



|
Listen to this story
|
Introduction
As per International Data Corporation (IDC), 80%–90% of data in the world will become unstructured by 2025 and a major part of it would be text data. In effect, this mandates enterprises to generate insights from the text for right decision making, growth, streamlining the business strategies and profitability. In parallel, we could see tremendous improvement in natural language processing and AI/ML techniques. Though we have effective natural language processing techniques, machine learning and deep learning algorithms, the accuracy/aspects of insights generation depends on the data scientist who analyses and interprets the raw text. Due to lack of business knowledge, these data scientists majorly rely on subject matter experts to understand the data, training set generation and right KPI’s (Key Performance Indicators) identification. Additionally, model building is time consuming and in contrast, analytics and insight generation need to be expedited at the earliest for right decision making at the right time.
To overcome such challenges, we need to build robust text analysers with the capability to understand the data and generate training sets on our own and classify all kinds of human-generated text. This is possible, if we apply hybrid approach to build our text analyser and insight engine with components such as text cleanser using natural language processing’s linguistic features, handle different way of human writing using sentence embedding transformers, understand the data using unsupervised clustering algorithm, NLP based labelling assistant and business insights generation using vector based classifiers. In addition, this proposed approach is very well-suited for multi-class classification problems and helps data scientists build their own insight engine, perform text analysis within a short span of time and extend to all kinds of text analysis with minimal configurable changes.
Robust Text Analyser and Insight Engine
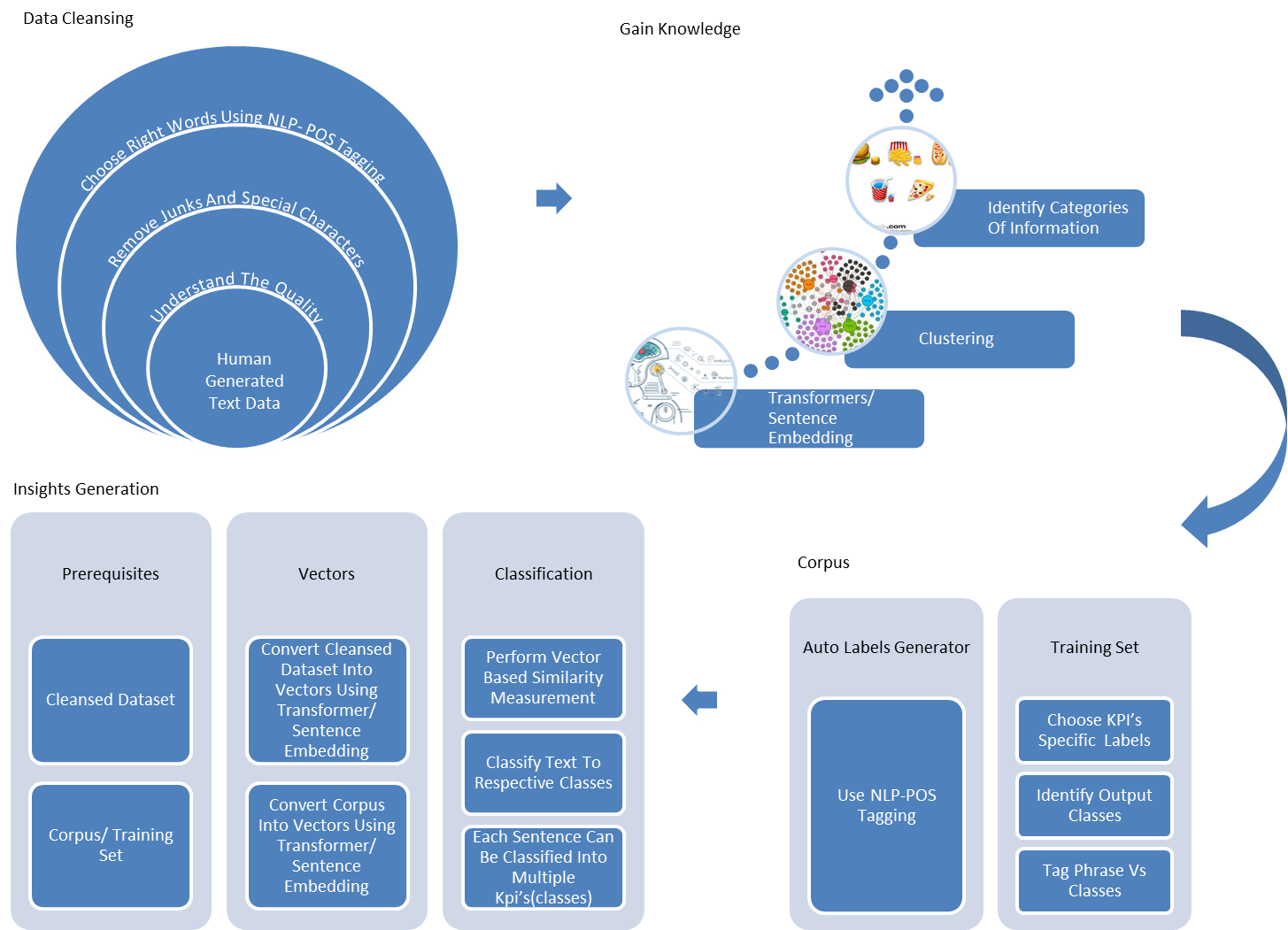
Since most analytics projects are short term and the objectives are towards the insight generation for the right decision making, the focus would be on less turnaround time to generate these insights. Considering this, I have developed the Robust Text analyser with four different phases—data cleansing, gaining knowledge on the dataset, corpus generation and insight generation, as shown in Fig. 1.
