






Recommendation systems have a wide range of applications across the domains. Building a good recommender system suitable to the business requirement is always a challenge. A good system can only be developed when there is a good understanding of its working. In this article, we will discuss how to build a recommender system, especially collaborative filtering based, from scratch. We will start with the random data and build a recommender system to generate recommendations. The major points to be discussed in this article are listed below.
Table of contents
- What is collaborative filtering?
- Use of correlation
- Implementation of item-based collaborative filtering
- Implementation of user-based collaborative filtering
Let’s start with understanding collaborative filtering.
What is collaborative filtering?
Collaborative filtering can be considered as a technique to provide recommendations in a recommendation system or engine. In a basic sense, we can say that it is a way to find similarities between users and items. Utilizing it we can calculate ratings based on ratings of similar users or similar items.
Recommendation systems based on collaborative filtering can be categorized in the following ways:
- Item-based: This type of recommendation system helps in finding similarities between the items or products. This is done by generating data of the number of users who bought two or more items together and if the system finds a high correlation then it assumes similarity between products. For example, there are two products X and Y that are highly correlated when a user buys X, the system recommends buying Y also.
- User-based: This type of system helps in finding similar users based on their nature of item selection. For example, one user uses a helmet, knee guard, and elbow guard, and the second uses only a helmet and elbow guard at the time of bike riding the user-based recommendation system will recommend the second user use a knee guard.
In this article, we will try to understand collaborative filtering from scratch. First, we will create an example of data and we will try to find similarities between items. Finding similarity between items is related to finding the correlation between items based on the data that we have. Before going for implementation we are required to understand what is the correlation.
Use of correlation
Correlation can be considered as the relationship between two variables. This can be of three types positive, negative or neutral. If two variables are positively correlated then we can say changes in one variable in a positive or negative direction can provide a change in the second variable in a positive or negative direction.
If the correlation is negative then a change in one variable can cause a change in the opposite direction. If the variables are neutrally correlated then changes in one variable do not cause a change in the other. The measurement of correlation can be done using the correlation coefficient.
Calculation of correlation coefficient can be done by first calculating the covariance of the variable and then dividing by the covariance quantity by the product of those variables’ standard deviations.
Mathematically,
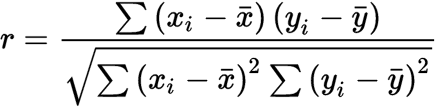
Where,
r = correlation coefficient
xi = values of x variable in a sample
x = mean of the values of the x variable
yi = values of y variable in a sample
y = mean of the values of the y variable
There are many types of correlation coefficients used in statistical analysis, we mainly use Pearson correlation for recommendation systems because it is a measure of the strength and direction of the linear relationship between two variables. Let’s move toward the implementation of a recommendation system.
Implementation of item-based collaborative filtering
1. Importing library
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt2. Dataset
In this article, we are going to implement a recommender system using the collaborative filtering approach for that purpose we will work on simple data. Let’s say that we have some users, products, and ratings of that product given by the user. We can make such a data set using the following codes;
data2 = {'user_id':[1, 2, 3, 1, 2],
'product_id':[1, 2, 1,2,3],
'product_name':['product_1', 'product_2', 'product_1','product_2','product_3'],
'rating':[3,3,3,2,2]
}
items_df = pd.DataFrame(data2)
items_df
Output:
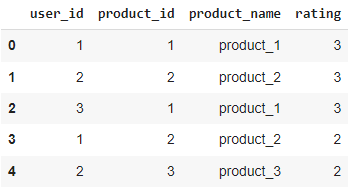
Here we can see that we have data of 3 users and 3 products.
3. Pivot table
Let’s create a pivot table using this data based on user_id and product_name.
pivot = pd.pivot_table(items_df,values='rating',columns='product_name',index='user_id')
pivot
Output:
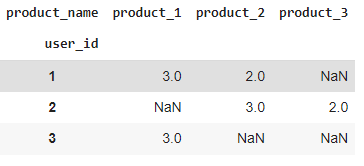
Here in the above output, we can see our pivot table. This table format can be used for calculating correlation. As the correlation will be higher we can use them as our recommendation.
Generating recommendation
To understand the process clearly, we have used a very simple dataset and we can say by seeing the above table that products 1, 2, and 3 have similar ratings and product 1 has got two reviews. So there may be a possibility of products 2 and 3 to be recommended with product 1. Let’s check our results.
print('recommended product with product_2:')
print( pivot.corr()['product_2'].sort_values(ascending=False).iloc[1:2])
Output:
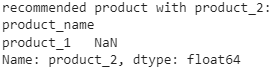
Using the above lines of codes, we calculate the correlation between products and sort the values. Then we printed 1 value and found that our system is recommending us to buy or use product 2 with product 1.
Implementation of user-based collaborative filtering
In the above section, we have gone through the process of making data and pivot tables. In this section, we will use similar data for implementing user-based collaborative filtering.
1. Pivot table
Let’s start with making a pivot table for user-based collaborative filtering. For this purpose, we are required to inverse our older pivot table which means now we are making a pivot table based on users as columns.
pivot1 = pd.pivot_table(items_df,values='rating',columns='user_id',index='product_name')
pivot1
Output:
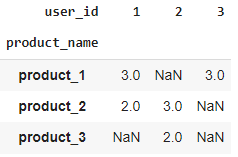
In the above table, we can see that we have user-id as a column and products as a row.
2. Generating recommendation
In this section, we will find similar users based on their provided ratings. So that we can filter out users and can give similar recommendations of different items or we can also give recommendations to a user based on similar user history.
print('similar users to user_2:')
print( pivot1.corr()[2].sort_values(ascending=True).iloc[1:2])
Output:

In the above output, we can see that user 1st is more similar to user 2nd, and it is because they have provided almost similar ratings in our main dataset.
Final words
In this article, we have gone through the basic intuitions behind making recommendation systems using collaborative filtering techniques and we learned this approach from scratch. More advanced coverage on collaborative filtering can be found here where we can see how it can be performed with a large dataset.
The codes used in the above implementation can be found here.


















