The Incremental Forward Stagewise algorithm is a type of boosting algorithm for the linear regression problem. It uses a forward selection and backwards elimination algorithm to eliminate those features which are not useful in the learning process with this strategy it builds a simple and efficient algorithm based on linear regression. This algorithm is highly motivated by the LASSO regression. In this article, we are going to discuss the elimination technique and the Lasso algorithm to minimize the residual with an iterative approach. Following are the topics to be covered.
Table of contents
- Forward Selection and Backward Elimination Technique
- Forward Stagewise Regression
- Implementation in python
Let’s start with the understanding of the feature elimination technique used by Forward Stagewise Regression.
Forward Selection and Backward Elimination Technique
Forward selection is a variable selection method in which initially a model that contains no variables called the Null Model is built, then starts adding the most significant variables one after the other this process is continued until a pre-specified stopping rule must be reached or all the variables must be considered in the model.
Setting a stopping point needs a fixed threshold which is selected based on their p-value (which should be less than 0.05) or it is determined by using two criteria named Akaike Information Criterion and Bayesian information criterion. Similarly, the significance of each value is determined on the basis:
- It has the smallest p-value
- It provides the highest increase in prediction percentage (R2 score).
- It provides the largest drop in Residuals Sum of Squares (RSS) compared to other features considered.
Backward elimination is a variable selection method in which initially the model contains all variables under consideration known as the Full Model, then removes the least significant variables one after the another until the model meets a pre-specified stopping point or until no variable remains. The threshold is fixed with the same method used in the forward selection. The significance of variables is decided on the basis that:
- It has the highest p-value in the model
- It has the lowest drop in R2
- It provides the lowest increase in RSS when compared to other features.
Are you looking for for a complete repository of Python libraries used in data science, check out here.
When are they used?
The forward stepwise selection is used when the number of features is smaller than the sample size in the case of linear regression and the case of logistic regression, it is used when the number of events is greater than the number of features.
Backward selection is important when variables in a model are correlated; backward selection may force all the features to be included in the model, unlike the forward selection where none of them will be.
Forward Stagewise Regression
The Forward Stagewise Regression is a stepwise regression whose goal is to find a set of independent variables that significantly influence the dependent variable through a series of tests (e.g. F-tests, t-tests). This computation is achieved through iterations.
Forward Stepwise regression uses both Forward selection and Backward elimination which is either by trying out one independent variable at a time and calculating its statistically significant (p-value) for the learner or by including all potential independent variables in the model and eliminating those that are not statistically significant.
Let’s understand this concept with an example,
Consider we need to understand the effect of cholesterol on the human body and there are features like age, weight, fat percentage, BP, BMI, heart rate, smoking, etc. The model will use a bidirectional approach which is essentially a forward selection procedure that will be conducted that is building a null model but with the possibility of deleting a selected variable at each stage when there are correlations between variables as in the backward elimination.
Let’s implement this concept in python and observe the outcomes.
Implementation in python
First, we will build a statistical model and do a bidirectional elimination of the features and then use the significant features to build a Linear Regression model.
Import necessary libraries
import numpy as np import pandas as pd import statsmodels.api as sm from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error,r2_score
Read and pre-process the data
dfX_train=pd.read_csv("/content/drive/MyDrive/Datasets/X_train.csv")
dfX_test=pd.read_csv("/content/drive/MyDrive/Datasets/X_test.csv")
dfy_train=pd.read_csv("/content/drive/MyDrive/Datasets/y_train.csv")
dfy_test=pd.read_csv("/content/drive/MyDrive/Datasets/y_test.csv")
The data consists of 33 features with categorical and continuous variables. The data is related to student performance on different tests. The categorical variables need to be dummified before the learning process.
