



Until the 1920s, most black and white motion pictures were made with blue-sensitive film. The film stock was sensitive to the blue end of the spectrum but insensitive to the yellow-red end, which meant that it registered reds and yellows as black and light blues as white.
All the colour that is lost to lack of technology came to life more vividly with the advent of digital colourisation back in the 1970s. The black and white films were processed through computer software, which figured out the differences between different flashes of grey and then applied colour chosen with the help of a technician’s educated guess of colours of objects.
Later, techniques like segmentation were introduced to ease the process. Now the animators use a multitude of image processing software to colourise archive footage. Nevertheless, the whole process is laborious, to say the least. There are various objects within the frame and the technicians have to binge read history at the micro level to make an accurate guess as to how a woollen suit from the 1920s would have looked under the sun.
It took almost 5,800 hours of research and over 27 miles of film for the colourisation of a 1920s American footage in 2017.
An easier way to this process would be the use of a single frame of reference. So that a single image of desired colours can be fed to a computer, which would run an algorithm that applies these colours on to a colourless image using the colour palette of the reference image.
Present day AI models are capable of differentiating between the faces and the torso, background and foreground, and the depth in the video as well.
But, maintaining the consistency in the way the colour is applied with every passing second and with every frame is where the existing techniques find it difficult.
The researchers at Hongkong University of Science and Technology in collaboration with Microsoft AI, try to address these challenges with Deep Exemplar -based Video colourisation.
Overview Of The Model Architecture
In this work, the authors present an end-to-end framework to colourise videos using single references and without losing temporal consistency.
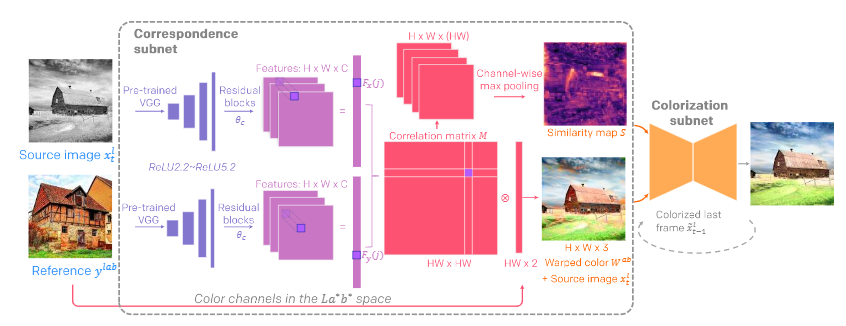
The network consists of the following:
- 4 residual blocks each with 2 convolutional layers.
- The colourisation subnet adopts an auto-encoder structure with skip connections to reuse the low-level features.
- There are 3 convolutional blocks in the contractive encoder and 3 convolutional blocks in the decoder which recovers the resolution; each convolutional block contains 2∼3 convolutional layers.
- It then serves as the last layer to bound the chrominance output within the colour space.
- The video discriminator consists of 7 convolutional layers where the first six layers halve the input resolution progressively.
This framework guides the colourisation of every frame, thus reducing accumulated propagation errors. Video frames are colourised in sequence based on the colourisation history, and its coherency is further enforced by the temporal consistency loss. All of these components, learn end-to-end and help produce realistic videos with good temporal stability.
To cover a wide range of scenes, multiple datasets for training were used. 1,052 videos from Videvo stock were collected and for each video clip, a reference is provided by inquiring the five most similar images from the corresponding class in the ImageNet dataset.
The researchers have deliberately crippled the colour matching during training, so the colourisation network better learns the colour propagation even when the correspondence is inaccurate.
To evaluate the performance of the model, Frechet Inception Distance is applied. This measures semantic distance between the colourised output and real images.

The realistic effects, which this works boast of, has been achieved with the introduction of an adversarial loss. This to constrain the colourisation video frames to remain realistic.
Instead of using image discriminator, a video discriminator is used to evaluate consecutive video frames. The flickering and defective videos had been assumed to be easily distinguishable from real ones, so the colourisation network can learn to generate coherent natural results during the adversarial training.
It is easy for us, humans, to guess the colour of the sky and how the face would illuminate under a street light in comparison to that of a campfire. The effects of colour in an image should be meaningful; have semantic relation to be realistic. And, for a machine to do all this just with one reference is a big ask. But somehow the authors of this paper, claim to have come with a successful solution to arcane problems.
Key Takeaways
- A contextual loss was introduced to encourage colours in the output to be close to those in the reference. The contextual loss is proposed to measure the local feature similarity while considering the context of the entire image, so it is suitable for transferring the colour from the semantically related regions.
- And, a smoothness loss to encourage spatial smoothness. It is assumed that neighbouring pixels should be similar if they have similar chrominance in the ground truth image.
- The authors try to unify the semantic correspondence and colourisation into a single network, training it end-to-end to produces temporal consistent video colourisation with realistic effects.
Read more about this work here.

















