



Traditional machine learning assumes that data points are dispersed independently and identically, however in many cases, such as with language, voice, and time-series data, one data item is dependent on those that come before or after it. Sequence data is another name for this type of information. In machine learning as well, a similar concept of sequencing is followed to learn for a sequence of data. In this post, we will understand what sequential machine learning is. We will also go through how the sequential data is used for modelling purposes and the different models used in sequential machine learning. The major points to be covered in this article are listed below.
Table of Contents
- What is the Sequential Model?
- Understanding Sequential Modeling
- What is Sequential Data?
- Different Sequential Models
- RNN and its variants
- Autoencoders
- Seq2Seq
Let’s start the discussion with the sequential model.
What is The Sequential Learning?
Machine learning models that input or output data sequences are known as sequence models. Text streams, audio clips, video clips, time-series data, and other types of sequential data are examples of sequential data. Recurrent Neural Networks (RNNs) are a well-known method in sequence models.
The analysis of sequential data such as text sentences, time-series, and other discrete sequence data prompted the development of Sequence Models. These models are better suited to handle sequential data, whereas Convolutional Neural Networks are better suited to treat spatial data.
The crucial element to remember about sequence models is that the data we’re working with are no longer independently and identically distributed (i.i.d.) samples, and the data are reliant on one another due to their sequential order. For speech recognition, voice recognition, time series prediction, and natural language processing, sequence models are particularly popular.
Understanding Sequential Modelling
Simply described, sequence modelling is the process of producing a sequence of values from a set of input values. These input values could be time-series data, which shows how a certain variable, such as demand for a given product, changes over time. The production may be a forecast of demand for future times.
Another example is text prediction, in which the sequence modelling algorithm predicts the next word based on the sequence of the previous phrase and a set of pre-loaded conditions and rules. Businesses may achieve more than just pattern production and prediction by employing sequence modelling.
What is Sequential Data?
When the points in the dataset are dependent on the other points in the dataset, the data is termed sequential. A Timeseries is a common example of this, with each point reflecting an observation at a certain point in time, such as a stock price or sensor data. Sequences, DNA sequences, and meteorological data are examples of sequential data.
In other words sequential we can term video data, audio data, and images up to some extent as sequential data. Below are a few basic examples of sequential data.
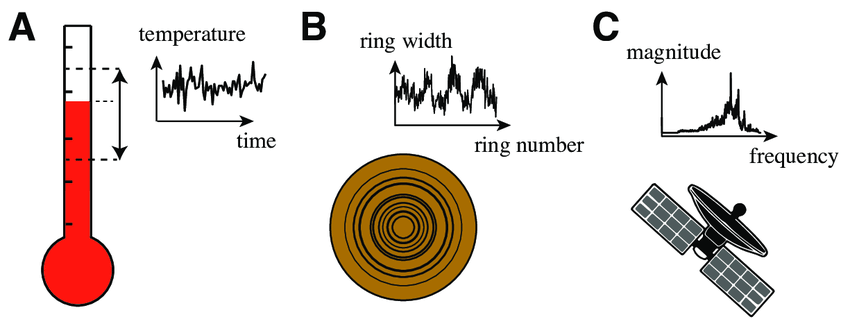
Below I have listed some popular machine learning applications that are based on sequential data,
- Time Series: a challenge of predicting time series, such as stock market projections.
- Text mining and sentiment analysis are two examples of natural language processing (e.g., Learning word vectors for sentiment analysis)
- Machine Translation: Given a single language input, sequence models are used to translate the input into several languages. Here’s a recent poll.
- Image captioning is assessing the current action and creating a caption for the image.
- Deep Recurrent Neural Network for Speech Recognition Deep Recurrent Neural Network for Speech Recognition
- Recurrent neural networks are being used to create classical music.
- Recurrent Neural Network for Predicting Transcription Factor Binding Sites based on DNA Sequence Analysis
In order to efficiently model with this data or to get as much information, it contains a traditional machine algorithm that will not help as much. To deal with such data there are some sequential models available and you might have heard some of those.
Different Sequential Model
RNN and its Variants Based Models
RNN stands for Recurrent Neural Network and is a Deep Learning and Artificial Neural Network design that is suited for sequential data processing. In Natural Language Processing, RNNs are frequently used (NLP). Because RNNs have internal memory, they are especially useful for machine learning applications that need sequential input. Time series data can also be forecasted using RNNs.
The key benefit of employing RNNs instead of conventional neural networks is that the characteristics (weights) in standard neural networks are not shared. In RNN, weights are shared over time. RNNs can recall their prior inputs, whereas Standard Neural Networks cannot. For computation, RNN uses historical data.
A different task that can be achieved using RNN areas,
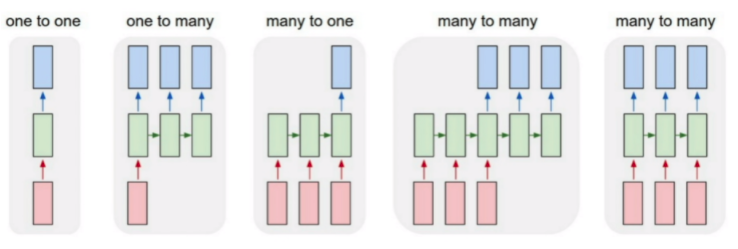
One-to-one
With one input and one output, this is the classic feed-forward neural network architecture.
One-to-many
This is referred to as image captioning. We have one fixed-size image as input, and the output can be words or phrases of varying lengths.
Many-to-one
This is used to categorize emotions. A succession of words or even paragraphs of words is anticipated as input. The result can be a continuous-valued regression output that represents the likelihood of having a favourable attitude.
