



|
Listen to this story
|
AssemblyAI, the company focused on building speech, voice, and text models, announced Conformer-1, its latest state-of-the-art speech recognition model. Built on the Conformer architecture and undergoing training on 650K hours of audio data, this model attains an accuracy level comparable to that of a human, demonstrating a reduction of up to 43% in errors when processing noisy data in comparison to alternative ASR models.
To improve on the Conformer architecture, the company leveraged Efficient Conformer, a modification on the original architecture that uses progressive downsampling which is inspired by ContextNet and also used Group Attention. These changes speedup the inference time by 29% and 36% training time.
Click here to learn more about Conformer-1.
AssemblyAI took inspiration from DeepMind’s data scaling laws in the Chinchilla paper and adapted into the ASR domain, curated 650k hours of English audio, making it the largest trained supervised model.
To overcome one of the biggest problems in speech recognition, the noise, the team also implemented a modified version of spare attention. It is a pruning method for attaining sparsity of the model’s weight for achieving regularisation. This is one of the greatest achievements of the model — its robustness to noise.
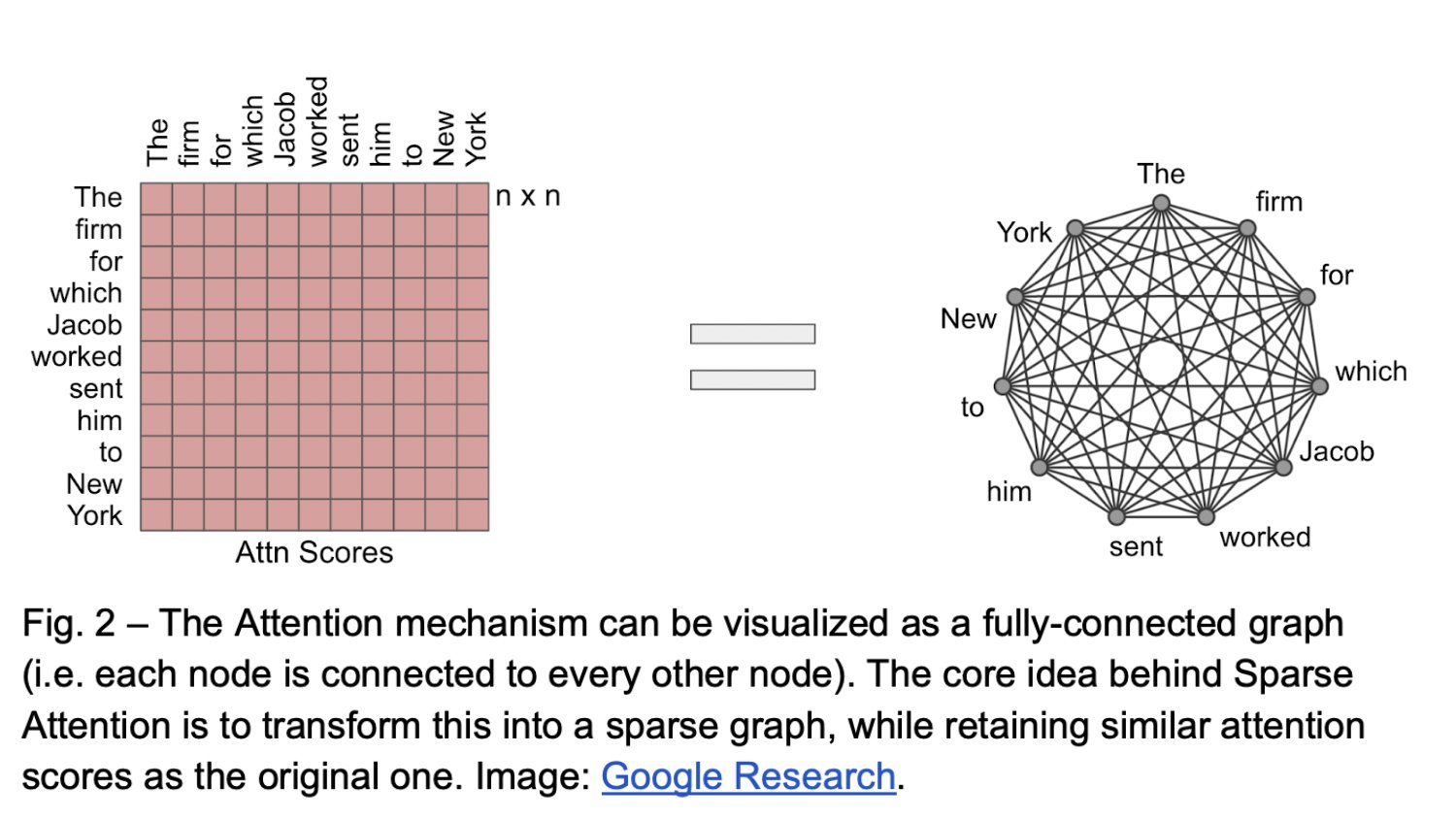
In 2020, Google Brain released the Conformer, a neural network designed for speech recognition. It is based on the Transformer architecture, which is widely used and known for its attention mechanism and parallel processing capabilities. The Conformer architecture enhances the Transformer by incorporating convolutional layers, allowing it to effectively capture both local and global dependencies, while remaining a compact neural network design.













































































