One of the most fascinating things explored in machine learning is neural networks. They have found applications in sub-fields of ML such as deep learning, as well as in neuroscience, where it is used to grasp the functioning of biological systems even better. The latest research in NN has focussed more on the insides of a network along with the developments of different NN.
One such new study in NN called around the sinusoidal activation functions. These NN are mostly not used in today’s scenario of ML mainly because it is difficult to train them. This article highlights a research case where it clarifies the reasons for problems in sinusoidal activation functions and their usage in NN.
What Is An Activation Function?
NN contains three layers in their structure:
- Input
- Output
- Hidden layers
The hidden layers process and compute based on the input received and pass the output (results) to the output layers. Now, activation functions act as values to transform non-linearity in the algorithm into a linear model. While this may not happen completely, this transformation process will decide the “activation” of the neurons in the layer.
In other words, activation functions initiate neuron activity based on their weights and biases present in the network. This is necessary to reduce errors and achieve a technique known as backpropagation — essential for NN.
Sinusoidal Activation Functions: Inherent Problems
Activation functions in today’s deep NN framework generally incorporate non-periodic functions. Popular functions like sigmoid and rectifier linear unit (ReLU), are most popular. In a study conducted by academics at Tampere University of Technology, Finland, they analysed periodic activation functions such as sine waves and presented a basis for algorithms to learn faster using sinusoidal activation functions.
They propounded that the non-monotonicity in periodic functions such as sine functions would make the activations fluctuate between strong and weak activations. They said:
“Excluding the trivial case of constant functions, periodic functions are non-quasiconvex, and therefore non-monotonic. This means that for a periodic activation function, as the correlation with the input increases the activation will oscillate between stronger and weaker activations. This apparently undesirable behavior might suggest that periodic functions might be just as undesirable as activation functions in a typical learning task.”
However, earlier developments in sinusoidal activation function involved introducing periodic functions in an NN with one hidden layer and then gradually moving with non-periodic functions such as sigmoids. In the paper, the authors also presented studies which reviewed the use of sinusoids in NN and found mixed opinions and results. In addition, the studies relied on representations such as Fourier series and transforms to evaluate activations based on periodic functions.
Analysis With Sine Waves
The authors considered a deep neural network (DNN) which has a single hidden layer. The activation has linear properties at the output. The equation for activation and prediction is depicted below.
h = F(WX+ bW)
ŷ = Ah +bA
Where X is the input vector, Y is the output target, h is the hidden activation and ŷ is the prediction. The terms W and A which indicate weight matrices,bW and bA are bias vectors, and F is the activation function. The F is actually a Fourier representation of sine function.
After applying the minima of a functional for the network frequency, one of the three sincs created has a minimum of zero, which negates weight values around zero. This means, adding other terms such as bias and amplitude does not affect the minima and the “ripples” would still be there. (The exact mathematical computation can be found here).
However, these won’t make any impact with the learning tasks as long as the input data does not have low frequencies. But, in reality this is not the case. Most data sets have data with very low frequencies. Hence, researchers find it difficult to use the sine function as a result.
The authors also present a counterpoint that these can be mitigated or smoothened if the weights associated with the neurons are very small and exact in value, they can be initialised within a range of values.
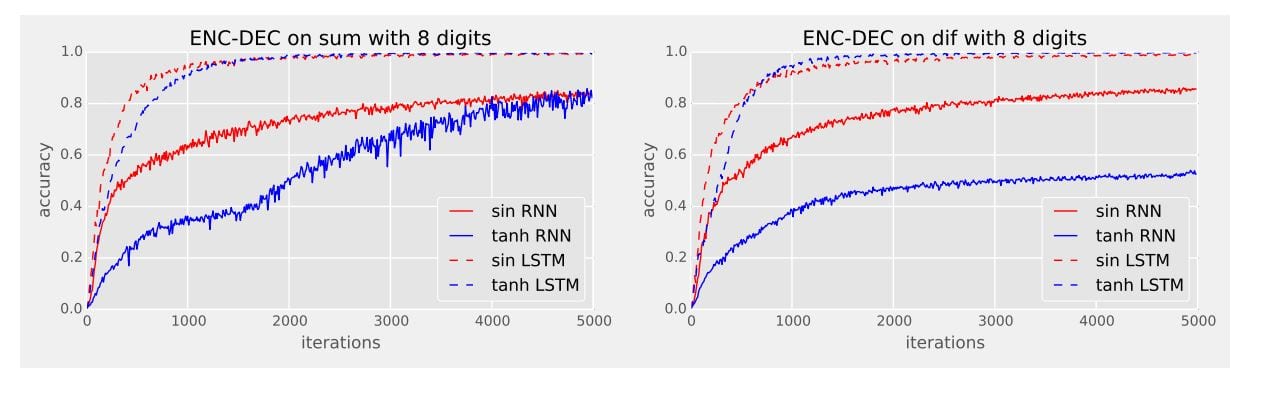
Experimentally, these are tested for a MNIST data set taken in the study across a DNN and a Recurrent neural network (RNN). The test results show an accuracy of up to 90 percent. In addition, the learning task which was done using an encoder-decoder architecture, was faster with respect to the sine function.
Conclusion
This brings us to the fact that sinusoidal activation functions are not to be ignored or neglected in the creation of activation functions in NN. It all depends on the type of tasks present in the algorithms to be trained in the networks. Periodic functions do present an alternate take for activations in neural models.