dfX_train_dum=pd.get_dummies(data=dfX_train,drop_first=True) dfX_test_dum=pd.get_dummies(data=dfX_test,drop_first=True)
Build statistical model:
x_columns=['StudentID', 'age', 'Medu', 'Fedu', 'traveltime', 'studytime',
'failures', 'famrel', 'freetime', 'goout', 'Dalc', 'Walc', 'health',
'absences', 'G1', 'G2', 'school_MS', 'sex_M', 'address_U',
'famsize_LE3', 'Pstatus_T', 'Mjob_health', 'Mjob_other',
'Mjob_services', 'Mjob_teacher', 'Fjob_health', 'Fjob_other',
'Fjob_services', 'Fjob_teacher', 'reason_home', 'reason_other',
'reason_reputation', 'guardian_mother', 'guardian_other',
'schoolsup_yes', 'famsup_yes', 'paid_yes', 'activities_yes',
'nursery_yes', 'higher_yes', 'internet_yes', 'romantic_yes']
def get_stats():
x = dfX_train_dum[x_columns]
results = sm.OLS(y_train, x).fit()
print(results.summary())
get_stats()
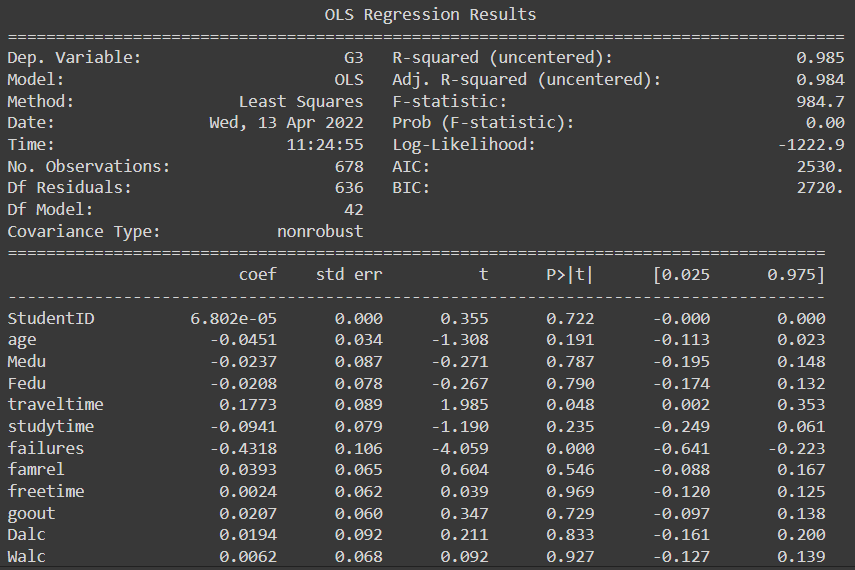
There are a total of 42 features created, out of which 15 features have a very high p-value and need to be removed.
x_columns.remove("age")
x_columns.remove("Medu")
x_columns.remove("Fedu")
x_columns.remove("freetime")
x_columns.remove("Dalc")
x_columns.remove("Walc")
x_columns.remove("health")
x_columns.remove("school_MS")
x_columns.remove("Mjob_other")
x_columns.remove("schoolsup_yes")
x_columns.remove("famrel")
x_columns.remove("goout")
x_columns.remove("higher_yes")
x_columns.remove("romantic_yes")
x_columns.remove("StudentID")
get_stats()

Now we are left with 27 features out of which a few features still have high value but we would first use these features to build a linear model and if the model performance needs an improvement then only we would remove those features.
Build Linear Regression
x = dfX_train_dum[x_columns]
lr = LinearRegression()
lr.fit(x, y_train)
x_test = dfX_test_dum[x_columns]
y_pred = lr.predict(x_test)
print("RMSE:",np.sqrt(mean_squared_error(dfy_test['G3'],y_pred)),"\nR2 score:",r2_score(dfy_test['G3'],y_pred))
RMSE: 1.7085538565926237 R2 score: 0.810166639435027
The regression learner is performing well with a lesser root mean squared error and a high R2 score. But it could be improved by removing those insignificant features, that is up to you.
Final Words
Incremental Forward Stagewise Regression is an algorithm that uses bidirectional elimination techniques to select the significant features according to the dependent feature so that the learner could predict with absolute accuracy. With a hands-on implementation of this concept in this article, we could understand Incremental Forward Stagewise Regression.