



|
Listen to this story
|
The machine learning life cycle is a cyclical process that data science initiatives must go through. Machine learning encompasses a wide range of disciplines, from business jobs to data scientists and DevOps. The life cycle specifies each step that an organization/individual should take to extract tangible commercial value from machine learning. A detailed grasp of the ML model development life cycle will allow you to properly manage resources and acquire a better idea of where you stand in the process. MLOps, an abbreviation for Machine Learning Operations, is a key stage in the design of a data science project. This article will lead you to the best ML operation design, which will help to gain confidence in the life cycle. Following are the topics to be covered.
Table of contents
- A glance over the data science project cycle
- The flow of Machine learning operations
- Trigger
- Model training & testing
- Model registering
- Deployment
- Monitor
A glance over the data science project cycle
There are three major steps in the machine learning life cycle, all of which have equal importance and go in a specific order. All of these components are essential for creating quality models that will bring added value to the business. This process is called a cycle because, when properly executed, the insights gained from the existing model will direct and define the next model to be deployed.
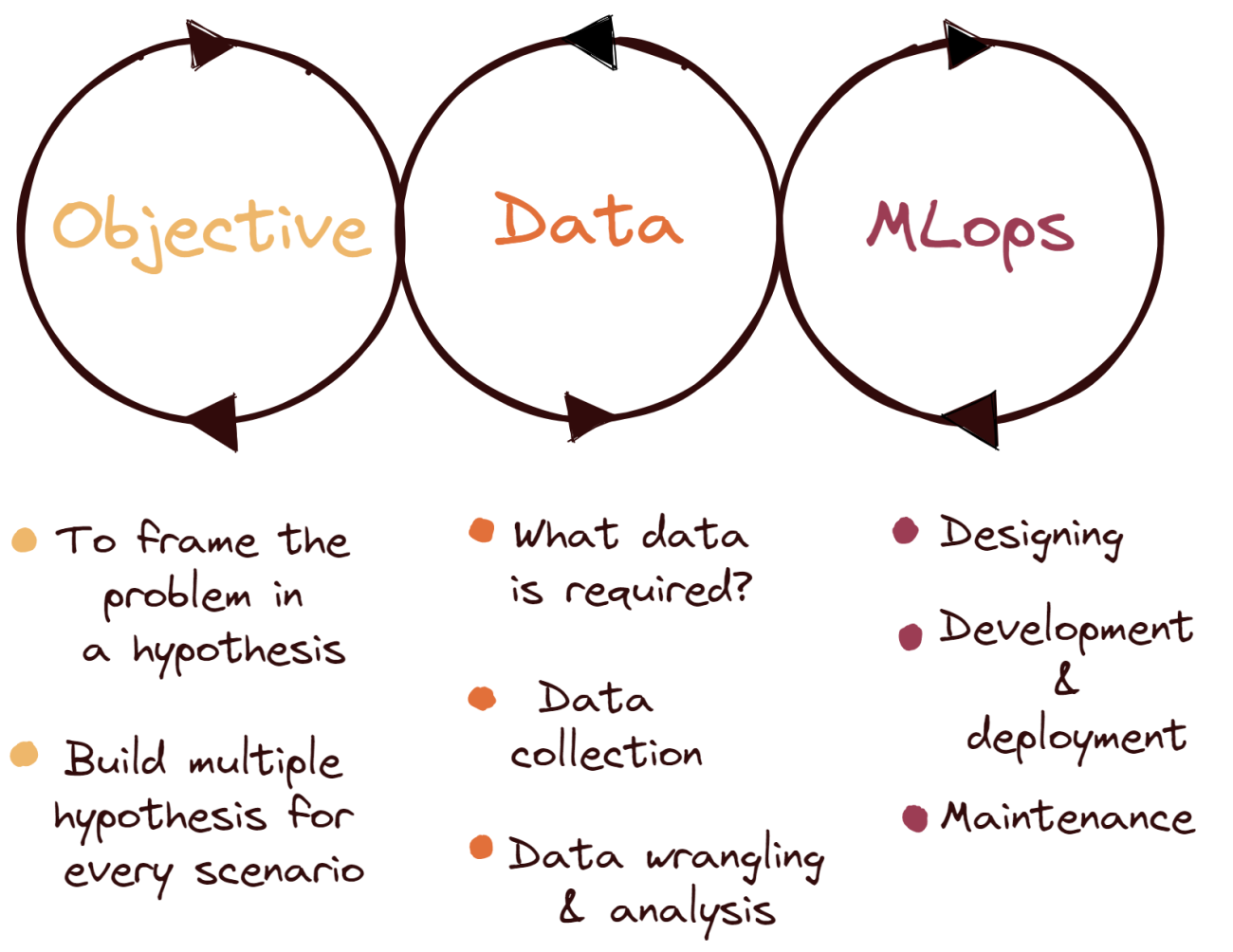
Objective
The initial phase in the life cycle is to find an opportunity to enhance operations, boost customer happiness, or create value in some other way. The core problem and its subproblems will be formulated into hypotheses, which will then be solved progressively.
For example, if a food delivery company wants to predict their temporary churn rate for the upcoming year and solve them beforehand. The engineers will primarily frame the objective as “Prediction of temporary churn”, and their target years would be at least two years. They would build every possible scenario where the company might face a churn. Once these hypotheses are generated, they would now try to combine some hypotheses or reject them so that they would come to a feasible number that they could work on. It is also possible that some would require machine learning, and some won’t.
