Machine Learning as the name signifies allows machines to learn with huge volumes of data that an algorithm can process to make predictions. Essentially, machine learning eliminates the need to continuously code or analyze data themselves to solve a solution or present a logic.
In other words, this form of AI enables a computer’s ability to learn and teach itself to evolve as it is fed new data. And since machine learning deploys an iterative approach to glean from data, this learning process is automated and the models are run until a robust pattern is found. ML software constitutes of two main elements — statistical analysis and predictive analysis which is used to spot patterns and uncover hidden insights from previous computations without being programmed.
The term machine learning was first coined by Arthur Samuel in 1959, this was when interest in AI was beginning to blossom. Borrowing the core ideas of AI, Machine Learning gained prominence in the 1990s when IBM’s Deep Blue beat the world champion at chess.
What’s “Deep” About Deep Learning
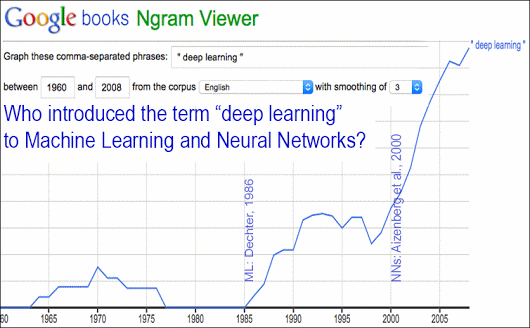
Deep Learning, as the term “deep” specifies is inspired by the human brain and it consists of artificial neural networks (ANN) that are modelled on a similar architecture present in the human brain. In Deep Learning, the learning is performed through a deep and multi-layered “network” of interconnected “neurons”. The term “deep” usually refers to the number of hidden layers in the neural network. According to a Mathwork blog, traditional neural networks only contain 2-3 hidden layers, while deep networks can have as many as 150. In 2006, Geoffrey Hinton coined the term “deep learning” to explain new algorithms that allow computers to distinguish objects and text in images and videos.
Did Hinton Really Introduce the Term Deep Learning?

Although deep learning nets had been in existence since the 1960s and backpropagation was also invented, this technique was largely forsaken by the machine-learning community and ignored by the computer-vision and speech-recognition communities, Hinton shared in a journal. It was widely thought that learning useful, multistage, feature extractors with little prior knowledge was not feasible.
The terminology Deep Learning was widely adopted only in the millennium and has now made way into boardrooms. Even though multi-layered feed forward nets have existed forever, the old research work took off with the new marketing buzzword, Deep Learning. According to this Google graph, neural nets existed in the 1960s, but the technology took off after 2005 when the term was introduced by Aizenberg & Aizenberg & Vandewalle’s book Multi-Valued and Universal Binary Neurons: Theory, Learning and Applications in 2000. Check out this Google graph that shows how the popularity of deep learning soared after the publication of the book.
Feature Extraction Sets Apart ML From DL
Over the years, machine learning has evolved in its ability to crunch huge volumes of data and is widely used in everyday applications technology. ML powers many aspects of our daily interaction –from spam filtering to content filtering on social networks, recommendations on e-commerce sites, and it is increasingly present in consumer products such as cameras and smartphones, the speech recognition (as in Siri, Apple’s voice assistant) and handwriting recognition (Optical Character Recognition).
However, one of the main differences between DL and ML, specified by Deep Instinct CEO Guy Caspi, a leading mathematician and data scientist is the manual intervention in selecting which features to process, wherein deep learning, the algorithms perform this intuitively. Feature extraction is a major component of the machine learning workflow, which means that the developer will have to give only relevant information to the algorithm so that it can determine the right solution and to improve the effectiveness of the algorithm.

In fact, many programmers point out that feature extraction is a painstaking process and relies a lot on how insightful the developer is. Hence, for complex problems such as object recognition or handwriting recognition, feature extraction in traditional ML becomes a huge challenge. On the other hand, in Deep Learning, raw data can be fed via neural networks and extract high-level features from the raw data.
Caspi outlined three crucial features that sets Machine Learning apart from Deep Learning:
- While feeding raw data in machine learning doesn’t work, deep neural networks do not require manual feature engineering. Instead, it learns on its own by processing and learning the high-level features from raw data
- Deep Learning’s self-learning capabilities mean higher accuracy of results and faster processing. Since machine learning requires manual intervention, this results in decreased accuracy and can lead to human error during the programming process
- DL can learn high-level, non-linear features necessary for accurate classification. For example, if one uses traditional machine learning algorithms for computer vision problem, you would need time to extract the important features from hundreds of images. In Deep Learning, one can feed raw pixels to process images and correctly classify objects in images with higher accuracy
DL Algorithms Scale With Data Vis-à-Vis ML
Besides the automated feature extraction in deep learning models which makes it highly suitable for computer vision tasks such as image classification and face recognition, deep learning algorithms scale with data, as opposed to machine learning. Machine learning techniques perform well at a certain level, but when one adds more training data to the network. One of the major advantages of deep learning networks is that the models continue to improve as the size of the data increases.
In machine learning the converse is true. More data doesn’t always help, but better data is always better, emphasized Xavier Amatriain, VP of Engineering, Quora. Another argument presented by Amatriain is that adding more features (variables) doesn’t necessarily improve the accuracy of model.
Model Interpretability in Deep Learning & Machine Learning
A popular notion about machine learning models is the interpretability — statistical models like logistic regression yield interpretable models. Historically, financial sector which relies heavily on interpretability uses machine learning models because of its ability to offer an audit trail. On the other hand, neural networks are dubbed as the black boxes since there is no real understanding of how the output was achieved. In other words, one may not be able to ascertain how the exact model works inside and out, but know the learning algorithm that created it. However, according to Zachary Chase Lipton, a Ph.D student at UCSD, machine learning algorithms, for example decision trees, often championed for their interpretability, can also be similarly opaque. In case of decision tree, even with one tree, if it grows too large, it might cease to be interpretable, much like high-dimensional linear models, he emphasized in a post.
DL vs ML: Difference In Output
Besides, DL and ML also differ in their output – while ML models produce a numerical output, the output from DL algorithms can range from an image to text or even an audio. Besides, where DL scores over traditional machine learning techniques is with its neural network approach to look for patterns and correlations which improves significantly when it is fed more data to train. However, this doesn’t mean that traditional machine learning is dead. In fact, companies working with limited hardware and data work better with an ensemble of conventional machine learning methods instead of data-intensive DL models.
Future of Deep Learning
Deep Learning models are gaining currency over traditional machine learning models because of their breakthroughs in consumer-facing technology such as image recognition and face recognition in mobiles. Where machine learning models hit a ground in analytics performance due to data processing limitations, DL algorithms can work at scale and the recent hardware innovations have proven how deep learning training can be reduced dramatically to minutes. There is a lot more going on in deep learning research and DL is poised to make a major impact in areas such as driverless technology, retail, healthcare and its breakthroughs will significantly impact diagnostics.