive produce a DAG for execution after processing the query/script. This, Tez fits in perfectly as an executor for Pig and Hive jobs – it can speed up such jobs significantly.
Given below is an example of a two stage MR application – data is sorted topologically in the first stage, while the frequency of occurrence is computed in the next stage. This can be expressed as two traditional MR jobs with intermediate results placed in HDFS. The same can also be expressed as a Pig script as follows:

When executed on Tez, the same Pig script runs as a single job that is expressed as a simple DAG comprising two stages. Tez takes care of expressing this logical graph as a physical graph of tasks and their dependencies and executes them efficiently on a cluster of nodes.
Tez Internals
Every vertex of the dataflow graph can be modeled as a combination of input, processing and output modules – where the input module specifies the set of edges required for this task as input, while the processing refers to the data transformation as part of this vertex and output refers to the output data written by this transformation and passed through the incident out edges of this node/vertex. The vertex can be viewed as equivalent to a task in Tez. The parallelism of the task can be specified at DAG construction time or via user plugins running in the Application Master (AM), a component of Hadoop YARN.
The context/configuration information (environment or application specific) is provided to the three modules through an initialization routine which gets invoked first. Subsequently, the run method of the Processor is invoked for every task instance (based on parallelism factor). Once this method finishes, the task is logically completed.
The output (via the LogicalOutput class) in addition to writing out the data from the Processor, also provides information to subsequent /downstream Input stages (for a chain of tasks or a typical DAG).
Tez also provides sophisticated error handling to handle both fatal errors (that require termination of the task) and non-fatal errors (that may require re-reading the input, for instance).
One of the unique features of Tez is the ability to dynamically optimize the DAG execution – the information available at runtime such as data samples and sizes is used to optimize the DAG execution plan. Tez works perfectly with Hadoop YARN and can negotiate with the resource manager component of YARN and accept YARN containers for execution.
Conclusions
This research brief has explained the basics of Apache Tez and how we at Impetus have started using it. The future of Tez looks bright, as Tez is being integrated by the Pig community as their execution engine. Concurrent Inc. is also moving to Tez as the execution engine for Cascading. Tez is also being used by the Hive community as the basis execution engine for Hive 13. The Mahout community is also evaluating Tez as an alternative to MR. The Tez community have also tested version 0.3 of Tez on large clusters (beyond 300 nodes) and on large data sets (beyond 30 Terabytes). We are also planning to evaluate the possibility of realizing large scale distributed deep learning networks using Apache Tez.
Authors: Dr. Vijay Srinivas Agneeswaran, Director, Big Data Labs, Impetus Infotech India Pvt. Ltd. Email: vijay.sa@impetus.co.in
Inelu Nagamallikarjuna Reddy, Software Engineer, Big Data Labs, Impetus Infotech India Pvt. Ltd.
Email: inelu.naga@impetus.co.in


















