



Machine learning models which are deployed for vision and in natural language processing (NLP) tasks usually have more than one billion parameters. This allows for better results as the model generalises over a large wide range of parameters.
Pre-trained language representations such as ELMo, OpenAI GPT, BERT, ERNIE 1.0 and XLNet have been proven to be effective for improving the performance of various natural language understanding tasks. Pre-training binarised prediction models help us understand common NLP tasks like Question Answering or Natural language Inference.
Bidirectional Encoder Representations from Transformers or BERT, which was open sourced late 2018, offered a new ground to embattle the intricacies involved in understanding the language models.
BERT boasts of training any question answering model under 30 minutes. Given the number of steps BERT operates on, this is quite remarkable.
However, BERT contains artificial symbols like [MASK], which result in discrepancies during pre-training. In comparison, AR language modelling does not rely on any input corruption and does not suffer from this issue.
AR language modelling and BERT possess their unique advantages over the other. And XLNet was a by-product of the search for a pre-training objective that brings the advantages of both while avoiding their flaws.
As a generalised AR language model, XLNet does not rely on data corruption. Hence, XLNet does not suffer from the pre-train-finetune discrepancy that BERT is subject to.
Going Beyond BERT And XLNet
BERT constructed a bidirectional language model task and the next sentence prediction task to capture the co-occurrence information of words and sentences; XLNet constructed a permutation language model task to capture the co-occurrence information of words.
However, besides co-occurrence, the researchers at Baidu believe that there are other valuable lexical, syntactic and semantic information in training corpora. For example, named entities, such as names, locations and organisations, could contain conceptual information.
The authors in their paper, explore whether it would it be possible to further improve performance if the model was trained to constantly learn a larger variety of tasks.
They address the same by introducing ERNIE 2.0 (Enhanced Representation through kNowledge IntEgration)
ERNIE 2.0 is a continual pre-training framework. Continual learning aims to train the model with several tasks in sequence so that it remembers the previously learned tasks when learning the new ones.
What ERNIE 2.0 Has To Offer
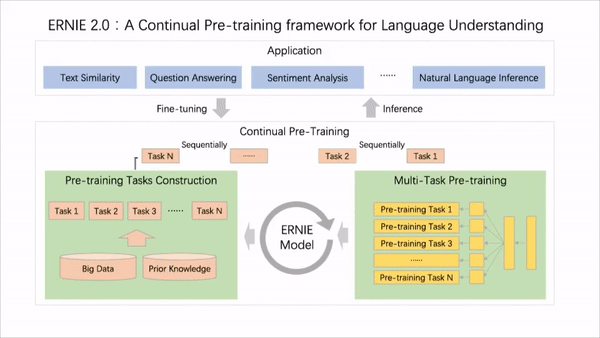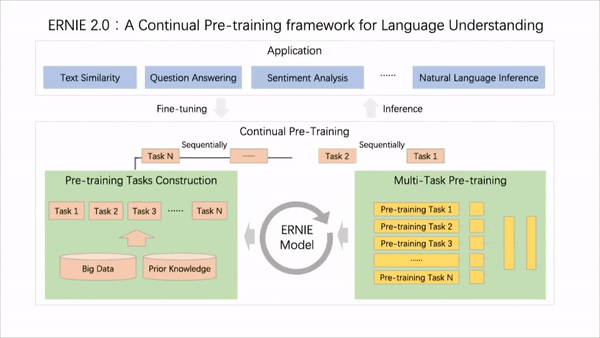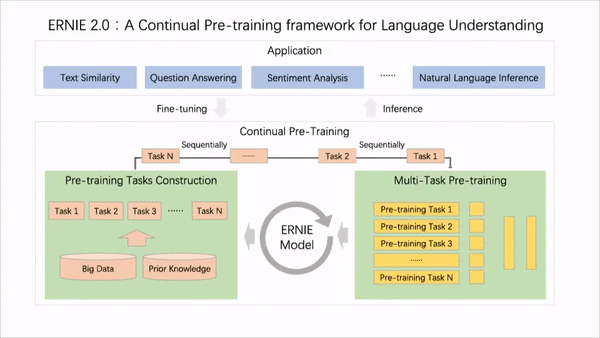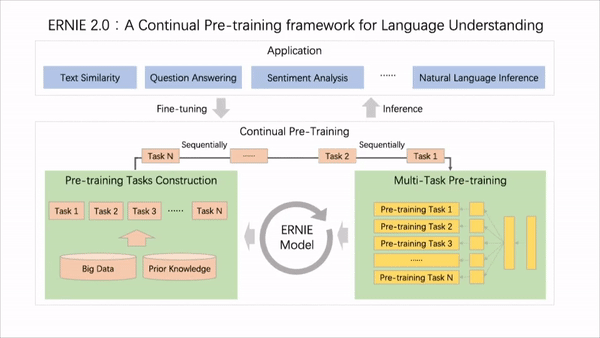
As shown in the above figure, the architecture of continual pre-training contains a series of shared text encoding layers to encode contextual information, which can be customised by using recurrent neural networks or a deep Transformer consisting of stacked self-attention layers. The parameters of the encoder can be updated across all pre-training tasks.
This framework by Baidu differs from traditional pre-training methods in that, instead of training with a small number of pre-training objectives, it could constantly introduce a large variety of pre-training tasks to help the model efficiently learn language representations.
To compare with BERT, the researchers used the same model settings of a transformer as BERT.
The base model contains 12 layers, 12 self-attention heads and 768-dimensional of hidden size while the large model contains 24 layers, 16 self-attention heads and 1024-dimensional of hidden size. The model settings of XLNet are the same as BERT.
ERNIE 2.0 is trained on 48 NVidia v100 GPU cards for the base model and 64 NVidia v100 GPU cards for the large model in both English and Chinese.

NLP: AI’s Need Of The Hour
The way these top organisations competing to top the NLP charts hints at the utmost need for improvement in the natural language understanding tasks while also shows how difficult it is to set new benchmarks which are significant. This can be clearly seen in the difference in scores between the top frameworks. The numbers may look close but every minor improvement in an NLP framework is considered gold given these model’s reputation for being computation heavy.
Improvements such as ERNIE are a great addition to the world of machine learning, especially to the NLP community.
ERNIE 2.0’s features can be summarised as follows:
- In this framework, different customised tasks can be incrementally introduced at any time and are trained through multi-task learning.
- This framework can incrementally train the distributed representations without forgetting the parameters of previous tasks.
- ERNIE 2.0 not only achieves SOTA performance but also provides a feasible scheme for developers to build their own NLP models.
- ERNIE 2.0 outperforms BERT and XLNet on 7 GLUE language understanding tasks and beats BERT on all 9 of the Chinese NLP tasks.
Know more about this work here.















































































