



|
Listen to this story
|
With the release of large language models like GPT-3 and PaLM, big techs have been experimenting with large language models for quite some time now. Recently, Google also joined the party in response to Open AI’s ChatGPT, called the MedPaLM, specifically for answering medical queries.
Introducing MedPaLM
While ChatGPT seems to be all over the place with no real use cases, Google Research and DeepMind recently introduced MedPaLM, an open-sourced large language model for medical purposes. It is benchmarked on MultiMedQA, a newly introduced open-source medical question-answering benchmark. It combines HealthSearchQA, a new free-response dataset of medical questions sought online, with six existing open-question answering datasets covering professional medical exams, research, and consumer queries. The benchmark also incorporates methodology for evaluating human model responses along several axes, including factuality, precision, potential harm, and bias.

MedPaLM provides datasets for multiple-choice questions and for longer responses to questions posed by medical professionals and non-professionals. These comprise the clinical topics datasets for MedQA, MedMCQA, PubMedQA, LiveQA, MedicationQA, and MMLU. In addition, a new dataset of curated, frequently searched medical inquiries called HealthSearchQA was added to improve MultiMedQA.
The HealthsearchQA dataset, which consists of 3375 frequently asked consumer questions, was curated using seed medical diagnoses and their related symptoms. All users who entered the seed phrases were shown the publicly available frequently asked questions that were retrieved using the seed data and created by a search engine.
PaLM to the Rescue
The researchers developed this model on PaLM, a 540 billion parameter LLM, and its instruction-tuned variation Flan-PaLM to evaluate LLMs using MultiMedQA.
Flan-PaLM achieves SOTA performance on MedQA, MedMCQA, PubMedQA, and MMLU clinical topics by combining few-shot, chain-of-thought (CoT), and self-consistency prompting techniques, frequently surpassing many strong LLM baselines by a large margin. FLAN-PaLM performs over 17% better on the MedQA dataset of USMLE questions than the prior SOTA. Human evaluation, though, identifies significant gaps in Flan-PaLM responses.
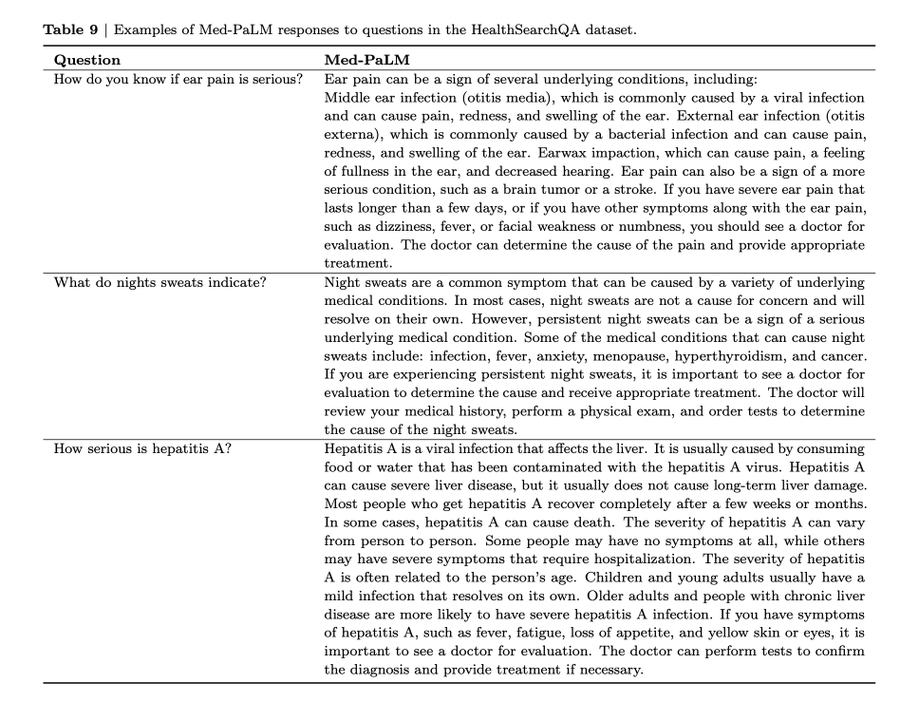
The resulting model that addresses this issue is Med-PaLM, which claims to perform well compared to Flan-PaLM but still needs to outperform a human medical expert’s judgment.
For instance, a group of doctors determined that 92.6% of the Med-PaLM responses were on par with the clinician-generated answers (92.9%), whereas just 61.9% of the long-form Flan-PaLM answers were deemed to be in line with the scientific agreement. Furthermore, like Flan-PaLM, 5.8% of Med-PaLM answers were assessed as potentially contributing to negative consequences, comparable to clinician-generated answers (6.5%), while 29.7% of Flan-PaLM answers were.


Check out the full paper here.
Google’s Healthcare Play
In the Google for India 2022 event, Google announced a collaboration with Apollo Hospitals in India to improve the use of deep learning models in x-rays and other diagnostic purposes. Google’s other health partnerships include Aravind Eye Care System, Ascension, Mayo Clinic, Rajavithi Hospital, Northwestern Medicine, Sankara Nethralaya, and Stanford Medicine, among others.
Google isn’t the first tech behemoth to venture into the AI-driven healthcare solution. Microsoft is also working closely with the OpenAI team to employ GPT-3 to facilitate collaboration between employees and clinicians and improve healthcare teams’ efficiency.
In November 2022, Meta AI also introduced Galactica, the AI-generated programme that claimed it would support academic researchers by generating comprehensive literature reviews and Wiki entries on any subject; however, it failed due to unreliable results.
Around the same time, Meta AI released CICERO by merging natural language processing and strategic reasoning. It is the first AI agent to perform at a human level in the complex natural language game “Diplomacy.” Playing against humans on the website, the AI agent showed off this SOTA performance by exceeding all other players’ average scores by more than two to one. Additionally, it was among the top 10% of players who participated in multiple games.














































