Data Cleansing
Every human-generated text dataset contains various data quality issues such as spelling mistakes, junk characters, unwanted special characters, format inconsistencies, partial data filling, non-standardised data, different naming conventions and short descriptions, among several others. These quality issues affect the accuracy of the analysis. To overcome this, the first level of cleansings treatment can be performed using regex or POS tagging as well. Following basic cleaning, choosing the right word for the analysis is very important. This can be achieved using Part of Speech Tags. The part of the speech tag explains how a word is used in a sentence. There are eight main parts of speech tags such as nouns, pronouns, adjectives, verbs, adverbs, prepositions, conjunctions and interjections. Though eight main tags were available, the analysis can be performed using nouns, adjectives, verbs and adverbs tags. These four tags can be considered as analytical-tags. As a second level of cleansing, using analytics-tags, we can choose the important words for the insight generation. This approach helps us reduce the size of the data to be analysed drastically and also improves the accuracy. POS tagging can be performed using Spacy or NLTK libraries.
Knowledge Gain
To identify the context of information to be presented in the report for decision making, complete understanding of the dataset becomes very crucial. Due to lack of subject knowledge, this process can lead to a dependency on subject matter experts and delay the analysis turnaround time. To overcome the same, I have used text clustering which groups the related items together, understand the categories of information belonging to each and every group and use this knowledge to speed up the labelling activity. The above mentioned text clustering becomes challenging due to humans generated with different writing patterns. In order to handle this challenge, preprocessing the text data with sentence embedding techniques is very effective. Sentence embedding is the collective name for a set of techniques in natural language processing where sentences are mapped to vectors of real numbers while a transformer is a deep learning model that adopts the mechanism of self-attention, differentially weighing the significance of each part of the input data. Overall, the Knowledge Gain phase contains data preprocessing supported with sentence embedding transformers—universal sentence encoders are preferable—which converts the text into 512 dimensional vectors and enables the text to support AI/ML-based techniques for insight generation. Following text transformations, text clustering needs to be applied which will group the related information despite larger paragraphs and will help walk through different categories of information that the dataset possesses, eventually fastening the text data and understanding the phase compared to a sequential order.
Corpus
ML-based text analysis mandates the training set/corpus, which is a time-consuming process due to SMEs’ dependency or lack of business knowledge. To overcome the time complexity and to expedite the corpus generation phase and speed up the analytics timeline, I have built a customised auto-label generators by finding the specific POS tags combinations such as Noun + Adjectives, Noun + Adverbs or Noun with analytical-tags existence in the dataset. Such customised pattern validation in the training set generation phases was very effective. Sometimes, the data we deal with may contain longer paragraphs which can be handled by splitting the paragraphs into multiple sentences followed by filtering logic application. This auto-label generation approach helps to identify the most useful/right phrases for the training set. In addition, this approach detects the labels automatically, easily and quickly. The accuracy of the auto-label detector approach is limited due to the nature of the dataset and human writing patterns but it would be helpful in reducing the total labelling turnaround time.
Insights Generation
In this phase, we can opt for any classification machine learning/deep learning techniques with modelling life cycle such as building model, testing, deployment, retraining and governance. But analytical projects are short in span, non-repetitive and model governance may not be preferable due to dedicated FTE allocation and rework. In addition, there are some situations where analytical classification needs multiple classes to be coined to one paragraph. For instance, in an online purchase, an order delivery failure can occur due to multiple reasons such as system error, product classifications, product stocking area, product unavailability, delivery issues, or more. In this scenario, the standard existing classification ML models predict and result in only one output class which cannot be preferred to understand the holistic picture of the Performance analysis.
So, to support these kinds of analytical natured projects, I have designed the robust text analyser’s Insight Generation phase by performing vector similarity based classification with the capability to classify ‘n’ number of output classes. To perform this phase, we need two prerequisite items such as corpus and cleansed base dataset—as mentioned in the Data cleaning phase—to be analysed. These two prerequisites—training set and the base dataset—need to be converted to sentence embedding based vectors. Finally, using Numpy similarity measurement algorithms and the matching threshold, multiple output class classification can be performed faster. Overall, this classification approach featured with a single item can be classified into multiple classes and new dataset/metrics/purposes can be uplifted only by revising/replacing the training set.
Applications
This approach is well suited for insight generation from unstructured text data across sectors—such as e-commerce, healthcare, media, banking and others—for failures root cause analysis, performance analysis, complaints analysis, software issues cause analysis, chatbot query analysis, description analysis, survey analysis, and email analysis. It can also be a good assistance for topic modelling.














































































