
Easiest Way To Scrape Data Without Coding Skills Using Octoparse
Here we will cover the detailed explanation of the working of Octoparse to extract data from a particular website.


Here we will cover the detailed explanation of the working of Octoparse to extract data from a particular website.

Web Scraping is a procedure to extract information from sites. This can be done with the assistance of web scraping programming known as web scrapers. They consequently load and concentrate information from the sites dependent on client prerequisites.Scrapy is an open-source web crawling system, written in Python. Initially intended for web scratching, it can likewise be utilised to separate information utilising APIs or as a universally useful web crawler.

With the expanding prominence of blogging sites, a massive number of clients share reviews on various parts of life consistently. Therefore popular sites like Amazon, Twitter are rich wellsprings of information for opinion mining and sentiment analysis.Sentiment analysis is a technique in natural language processing that deals with the order of assessments communicated in a bit of text.

Textual entailment is a technique in natural language processing that endeavors to perceive whether one sentence can be inferred from another sentence. A pair of sentences are categorized into one of three categories: positive or negative or neutral.

Questions Classification assumes a significant part in question answering systems, with one of the most important steps in the enhancement of the classification process being the identification of question types. The main aim of question classification is to anticipate the substance kind of the appropriate response of a natural language processing. Question order is regularly done using machine learning procedures.

Question Answering is a technique inside the fields of natural language processing, which is concerned about building frameworks that consequently answer addresses presented by people in a natural language processing.

In Artificial Intelligence, Sequence Tagging is a sort of pattern recognition task that includes the algorithmic task of a categorical tag to every individual from a grouping of observed values. It consists of various sequence labeling tasks: Part-of-speech (POS) tagging, Named Entity Recognition (NER), and Chunking.

With the advancement of machine translation, there is a recent movement towards large-scale empirical techniques that have prompted exceptionally massive enhancements in translation quality. Machine Translation is the technique of consequently changing over one characteristic language into another, saving the importance of the info text.

In recent times, Language Modelling has gained momentum in the field of Natural Language Processing. So, it is essential for us to think of new models and strategies for quicker and better preparation of language models. Nonetheless, because of the complexity of language, we have to deal with some of the problems in the dataset. With an increase in the size of the dataset, there is an increase in the normal number of times a word shows up in that dataset.

Internet Movie Database (IMDb) is an online information base committed to a wide range of data about a wide scope of film substance, for example, movies, TV and web-based streaming shows, etc. The IMDb dataset contains 50,000 surveys, permitting close to 30 audits for each film.

Moment in Time is one of the biggest human-commented video datasets catching visual and discernible short occasions created by people, creatures, articles and nature. It was developed in 2018 by the researchers: Mathew Monfort, Alex Andonian, Bolei Zhou and Kandan Ramakrishnan. The dataset comprises more than 1,000,000 3-second recordings relating to 339 unique action words

HMDB-51 is an activity video information dataset with 51 activity classifications, which altogether contain around 7,000 physically clarified cuts separated from an assortment of sources going from digitized motion pictures to YouTube.

ActivityNet is an enormous dataset that covers exercises that are generally pertinent to how people invest their energy in their everyday living. It was developed in 2015 by the researchers: Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanemand Juan Carlos Niebles1. ActivityNet gives tests from 203 movement classes with a normal of 137 untrimmed recordings per class and 1.41 movement occurrences per video, for an aggregate of 849 video hours.

Kinetics datasets are taken from Youtube recordings. The activities are human focussed and cover a wide scope of classes including human-object communications, for example mowing lawn, washing dishes, humans Actions e.g. drawing, drinking, laughing, pumping fist; human-human interactions, e.g. hugging, kissing, shaking hands.

UCF-101 dataset has 101 actions and 13320 clips of human actions, collected from youtube were first introduced in 2012 by researchers: Khurram Soomro, Amir Roshan Zamir and Mubarak Shah of Center for Research in Computer Vision, Orlando, FL 32816, USA. The clips in the action class are divided into 25 groups. Each group contains 4-7 clips. Clips in each group share some common features like background or actor.

The Kaplan–Meier estimator is an estimator used in survival analysis by using the lifetime data. In medical research, it is frequently used to gauge the part of patients living for a specific measure of time after treatment.

Neural Network uses optimising strategies like stochastic gradient descent to minimize the error in the algorithm. The way we actually compute this error is by using a Loss Function. It is used to quantify how good or bad the model is performing. These are divided into two categories i.e.Regression loss and Classification Loss.

