



Most of the object detection models aim to recognize all objects presented in the image of predefined categories. Wherein the results of the detected objects are shown through a set of bounding boxes and the class labels associated with the boxes or categories. With prior knowledge of the architecture and loss functions, these models are designed carefully and also some of them are customized with the same knowledge. For example, many of the models are made for using the bounding boxes and many others are modelled to use the object queries for object binding. In this article, we are going to see how a model named Pix2seq works with an approach of language modelling in object detection. The major points to be discussed in this article are listed below.
Table of Contents
- What is Pix2Seq?
- The Pix2Seq Framework
- Sequence Construction From Object Description
- Architecture and Objective
- Sequence Augmentation to Integrate Task Priors
- Altered Sequence Construction and Altered Inference
- Comparison With Other Models
What is Pix2Seq
Pix2seq is a new approach or model for object detection which is designed in intuition which states that if a neural network is already trained about the where and what the objects are. We just need to train the network to read them out. And by the time the model is learning how to describe the object, the model can also learn the language on the pixel observation, which can lead us to the representation of the objects. To follow this intuition the pix2seq produces the sequence of the tokens from the given image as input. T
These tokens are discrete so that they can lead to the object description reminiscent of an image captioning system. We can say the pix2seq model is a way to make an object detection system like a language modelling system which basically can be achieved by conditioning on the pixels. The architecture and the loss function of this model are relatively simple, we can also use this framework in solving problems of different domains.
As we have discussed in the upper part for object detection the pix2seq model produces the sequence of the tokens from the given image for this the model is having a quantization and serialization scheme. We can say the model is not engineered specifically for the detection task. Using the scheme it converts the bounding boxes and class labels in the discrete token and these tokens are arranged in a sequential way than using the sequential models’ encoder-decoder scheme it generates the target sequence from the pixel input. The maximum likelihood of sequenced tokens is the objective function of the model conditioned on the pixel values and next tokens. We don’t need prior knowledge about object detection because of the model’s architecture and the loss function because they are task-agnostic. In the model it alters the input and sequence while training.
The Pix2seq Framework
Since the pix2seq model is a way to cast the object detection task in terms of language modeling we can roughly divide the framework into 4 major components mentioned in the below image.
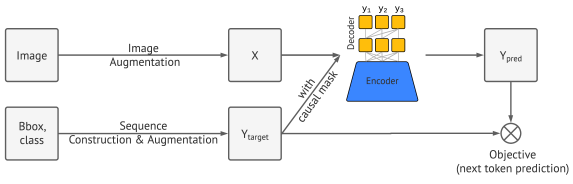
- Image augmentation – in the model pix2seq image augmentation task is performed by a common model. Since it is a basic procedure of any computer vision model the pix2seq uses augmented images to make a set of training examples rich with the data.
- Sequence construction and augmentation – labeling the object in any image are done by converting the pixels into a sequence of discrete tokens wherein comparison of other models they usually represent these labels of the object with a set of bounding boxes and class labels.
- Architecture – in the architecture component of the pix2seq model the model uses the encoder-decoder scheme of the; language modelling where the target sequence is generated by the pixel inputs encoded and received by the encoder.
- Objective function- we can consider it as the loss function tokens conditioned on the image and the next tokens maximum likelihood used for training of the model.
Sequence Construction From Object Description
The framework of pix2seq is designed as the result in the form of detected objects class label can be expressed as the sequence of discrete tokens. The model provides box bounding to the detected objects where the boundaries of the box are fixed at the top left, top right, bottom left, class index, and the bottom right corner of the object by using the discretizing continuous number which specifies the coordinates of the boundaries. By the above, we can say that the detected object is a representation of the sequence of the five tokens which are discretized. If [ymin, xmin, ymax, xmax, c] are the tokens for the boundary then these corner coordinates are discrete integers between [1,nbins], and c is the class index. The model uses a vocabulary for all tokens where the size of the vocabulary is equal to the addition of the number of bins and the number of classes. We can consider it as the quantization scheme for bounding boxes which helps in achieving high precision by using such a small vocabulary. Where traditional NLP models use very big vocabulary whose size can be around 32K or higher. These all procedures of the model can be explained by the below image.

Using the single sequence of any given image we can serialize the description for multiple objects. For this purpose, the model uses a random ordering strategy using the strategy whenever an image is shown to the model each time the model can randomize the object orders using the strategy. The generated sequence for the number of objects presented in any image can be of different lengths so the has an EOS token to indicate the end of a sequence. The below image is a representation of the sequence construction with different ordering strategies.

nbins = 10 nbins = 50
Architecture and Objective
The constructed sequence from the object description is used with such an architecture and objective or loss function which is already known in the domain NLP modelling for higher accuracy.
Architecture – the model uses an encoder-decoder architecture. Where the encoder encodes the perceived pixels into the hidden representation and the decoder generates one token at a time. The generation of the tokens is conditioned on the next tokens which are going to generate and on the image representation which is encoded by the encoder. The encoder can be a convolutional network or any transformer or it can also be the combination of both where the decoder is generally a transformer model which is mostly used in the domain of modern NLP modelling.
Objective – objective or the loss function in the framework is similar to the maximum likelihood loss used in the NLP modelling. Mathematically the formula of the Maximum likelihood function can be written as the following.
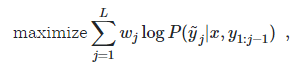
Where,
- X is the given image.
- y is associated input and ~y is the target sequence
- L is the largest sequence length
- w is preassigned weight
Sequence Augmentation to Integrate Task Priors
The termination of the generation in the model is decided by the above discussed EOF token. Generally, the model shows the error of not detecting all the objects presented in the image; this happens because of uncertainty in recognizing and localizing the objects of the image. To achieve a higher recall rate in the results the model uses a trick where it delays the EOS tokens sampling while the model is working. Delay in a sampling of EOS tokens is done by decreasing the likelihood. Minimizing the likelihood sometimes tends the model to predict noisy and duplicated predictions.
Because of the above trade-off, the pix2seq model is task agnostic. To resolve the above problem in the framework of the model a sequence augmentation technique is introduced with this technique the model augments the input sequence and trains itself for both real and synthetic tokens and also performs augmentation in the target sequence this leads the model to learn the noisy tokens rather than leaving them as it is. And this is how the model improves its prediction against noisy and duplicate predictions when the sampling of EOS is delayed. The below image is the representation of this procedure.

Altered Sequence Construction and Altered Inference
The above-given procedure leads to constructing synthetic noise objects which helps in augmenting the input sequence in two ways:
- Adding noise in the real objects
- Generate random boxes with randomly associated labels

The above-given image is the example of randomly generated boxes and the boxes generated on the real objects. This is how the model improves accuracy in object detection by altering the sequence construction.
Altering in the sequence allows us to make the EOS sampling delayed while improving the recall. Using these alterations allows the model to predict the maximum length of the object. The framework of the model extracts the list of the class labels from the generated sequence and replaces the noise class labels with the real labels which are having the maximum likelihood among all the classes.
Comparison With Other Models
The below table is the representation of different models and the Pix2seq model in terms of average precision over multiple object sizes and thresholds on the MS-COCO 2017 detection dataset.

In the comparison, we can see that the pix2seq model is giving competitive results to both Faster R-CNN and DERT models.
Final Words
In this article, we have seen how the Pix2seq model is helping us in the object detection task with a very new approach where it casts the object detection with the help of sequential model techniques. The sequential models are basically designed for the NLP task and the Pix2seq model is providing competitive results in object detection using the sequential modelling approach.
References














































































