



When you open a large Dataset with Python’s Pandas and try to get a few metrics, the entire thing just stops badly. If you work with Big Data on a regular basis, you’re probably aware that if you’re using Pandas, a simple loading of a series for a couple of million rows can take up to a minute! In the industry, the term/technique parallel computing is used for this. In relation to parallel computing, we will cover parallel computing and the Dask library, which is preferred for such tasks in this article. We will also go through different machine learning features as well available with Dask. The following are the main points to be discussed.
Table of Contents
- What is Parallel Computing?
- Need of Dask
- What is Dask?
- Implementing Dask
- Dask DataFrame
- Dask ML
Let’s start by understanding parallel computing.
What is Parallel Computing?
Parallel computing is a sort of computation that performs several calculations or processes at the same time. Large problems are frequently broken into smaller ones that can be tackled simultaneously. Parallel computing can be divided into four types: bit-level, instruction-level, data, and task parallelism. Parallelism has long been used in high-performance computing, but it has recently gained traction due to physical limitations that restrict frequency growth.
The software divides the problem into smaller problems or subtasks as soon as it starts running. Each subtask is completed independently, with no outside intervention, and the results are then combined to produce the final output.

Parallel computing and concurrent computing are commonly confused and used interchangeably, but the two are distinct: parallelism can exist without concurrency (such as bit-level parallelism), and concurrency can exist without parallelism (such as multitasking by time-sharing on a single-core CPU). Computer work is often broken down into many, often many, extremely similar sub-tasks that may be executed individually and whose results are then pooled after completion in parallel computing.
Multi-core and multi-processor computers have many processing parts within a single system, whereas clusters, MPPs, and grids operate on the same task using multiple computers. For speeding specific activities, specialized parallel computer architectures are sometimes employed alongside regular CPUs.
Need of Dask
Numpy, pandas, sklearn, seaborn, and other Python libraries make data manipulation and machine learning jobs a breeze. The python [pandas] package is sufficient for most data analysis jobs. You can manipulate data in a variety of ways and use it to develop machine learning models.
However, as your data grows larger than the RAM available, pandas will become insufficient. This is a rather typical issue. To overcome this, you can utilize Spark or Hadoop. These aren’t, however, Python environments. This prevents you from utilizing NumPy, sklearn, pandas, TensorFlow, and other popular Python machine learning packages. Is there a way around this? Yes! This is where Dask enters the picture.
What is Dask?
Dask is a Python-based open-source and extensible parallel computing library. It’s a platform for developing distributed apps. It does not immediately load the data; instead, it just points to the data, and only the relevant data is used or displayed to the user. Dask can use more than a single-core processor and employs parallel computation, making it incredibly quick and efficient with large datasets. It prevents mistakes caused by memory overflow.
Dask uses multi-core CPUs to efficiently perform parallel computations on a single system. If you have a quad-core CPU, for example, Dask can effectively process all four cores of your system at the same time. Dask keeps the entire data on the disk and processes chunks of data (smaller parts rather than the entire data) from the disk in order to consume less memory during computations. To save memory, the intermediate values generated are deleted as quickly as possible during the procedure.
In short, Dask can process data efficiently on a cluster of machines because it uses all of the cores of the connected workstations. The fact that all machines do not have to have the same number of cores is a fascinating aspect. If one system has two cores and the other has four, Dask can tolerate the disparity in core count.
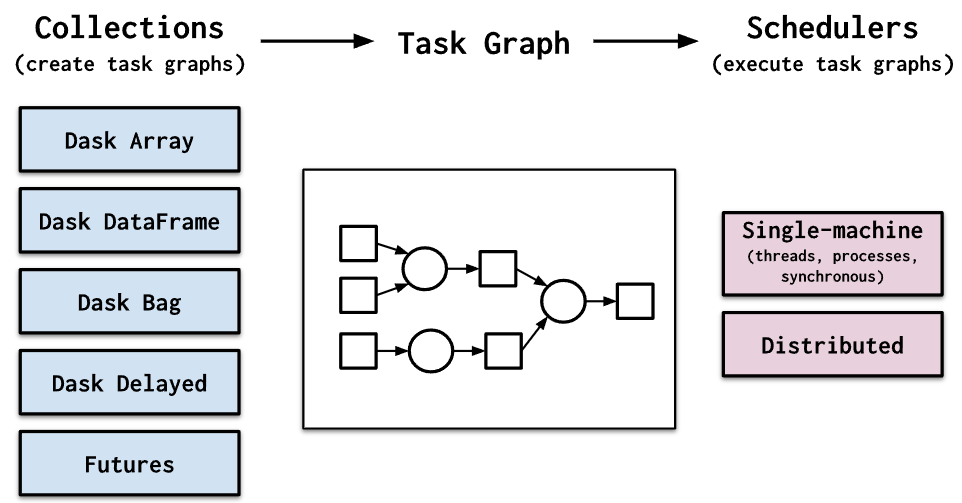
Dask has two task scheduler families:
- A single machine scheduler provides basic functionalities on a local process or thread pool. This scheduler was the first to be created and is the default. It is simple and inexpensive to use. It is limited to a single machine and does not scale.
- Distributed scheduler: This is a more advanced scheduler. It has more functions, but it takes a little more effort to set up. It can run on a single machine or be distributed across multiple machines in a cluster.
The following virtues are highlighted by Dask:
- Familiar: Parallelized NumPy array and Pandas DataFrame objects are familiar.
- Flexible: Offers a task scheduling interface for more customized workloads and project integration.
- Native: Provides access to the PyData stack and allows distributed computation in pure Python.
- Fast: Operates with little overhead, latency, and serialization, all of which are required for fast numerical computations.
- Scalable: Runs reliably on clusters with thousands of cores.
- Scales down: Simple to set up and run in a single process on a laptop.
- Responsive: It’s designed with interactive computing in mind, so it delivers quick feedback and diagnostics to help humans.
Implementing Dask
Before using the functionality of dask we need to install it. It can be simply installed using pip command as python –m pip install “dask[complete]” that will install all functionality of dask not just core functionality.
Dask offers a variety of user interfaces, each with its own set of distributed computing parallel algorithms. Arrays built with parallel NumPy, Dataframes built with parallel pandas, and machine learning with parallel scikit-learn is used by data science practitioners looking to scale NumPy, pandas, and scikit-learn.
Dask DataFrame
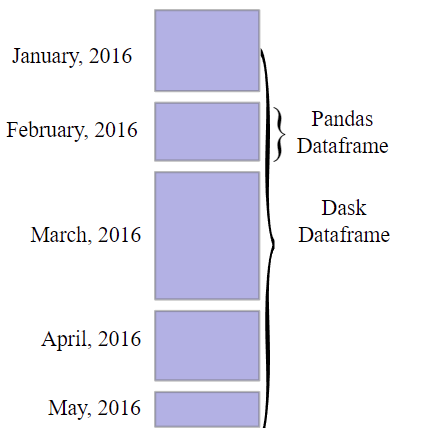
Dask DataFrames are made out of smaller pandas DataFrames. A huge pandas DataFrame divides into several smaller DataFrames row by row. These tiny DataFrames can be found on a single machine’s disk or numerous machines’ disks (thus allowing to store datasets of size larger than the memory). Each Dask DataFrame calculation parallelizes operations on existing pandas DataFrames.
The structure of a Dask DataFrame is depicted in the graphic below:
Now below we will compare the time taken by the pandas library and Dask to load a high sized CSV file will compare the result. CSV file contains the English to Hindi Truncated corpus which weighs around 35MB and has nearly 1,25,000 instances.
# loading file with pandas
import pandas as pd
%time data_1 = pd.read_csv('/content/drive/MyDrive/data/Hindi_English_Truncated_Corpus.csv')
Output

