



|
Listen to this story
|
The architecture of the transformer is encoder-decoder. From an input sentence, the encoder collects features, which are then used by the decoder to create an output sentence. The FNet Encoder is a transformer based on the Fourier transform principle. It is claimed to be significantly faster than the BERT model. This was achieved by removing the self attention layer of the BERT model with a Fourier transform. In this article, we focus on discussing the architecture and implementation of the FNet Encoder. Following are the topics to be discussed.
Table of contents
- Brief about the Encoder-Decoder model
- The architecture of the FNet Encoder
- Benefits and Drawbacks of FNet encoder
- Question Answering with FNet encoder
Brief about the Encoder-Decoder model
In Natural Language Processing a transformer works as an interpreter for deep learning to understand the human language and achieve the goals like sentiment analysis, question answering, text classification, etc. A transformer consists of majorly two components encoder and a decoder.
The game of guessing the word is the greatest approach to grasping the idea of an encoder-decoder paradigm. The game’s rules are relatively straightforward: Player 1 must draw the meaning of a word that is randomly selected from a list. The second team member’s job is to analyse the drawing and determine which word it is meant to represent. Three crucial components are player 1 (the one who transforms the word into a painting), the artwork (a rabbit), and the person who correctly guesses the word that the drawing depicts (player 2). So player 1 is the encoder which takes the input value and converts it into a form which is understandable by player 2 and then player 2 converts the answer into a human language.
Data must be encoded in order to be in the desired format. In the above example, we turn a word (text) into a picture (image). In the context of machine learning, we translate a string of words from human language into a two-dimensional vector, sometimes referred to as the hidden state. By stacking a recurrent neural network, the encoder is created (RNN).
A two-dimensional vector representing the entire meaning of the input sequence is the encoder’s output. The number of cells in the RNN determines the length of the vector.
A message that has been encoded must be decoded before it can be understood. Player 2 will transcribe the image into a word. The decoder will transform the two-dimensional vector into the output sequence, which is the English phrase, in the machine learning model. In order to predict the English term, it is likewise constructed with RNN layers and a thick layer.
Are you looking for a complete repository of Python libraries used in data science, check out here.
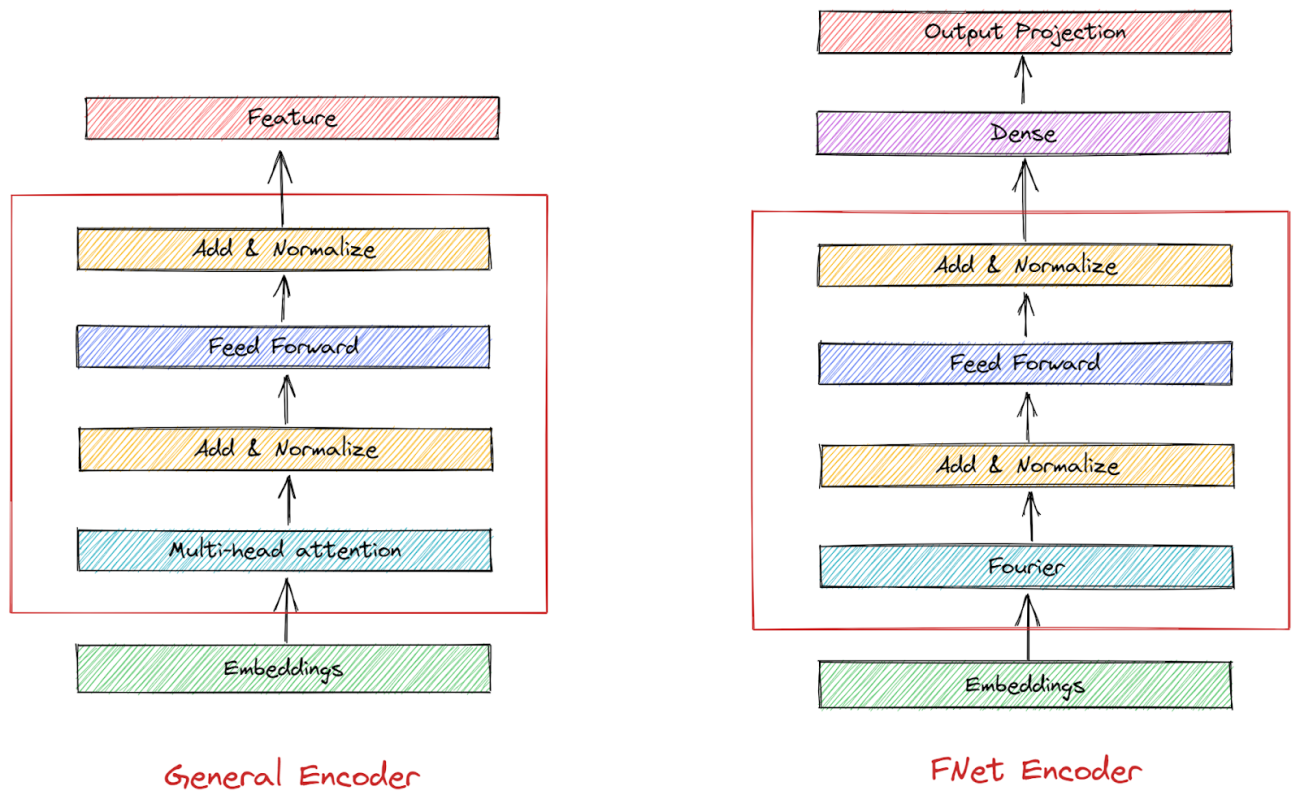
The architecture of the FNet Encoder
Each layer in the attention-free Transformer design known as FNet is composed of a feed-forward sublayer followed by a Fourier mixing sublayer. Each Transformer encoder layer’s self-attention sublayer is essentially replaced with a Fourier sublayer that performs a two-dimensional Discrete Fourier Transform (DFT) on its embedding input.
- One dimensional DFT along the sequence dimension
- One dimensional DFT along the hidden dimension
There is no need to change the nonlinear feed-forward sublayers or output layers because just the real component is retained in order to handle complex values. When the real portion of the whole transformation was only retrieved after the Fourier sublayer, that is, after using both one-dimensional DFT along the sequence dimension together with the hidden dimension, FNet produced the best results.
The Fourier Transform can be best understood as a highly efficient token-mixing method that gives feed-forward sublayers adequate access to all tokens. We may also think of each alternating encoder block as performing alternate Fourier and inverse Fourier Transforms, shifting the input between the “time” and frequency domains, thanks to the dual nature of the Fourier Transform. FNet may be regarded as alternating between multiplications and convolutions since multiplying by the feed-forward sublayer coefficients in the frequency domain is similar to convolving (with a comparable set of coefficients) in the time domain.
