






Machine learning models for computer vision tasks have been largely trained on photos. However, there lies a large possibility for scaling up to a wider range of applications such as augmented reality, autonomy, robotics, and image retrieval tasks if we train these models on 3D objects. To achieve this has been an uphill task since there is a dearth of large real-world datasets of objects in 3D, as compared to 2D datasets such as ImageNet, COCO, and Open Images.
Now, Google has released the Objectron dataset, which is a collection of short, object-centric video clips that capture a large set of common objects from various angles. Along with the dataset, the research also details a new 3D object detection solution.
Objectron Dataset
The Objectron dataset contains video clips and images in the following categories: bikes, books, cameras, bottles, chairs, cups, shoes, and laptops. It consists of 15,000 annotated video clips and 4 million images collected from a geo-diverse sample covering ten countries in five continents. The data contains:
- Manually annotated bounding boxes, which describe the position, orientation, and dimension, of each object
- The video clips contain augmented reality metadata such as camera poses and sparse point clouds.
- A shuffled version of annotated frames called the processed dataset for images and SequenceExample format for videos
- Scripts to run evaluation
- Supporting scripts to load the data into deep learning libraries such as Tensorflow, PyTorch, and Jax to visualise the dataset.
3D Object Detection Solution
Google’s team also released a 3D object detection solution for four categories of objects — shoes, chairs, mugs, and cameras. These models are trained using the Objectron dataset. The models are released in MediaPipe. MediaPipe is an open-source cross-platform that offers customisable machine learning solutions for live and streaming media; it finds applications in human pose detection and tracking, hand tracking, iris tracking, 3D object detection, and face detection.
In the single-stage model that was proposed earlier this year, the pose and physical size of an object were determined using a single RGB image. Some of the features of this model include:
- An encoder-decoder architecture built on MobileNetv2
- Prediction of object shape using detection and regression
- Using a well-established pose estimation algorithm for obtaining the final 3D coordinates for the bounding box
- The model is lightweight and can run real-time on mobile devices
The new 3D object detection model, however, utilises a two-stage architecture, a marked improvement from its predecessor, mentioned above, that used a single-stage model. The first stage in this model uses the TensorFlow Object Detection model to find the 2D crop of the object. The 2D crop is used to determine the 3D bounding box in the second stage. To avoid operating the object detection for every frame, the model also simultaneously determines the 2D crop for the next frame.

3D Object Detection Solution Architecture
To evaluate the performance of the 3D detection models, a 3D intersection over union (IoU) similarity statistics was used. Also called the Jaccard index, IoU is used for gauging the similarity and diversity of the sample sets; it is commonly used for computer vision tasks that measure how close bounding boxes are to the ground truth.
Google has proposed an algorithm for estimating accurate 3D IoU values for the bounding boxes. Using the Sutherland-Hodgman Polygon clipping algorithm, the team first computed the intersection points between the faces of the two boxes and further, the volume of this intersection is calculated. Finally, this calculated volume of the intersection and the union of two boxes is used for computing the IoU.
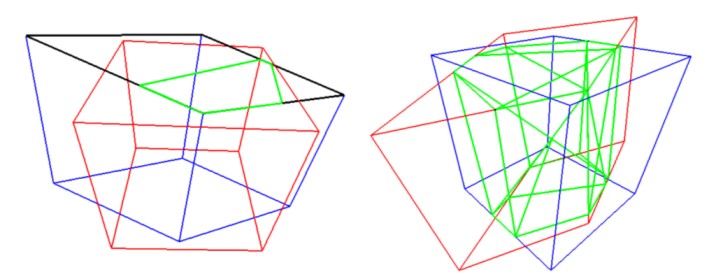
Computing the IoU
With open-sourcing the dataset and introducing the two-stage object detection model, Google hopes to enable wider research in the fields of view synthesis, unsupervised learning, and improved 3D representation.
Read the full blog here. Find the link to the open-sourced dataset here.


