LSTM autoencoder is an encoder that makes use of LSTM encoder-decoder architecture to compress data using an encoder and decode it to retain original structure using a decoder.
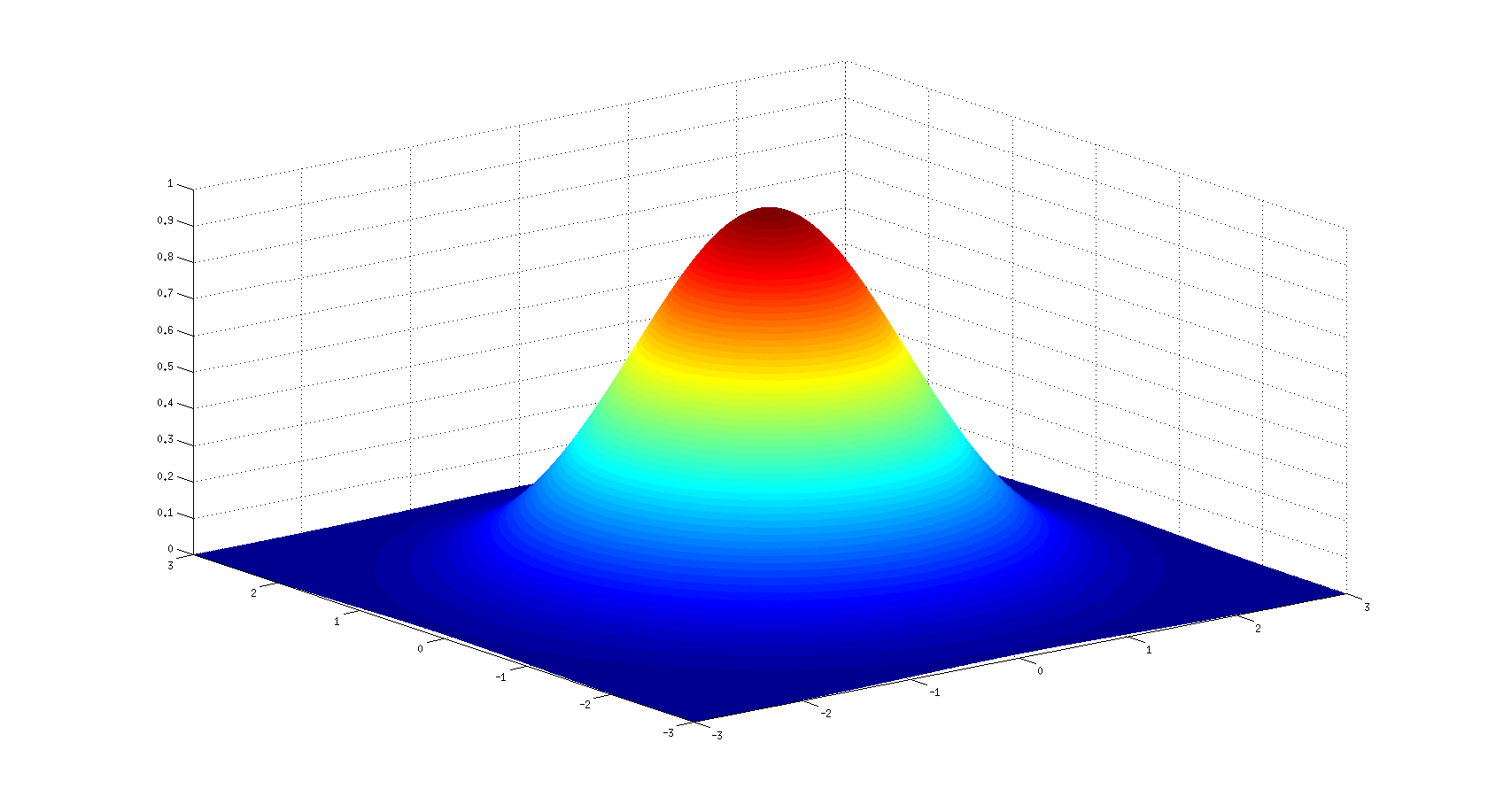
In recent times, there has been a lot of emphasis on Unsupervised learning. Studies like customer segmentation, pattern recognition has been a widespread example of this which in simple terms we can refer to as Clustering. We used to solve our problem using a basic algorithm like K-means or Hierarchical Clustering. With the introduction of Gaussian mixture modelling clustering data points have become simpler as they can handle even oblong clusters. It works in the same principle as K-means but has some of the advantages over it.

Language modelling is the speciality of deciding the likelihood of a succession of words. These are useful in many different Natural Language Processing applications like Machine translator, Speech recognition, Optical character recognition and many more.In recent times language models depend on neural networks, they anticipate precisely a word in a sentence dependent on encompassing words. However, in this project, we will discuss the most classic of language models: the n-gram models.

Recommendation systems expect to foresee clients’ inclinations and predict the most likely product that the users are most likely to purchase and are of interest to them.

Information Extraction is a process of extracting information in a more structured way i.e., the information which is machine-understandable. It consists of subfields which cannot be easily solved. Therefore, an approach to store data in a structured manner is Knowledge Graph which is a set of three-item sets called Triple where the set combines a subject, a predicate and an object.

Machine learning algorithms may take a lot of time working with large datasets. To overcome this a new dimensional reduction technique was introduced. If the input dimension is high Principal Component Algorithm can be used to speed up our machines.
Do you realize you can google up anything today and can be sure to find something related to it on the internet? This comes from

This article is an attempt to check under what condition we can go for a Z -Test or a T-Test. We will further implement these tests in python.

The vocabulary helps in pre-processing of corpus text which acts as a classification and also a storage location for the processed corpus text. Once a text has been processed, any relevant metadata can be collected and stored.In this article, we will discuss the implementation of vocabulary builder in python for storing processed text data that can be used in future for NLP tasks.

In the real world, the size of datasets is huge which comes as a challenge for every data science programmer. Working on it takes a lot of time, so there is a need for a technique that can increase the algorithm’s speed. Most of us are familiar with the term parallelization that allows for the distribution of work across all available CPU cores. Python offers two built-in libraries for this process, multiprocessing and multithreading.

XGBoost is developed on the framework of Gradient Boosting.

In real-world, training and model prediction is one phase of the machine learning life-cycle. But it won’t be helpful to anyone other than the developer as no one will understand it. So, we need to create a frontend graphical tool that users can see on their machine. The easiest way of doing it is by deploying the model using Flask.
In this article, we will discuss how to use flask for the development of our web applications. Further, we will deploy the model on google platform environment.
In this era, Short message service or SMS is considered one of the most powerful means of communication. As the dependence on mobile devices has drastically increased over the period of time it has led to an increased number of attacks in the form of SMS Spam.The main aim of this article is to understand how to build an SMS spam detection model. We will build a binary classification model to detect whether a text message is spam or not.

Join the forefront of data innovation at the Data Engineering Summit 2024, where industry leaders redefine technology’s future.