# loading the file using dask
import dask.dataframe as dd
%time data = dd.read_csv("/content/drive/MyDrive/data/Hindi_English_Truncated_Corpus.csv")
Output

As we can see that the loading speed of dask is much faster than that of pandas.
Dask ML
Dask ML delivers scalable machine learning techniques in Python that are scikit-learn compatible. First, we’ll look at how scikit-learn handles computations, and then we’ll look at how Dask handles similar operations differently. Although scikit-learn can do parallel computations, it cannot be scaled to several machines. Dask, on the other hand, performs well on a single machine and can be scaled up to a cluster.
Using Joblib, sklearn supports parallel processing (on a single CPU). To parallelize several sklearn estimators, you can utilize Dask directly by adding a few lines of code (without modifying the existing code).
Dask ML implements simple machine learning techniques that make use of Numpy arrays. To provide scalable algorithms, Dask substitutes NumPy arrays with Dask arrays. This has been implemented for the following purposes:
- Models that are linear (linear regression, logistic regression, Poisson regression)
- Processing in advance (scalers, transforms)
- Aggregation (k-means, spectral clustering)
And these can be implemented as below,
! pip install dask-ml # ML model from dask_ml.linear_model import LogisticRegression model = LogisticRegression() model.fit(data, labels) # Pre-processing from dask_ml.preprocessing import OneHotEncoder encoder = OneHotEncoder(sparse=True) result = encoder.fit(data) # Clustering from dask_ml.cluster import KMeans model = KMeans() model.fit(data)
Conclusion
Through this post, we have seen what is parallel computing in detail and why it is important when it comes to performing data-centric operations on high dimensional data or in short we can say by parallel computing the time required to perform certain operations on Big Data is significantly reduced as we have seen in the example above. Later we have seen the Dask library which can help us to perform operations on Big Data.
















