



|
Listen to this story
|
PyTorch Lighting is one of the frameworks of PyTorch that is extensively used for AI-based research. The PyTorch Lightning framework has the ability to adapt to model network architectures and complex models. Pytroch lightning would majorly be used by AI researchers and Machine Learning Engineers due to scalability and maximized performance of the models. This framework has many features, and in this article, let us look into how to use PyTorch Lighting to train a model on multiple GPUs.
Table of Contents
- Introduction to PyTorch Lightning
- Benefits of PyTorch Lightning
- Benefits of using Multi GPU training
- Training with Multiple GPUs using PyTorch Lightning
- Summary
Introduction to PyTorch Lightning
PyTorch Lighting is one of the wrapper frameworks of PyTorch, which is used to scale up the training process of complex models. The framework supports various functionalities but lets us focus on the training model on multiple GPU functionality. PyTorch lighting framework accelerates the research process and decouples actual modelling from engineering.
Heavy PyTorch models can be accelerated using the PyTorch lighting framework, and training heavy PyTorch models on fewer accelerator platforms can be time-consuming. The PyTorch lightning framework basically follows a common workflow for its operation. The workflow of PyTorch is as given below.
- The workflow gets instantiated when the model architecture is instantiated in the working environment. The PyTorch script involving the pipelines, training and testing evaluation, and all other parameters used for the model will also get instantiated in the framework.
- The pipeline used for the model or the network will get organized according to PyTorch Lightning standards. Now the DataModule of the framework will reorganize the pipeline in a usable format.
- Now the trainer instance can be instantiated in the working environment. The trainer instance can be manifested according to the accelerators present in the working environment.
The PyTorch Lightning framework has the ability to integrate with various optimizers and complex models like Transformers and help AI researchers to accelerate their research tasks. The framework can also be integrated on cloud-based platforms and also with some of the effective training techniques of models like SOTA. The framework also has the flexibility to enforce standard functionalities for complex models like Early Stopping, which terminates the model training when there are no improvements in the performance of the models after a certain threshold. Pretrained models (transfer learning) models can also be made available in the framework to induce learning of other models. In the next section of this article, let us look into some of the benefits of using PyTorch lightning.
Benefits of PyTorch Lightning
Some of the benefits of using PyTorch Lightning are mentioned below.
- PyTorch lightning models are basically hardware agnostic. This makes the models to be trained either on resources with Single GPUs or multiple GPUs.
- PyTorch lightning offers the execution of models on various platforms. For executing lightning models in environments like Google Colab or Jupyter there is a separate lightning trainer instance.
- Lightning models are easily interpretable and highly reproducible across various platforms, which increases the lightning models’ usage.
- Higher flexibility and ability to adapt to various devices and high-end resources.
- Parallel training is supported by lightning models along with the sharding of multiple GPUs to make the training process faster.
- Quicker model convergence and the ability to integrate with TensorBoard facilitate faster model convergence and make model evaluation easier.
Benefits of using Multi GPU training
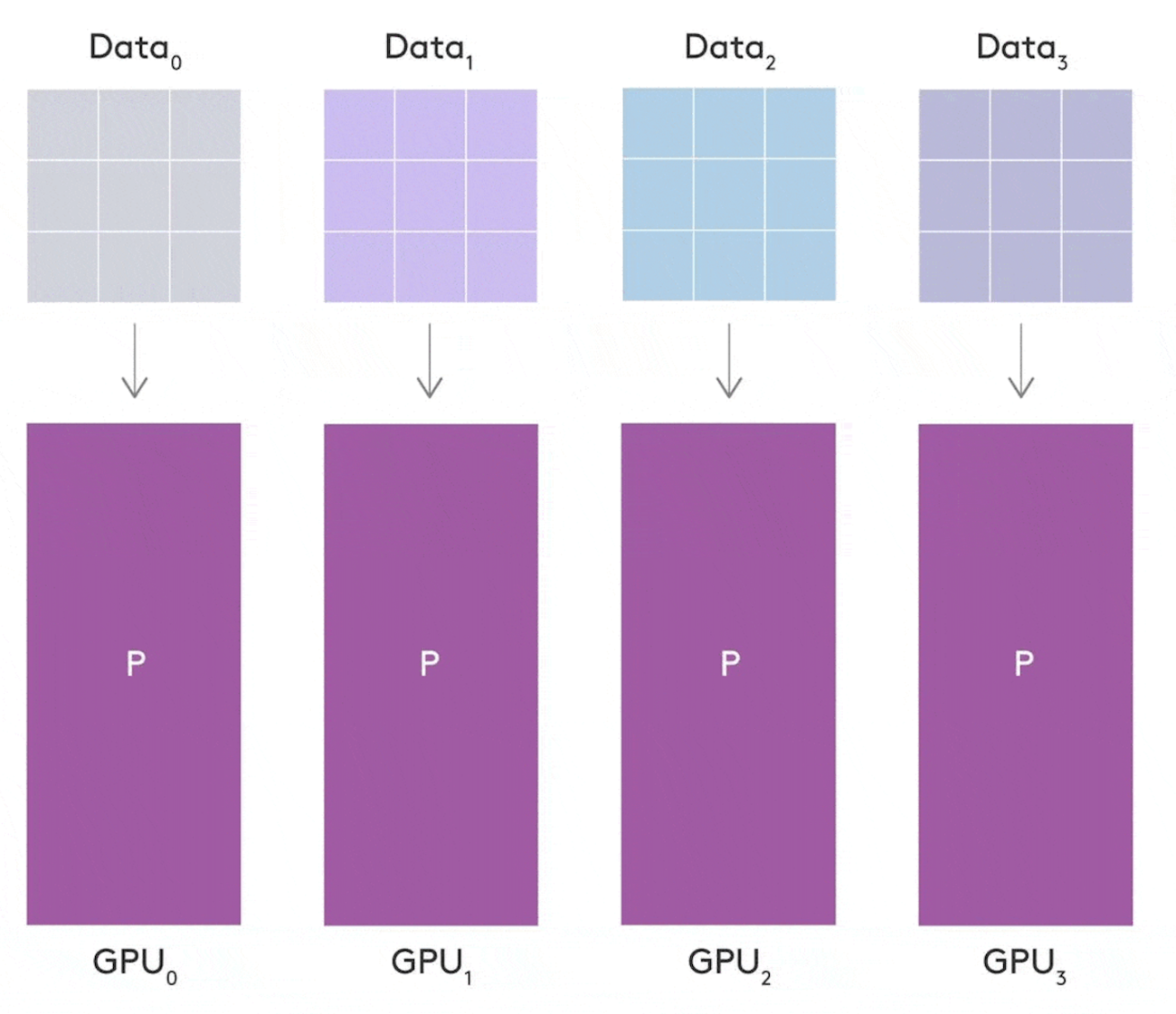
Larger models basically involve training with larger batch sizes and larger dimensions of data. Partitioning of this data becomes necessary to reduce the peak memory usage of accelerators like GPUs. Using multiple GPUs, parallel processing can be employed which reduces the overall time spent on model training. Sometimes hard memory-saving configurations will affect the speed of training but that can be handled efficiently by using multiple GPUs.