Therefore, this stage is to frame the objective and decide whether these hypotheses really require a machine learning model and, after concluding, then proceed to the data part of the project.
Data
The following stage is to gather and prepare all essential data for use in machine learning. This entails interviewing domain experts to establish what data would be helpful in forecasting readmission rates, collecting that data from past patient records, and converting it to a format appropriate for analysis and processing.
To extract insights from the data using machine learning, the target variable should be selected. In the above example of temporary, the target variable for a certain objective would be “total time spent by customer” for every time the customer opens the app.
ML operations
Once the data is prepared, then the engineering team designs the machine learning algorithm required to perform the tasks. Generally, an organization uses generalized 2-3 models that could be used for every problem so that time could be saved from the research.
Explaining a model’s findings to others without data science expertise is one of the most challenging aspects of machine learning initiatives, especially in highly regulated industries like healthcare. Machine learning has traditionally been seen as a “black box” since it is difficult to evaluate findings and explain their worth to stakeholders and regulatory agencies. The easier it is to satisfy legal standards and explain the value of your model to management and other important stakeholders, the more interpretable it is.
The final phase is to put the data science project into action, record it, and manage it so that the hospital can continue to use and build on its models. Model deployment is frequently problematic because of the coding and data science knowledge required, as well as the unacceptably time to implementation from the beginning of the cycle utilising typical data science methodologies.
Are you looking for a complete repository of Python libraries used in data science, check out here.
The flow of Machine learning operations
The whole flow set is in the sequence of events; it is known as a machine learning pipeline. The pipeline has five major steps: data ingestion, model training and testing, registering, deployment and monitoring.

Trigger
The data ingestion phase serves as a “trigger” for the ML pipeline. It handles data volume, velocity, and diversity by extracting data from diverse data sources (such as databases, data warehouses, or data lakes) and ingesting the necessary data for the model training stage. Robust data pipelines coupled with many data sources allow it to undertake extract, transform, and load (ETL) operations to deliver the data required for ML training. In this stage, we can partition and version data in the needed format for model training (for example, the training or test set). As a result of this stage, any experiment (model training) may be audited and traced.
Model training & testing
This step will enable model training after obtaining the necessary data for ML model training in the previous step; it has modular scripts or code that perform all of the traditional steps in ML, such as data preprocessing, feature engineering, and feature scaling before training or retraining any model. Following that, the ML model is trained while hyperparameter adjustment is performed to match the model to the dataset (training set). This stage can be completed manually, although there are efficient and automatic alternatives available, such as Grid Search or Random Search. As a consequence, all critical phases of ML model training are carried out, with an ML model as the end result.
During testing, the trained model’s performance is assessed on a distinct collection of data points known as test data (which was split and versioned in the data ingestion step). The trained model’s inference is assessed using metrics chosen specifically for the use case. This stage produces a report on the performance of the trained model. Implementation of use cases We evaluate the trained model’s performance by testing it on test data (which we separated earlier in the Data ingestion stage).
Following the testing of the trained model in the previous stage, the model may be serialized into a file or containerized (using Docker) and exported to the production environment.
Model registering
The model that was serialized or containerized in the previous phase is registered and saved in the model registry in this stage. A registered model is a logical grouping or bundle of one or more files that construct, represent, and run your machine learning model. Multiple files, for example, can be registered as one model. A classification model, for example, can be made up of a vectorizer, model weights, and serialized model files. These files can all be registered as a single model. Following registration, the model (all files or a single file) may be downloaded and deployed as required.
Deployment
It is critical to validate the durability and performance of an ML model before deploying it to production. As a result, the “application testing” phase involves carefully validating all trained models for resilience and performance in a production-like environment known as a test environment. A quality assurance professional reviews the performance outcomes either automatically or manually. When the performance of the ML model passes the criteria, it is certified for deployment in the production environment.
Models that have been previously tested and approved are deployed in the production environment for model inference in order to provide commercial or operational value. This product release is being delivered to the production environment, which is made possible by CI/CD pipelines.
Monitor
The monitoring module collects crucial data for monitoring data integrity, model drift, and application performance. Telemetry data may be used to monitor application performance. It illustrates the device performance of a manufacturing system over time. We can monitor the performance, health, and durability of the production system using telemetry data such as accelerometer, gyroscope, humidity, magnetometer, pressure, and temperature.
Analyzing the model performance of ML models deployed in production systems is crucial to ensuring optimal performance and governance in connection to business choices or effects. To assess model performance in real-time, we employ model explainability methodologies. Using this, we analyze critical characteristics such as model fairness, trust, bias, transparency, and error analysis in order to improve the model’s commercial relevance.
Monitoring and analysis are performed to regulate the deployed application and achieve optimal business performance (or the purpose of the ML system). We can produce specific warnings and actions to regulate the system after monitoring and evaluating production data.
Conclusion
All models developed, deployed, and monitored using the MLOps technique are end-to-end traceable, and their lineage is tracked to trace the model’s origins, which includes the source code used to train the model, the data used to train and test the model, and the parameters used to converge the model. With this article, we have understood the machine learning life cycle and machine learning operations.
