Benefits and Drawbacks of FNet encoder
The primary benefits of the FNet encoder could be listed as:
- The loss of information during transformation is minimum.
- This method highlights the fact that an encoder could be built without attention layers
- The speed of the encoder is increased by 3% as compared to the BERT encoder.
There are certain drawbacks of FNet
- It is slower on GPUs
- It has a substantially bigger memory footprint.
- It is unstable during training
Question Answering with FNet encoder
This article uses the Keras layer to build a Fnet encoder and decoder model which will be trained on Cornell Dialog Corpus. This corpus includes a sizable, richly annotated collection of fictitious talks taken from uncut film screenplays. The model will try to answer questions based on the questions asked.
The initial stages of the implementation like reading and processing the data are skipped due to time constraints, refer to the colab notebook provided in the references section.
The model is trained only on 13% of the total data due to constraints it could be trained on more amount of data. Once the data is loaded and split into training and validation data, the text needs to be tokenized, vectorized and padded.
vectorizer = layers.TextVectorization(
VOCAB_SIZE,
standardize=preprocess_text,
output_mode="int",
output_sequence_length=MAX_LENGTH,
)
vectorizer.adapt(tf.data.Dataset.from_tensor_slices((questions + answers)).batch(128))
The vectorization of the text is done by using the Keras TextVectorization layer. Basic options for manipulating text in a Keras model are available in this layer. It converts a collection of strings (each sample is equal to one string) into a list of token indices (each sample is equal to a 1D tensor of integer token indices) or a dense representation (each sample is equal to a 1D tensor of float values providing information about the sample’s tokens).
training = train_data.map(vectorize_text, num_parallel_calls=tf.data.AUTOTUNE)
validation = val_data.map(vectorize_text, num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = (
training.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.prefetch(tf.data.AUTOTUNE)
)
val_dataset = validation.cache().batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
Since the amount of words in each sentence varies, padding is necessary. We may also set a maximum number of words for each sentence, and if it exceeds that number, we can omit certain words.
Build the Fnet encoder and decoder, train the model on the training data and we are set for using the model for the question answering.
class FnetEncode(layers.Layer):
def __init__(self, embed_dim, dense_dim, **kwargs):
super(FnetEncode, self).__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.dense_proj = keras.Sequential(
[
layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),
]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs):
inp_complex = tf.cast(inputs, tf.complex64)
fft = tf.math.real(tf.signal.fft2d(inp_complex))
proj_input = self.layernorm_1(inputs + fft)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
As discussed above in the architecture section the Fnet encoder has a total of 2 normalization layers and one Fourier transformation layer. The output from the Fourier layer is sent for normalization and then sent to the dense layer.
For the decoder, you can refer to the colab notebook attached in the references section. Then the Fnet model would be trained on the training data and validated on the validation data.
fNetModel.fit(train_dataset, epochs=1, validation_data=val_dataset)

The accuracy is low because the model is trained only on 13% of the data if trained on more data it would definitely perform better.
decoding_text("How hard is to say sorry?")

Conclusion
The exceptional accuracy achieved when the Fourier sublayers of an FNet are substituted for the self-attention sublayers of a transformer also highlights the exciting possibility of applying linear transformations in place of attention mechanisms in text categorization tasks. With this article, we have understood the architecture and implementation of the FNet encoder.
















