






|
Listen to this story
|
To unlock the value of your organization’s data, you must efficiently extract the data from on-premises databases. Many tools can do the job, but it can be difficult to decide what tools to use and how to use them. It can also be tempting to bring in premium tools, hoping they will do the job more effectively. However, suppose we understand the underlying architecture of database connectivity. In that case, we can write code to manage the job – meanwhile saving a lot of extra licensing costs and time in learning a new framework.
The connectivity between an application and a DBMS (Database Management System) is done via JDBC or ODBC.
Java™ database connectivity (JDBC) is the JavaSoft specification of a standard application programming interface (API) that allows Java programs to access database management systems. The JDBC API consists of a set of interfaces and classes written in the Java programming language.[1]
ODBC is equivalent to JDBC, developed by Microsoft and Simba Technologies, to be used in Microsoft Windows environments. Most of the time, vendors will not try reinventing the wheels of these industry standards. Instead, under the hood, it is a matter of whether the connectivity can be executed concurrently and using what kind of tools to accomplish this goal.
There are generally two main distributed query architectures: Massively Parallel Processing (MPP) and MapReduce.
MPP Database Engine
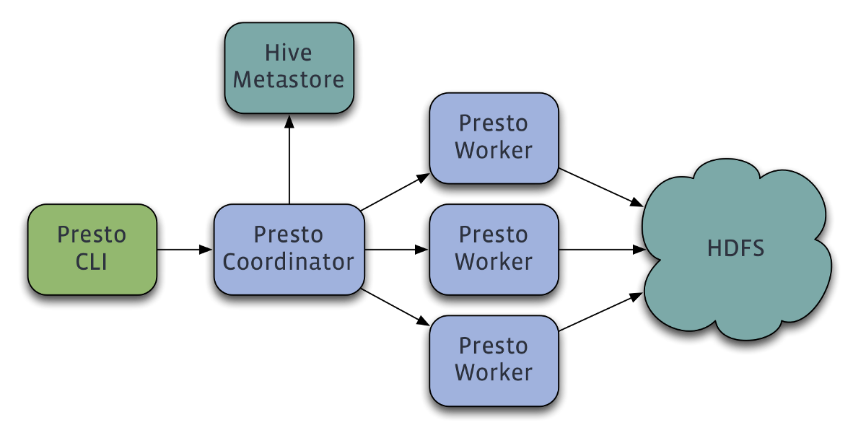
A common MPP Database Engine is Meta’s (Facebook) PrestoDB. MPP promises to leverage multiple machines called worker nodes with independent processors and memory and coordinate each other to divide and conquer an otherwise large workload or a big query. Furthermore, the processing is done in memory, so the results can be very fast.
Below is the architecture of PrestoDB:
MapReduce
MapReduce is an algorithm originally developed by Google to process large datasets. The idea is to split data into smaller pieces using a mapper and a reducer. The mapper’s job is to produce a key-value pair using a unique hash to split the data into smaller subsets for processing. The reducer’s job is to aggregate the data back after the data is processed.
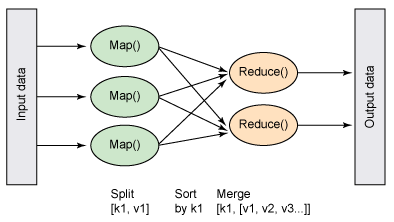
https://www.researchgate.net/figure/MapReduce-diagram-10_fig1_325848553
Spark is an enhanced version of MapReduce, capable of processing in memory and spilling to disk when the data is too large, whereas MapReduce only operates on HDFS. According to Databricks, Spark can be 100 times faster than Hadoop MapReduce.[2]
MPP vs MapReduce
Since everything is processed in memory with MPP, it isn’t easy to handle an extremely large dataset. That’s why Meta, which developed a very efficient MPP engine PrestoDB, has decided to put it on Spark for more efficient processing.[3]
With a managed Spark cluster, Databricks is a clear winner for data processing. In the next section, we will examine the JDBC interfaces provided by Spark to maximize data loading performance when interacting with traditional DBMS.
Types of data loading
There are two types of data loading: batch load, where we load the whole table in one batch, and refresh pipeline, where we separate the load to do it in sequence due to the large volume of data in the source.
In general, domain or dimension tables are smaller in size so that they can be loaded as a whole. This generates less burden for the source system; however, larger tables must be loaded in phrases. In these scenarios, we need to fulfil the following two requirements:
- Managing parallelism
It is important to understand how parallelism works when querying DMBS from Databricks. As a result, we can take advantage of the performance improvement.
2. Finding the partition column
Finding the upper and lower bound of a business key we want to pull from will help limit the source system’s load. Divide and conquer is always faster and easier than trying to load everything in one big batch. Most of the time, if there’s a date column available, it would mean one month at a time. But if the data volume is huge, it can be one day at a time or one week at a time.
Push-down optimization
Another tip for performance gain is to leverage the push-down optimization by applying filters in the query. This will allow the query to take advantage of the source DBMS’ index or primary key for faster load.
Partitioning
There are two interfaces to handle partitioning in Spark’s Dataframe API:
- jdbc(url:String,table:String,partitionColumn:String,lowerBound:Long,upperBound:Long,numPartitions:Int,…)
Available in Python and Scala, this interface takes an integer partition column, and an integer upper bound and lower bound and splits the data into an equal number of specified partitions. This works well with evenly distributed scenarios, but if the data is skewed, it does not perform well. The downside of this interface is that it doesn’t filter the source data, so the whole dataset needs to be returned to a Dataframe for further processing.
- jdbc(url:String,table:String,predicates:Array[String],…)
Available in Scala only, this interface takes a partition column and an array of a predicate, essentially a WHERE clause. It will build a series of WHERE clauses based on the array specified, push down these queries into the database, generate a number of threads of the array size, and then return the data to Dataframe all at once. This allows for greater flexibility in handling the data loading.
Other factors to consider
Although it is tempting to use Python to do all the work, the Scala low-level API provides greater flexibility in controlling data size. However, whichever interface we choose, we should always consider the impact on the source DMBS, including:
- Choosing the right partition
- Choosing the right index
- Hitting the primary key, if possible
- Limiting the number of rows returned at once
- Limiting the number of columns returned if the entire table is not needed
- Ensuring fast connectivity between Databricks and the source, for example, Azure Express Route
Conclusion
By understanding the underlying JDBC APIs provided by Spark, we can develop our own notebooks using Databricks, control the flow, and take advantage of the lightning speed to extract data from source DMBS. In addition, even if an organization is required to use tools like Azure Data Factory, we now have a greater understanding of their limitations and why tools only accept certain parameters so that we can carefully examine the pros and cons when making a selection.
Finally, for a more technical deep dive into the APIs, please refer to the below articles by Databricks:
https://docs.databricks.com/data/data-sources/sql-databases.html
__________________________________
1 https://www.ibm.com/docs/en/informix-servers/12.10?topic=started-what-is-jdbc
2 https://databricks.com/spark/about
3 https://prestodb.io/blog/2021/10/26/Scaling-with-Presto-on-Spark

