Many-to-many
This paradigm is suitable for machine translation, such as that seen on Google Translate. The input could be a variable-length English sentence, and the output could be a variable-length English sentence in a different language. On a frame-by-frame basis, the last many to many models can be utilized for video classification.
Traditional RNNs, as you may know, aren’t very excellent at capturing long-range dependencies. This is primarily related to the problem of vanishing gradients. Gradients or derivatives diminish exponentially as they move down the layers while training very deep networks. The problem is referred to as the Vanishing Gradient Problem.
To tackle the vanishing gradient the LSTM was introduced as its name derives from the problem.
The RNN hidden layer is modified with LSTM. RNNs can remember their inputs for a long time thanks to LSTM. In LSTM, a cell state is transferred to the next time step in addition to the concealed state.

Long-range dependencies can be captured via LSTM. It has the ability to remember prior inputs for long periods of time. An LSTM cell has three gates. These gates are used in LSTM to manipulate memory. The gradient propagation in the memory of a recurrent network is controlled by gates in long short-term memory (LSTM).
For sequence models, LSTM is a common deep learning technique. The LSTM algorithm is employed in real-world applications such as Apple’s Siri and Google’s voice search, and it is responsible for their success.
Auto-Encoders
One of the most active study areas in Natural Language Processing is machine translation (MT) (NLP). The goal is to create a computer program that can quickly and accurately translate a text from one language (source) into another language (target) (the target) The encoder-decoder model is the fundamental architecture utilized for MT using the neural network model:
- The encoder section summarizes the data in the source sentence.
- Based on the encoding, the decoder component generates the target-language output in a step-by-step manner.
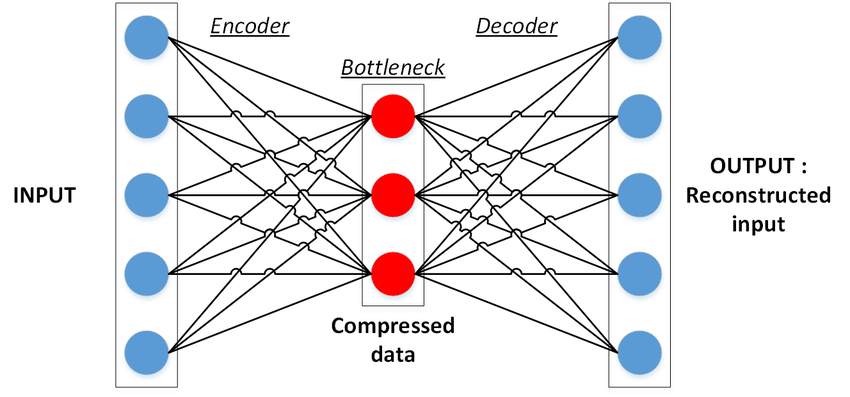
Basic Structure of Single-layer Autoencoder
The performance of the encoder-decoder network diminishes significantly as the length of the input sentence increases, which is a limitation of these approaches. The fundamental disadvantage of the earlier methods is that the encoded vector must capture the full phrase (sentence), which means that much critical information may be missed.
Furthermore, the data must “flow” through a number of RNN steps, which is challenging for large sentences. Bahdanau et al. presented an attention layer that consists of attention mechanisms that give greater weight to some of the input words than others while translating the sentence and this gave further boost in machine translation applications.
Seq2Seq
Seq2seq takes a sequence of words (sentences or sentences) as input and produces a sequence of words as output. It accomplishes this through the usage of a recurrent neural network (RNN). Although the basic RNN is rarely used, its more complex variants, such as LSTM or GRU, are. In Google’s planned version, LSTM is used.
By taking two inputs at each moment in time, it constructs the context of the word. The name recurrent comes from the fact that it receives two inputs, one from the user and the other from the previous output (output goes as input).
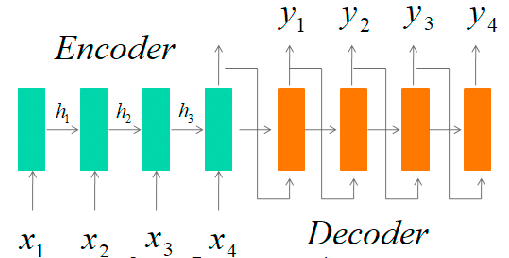
It is sometimes referred to as the Encoder-Decoder Network since it primarily consists of two components: an encoder and a decoder.
Encoder: It translates input words to corresponding hidden vectors using deep neural network layers. Each vector represents the current word as well as its context.
Decoder: It uses the encoder’s hidden vector, its own hidden states, and the current word as input to construct the next hidden vector and forecast the next word.
Final Words
By going through these discussed techniques one might confuse between seq2seq and Autoencoder. The input and output domain of the seq2seq model is different like (English-Hindi) and used mostly in machine translation applications. Whereas the Autoencoder is a special case of the seq2seq model where both input and output domain are the same (English-English), it behaves like auto-association means it perfectly recalls or rebuilds the input sequence if we pass a corrupted sequence. Features like this have leveraged autoencoder in many applications like pattern compilation etc.
Through this post, we have seen what is a sequential model is. In which we have discussed more fundamental concepts of sequential models and sequential data. In short, we can say data to be sequential if it is anyhow associated with time or its instances are dependent. To deal with such data traditional ML algorithms are not much useful for that need to deal with special cases of Deep Learning technique as we have discussed.












































