Usage of multiple GPUs also facilitates sharding which in turn accelerates the training process. Lightning models offer an instance or strategy to use Multiple GPUs in the working environment by using an instance named DistributedDataParallel. The total trainable model size and the batch size will not change with respect to the number of GPUs but lightning models have the ability to automatically apply certain strategies for optimal batches of data to be shared across GPUs mentioned in the trainer instances.
As mentioned earlier multiple GPUs also facilitate sharded training which is very much beneficial for faster training. Sharded training has various benefits such as reduction in peak memory usage, reduction in larger batch sizes of data on single accelerators, linear scaling of models, and many more.
Training with Multiple GPUs using PyTorch Lightning
Multiple GPU training can be taken up by using PyTorch Lightning as strategic instances. There are basically four types of instances of PyTorch that can be used to employ Multiple GPU-based training. Let us interpret the functionalities of each of the instances.
Data Parallel (DP)
Data Parallel is responsible for splitting up the data into sub batches for multiple GPUs. Consider that there is a batch size of 64 and there are 4 GPUs responsible for processing the data. So there will be 12 samples of the data for each GPU to be processed. To make use of the Data Parallel, we must specify it in the trainer instance as mentioned below.
trainer = Trainer(accelerator="gpu", devices=2, strategy="dp")
Here dp is the parameter that has to be used in the working environment to make use of the Data Parallel instance and the root node will aggregate the weights together after the final backward propagation.
Distributed Data-Parallel (DDP)
Each GPU in the DDP will have a separate node for processing. Each subset of data can be accessed by multiple GPUs over the overall dataset. Gradients are synced from the Multiple GPUs and the model-trained parameters can be taken up for further evaluation.
trainer = Trainer(accelerator="gpu", devices=8, strategy="ddp")
Here ddp is the parameter that has to be used in the working environment to make use of the Distributed Data-Parallel instance and the root node will aggregate the weights together after the final backward propagation.
There are other strategies as well that will be used with DDP known as DDP-2 and Spawn. The overall operating characteristics of these two strategies of DDP are similar but the difference can be seen in the weight update process. The split of the data and the training instantiation process would vary from the original DDP.
trainer = Trainer(accelerator="gpu", devices=8, strategy="ddp2") ## DDP-2 trainer = Trainer(accelerator="gpu", devices=8, strategy="ddp_spawn") ## DDP-Spawn
Horovod Multiple GPU training

Horovod is the framework for using the same script of training across multiple GPUs. Unlike DDP each subset of data will be provided for multiple GPUs for faster processing. Each of the GPU servers in the architecture will be configured by driver applications.
So PyTorch Lightning models can be configured by using the Hovord architecture as shown in the below code.
trainer = Trainer(strategy="horovod", accelerator="gpu", devices=1)
Bagua
Bagua is one of the frameworks of deep learning that is used to accelerate the training process and extend support for using distributed training algorithms. Among some of the distributed training algorithms, Bagua makes use of the GradeintAllReduce. This algorithm is basically used to establish communication between synchronous devices and the gradients will be averaged among all workers.
Below is a sample code to use the Bagua algorithm with the GradientAllReduce algorithm in the working environment.
trainer = Trainer(strategy=BaguaStrategy(algorithm="gradient_allreduce"),accelerator="gpu",devices=2)
Using Multiple GPUs for training will not only accelerate the training process but also will reduce the wall time of the models significantly. So the required strategy of PyTorch Lightning can be used accordingly for utilizing Multiple GPUs and training the data using PyTorch Lightning.
Summary
PyTorch Lightning is one of the frameworks of PyTorch with extensive abilities and benefits to simplify complex models. Among the various functionalities of PyTorch Lightning in this article, we saw how to train a model on multiple GPUs for faster training. It basically uses some strategies to split the data based on batch sizes and transfer that data across multiple GPUs. This enables complex models and data to be trained in a shorter duration time and also helps to accelerate the research work of AI researchers and ML Engineers.













































































