



PP-YOLO is a deep learning framework to detect objects. This framework is based on YOLO4 architecture. This method was published in the form of a Research paper titled as PP-YOLO: An Effective and Efficient Implementation of Object Detector by the researchers of Baidu : Xiang Long, Kaipeng Deng, Guanzhong Wang, Yang Zhang, Qingqing Dang, Yuan Gao, Hui Shen, Jianguo Ren, Shumin Han, Errui Ding, Shilei Wen. As the developers of PP-YOLO like to say
This paper is not intended to introduce a novel object detector. It is more like a recipe, which tells you how to build a better detector step by step.
PP-YOLO stands for PaddlePaddle – You only look once. The purpose of this framework is to ease the process of object detection in construction, training, optimization and deployment of these models in a faster and better way. This framework provides many conventional algorithms to enhance modularity and also give data augmentation methods, loss function, etc. that helps in reducing the size of the platform and enables high-performance deployment. Key features are mentioned below :
- PP-YOLO provides many pre-trained models such as object detection, instance segmentation, face detection, etc.
- PP-YOLO uses modular designs which help developers to make different pipelines quickly.
- PP-YOLO provides end-to-end methods for data augmentation, construction, training, optimization, compression and deployment.
- PP-YOLO supports distributed training as well.
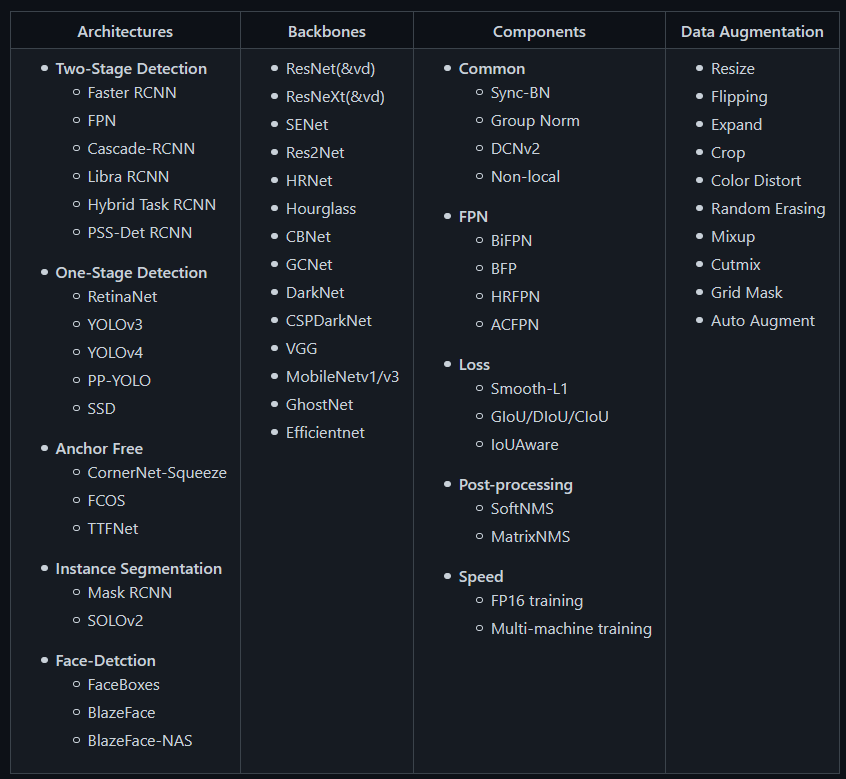
Algorithms implemented in PP-YOLO:
Architecture of PP-YOLO
The architecture of PP-YOLO is significantly based on YOLO4 . PaddleDetection’s architecture is mainly divided into 3 categories:
- Backbone: This part contains the convolution neural network to generate features. It actually contains a pre-trained classification model. In this case, it is ResNet50-vd.
- Detection Neck: Then the Feature Pyramid Network(FPN) is made to create a pyramid of features by combining and mixing the ConvNet representations.
- Detection Head: This section makes the prediction and bounding box on the object.

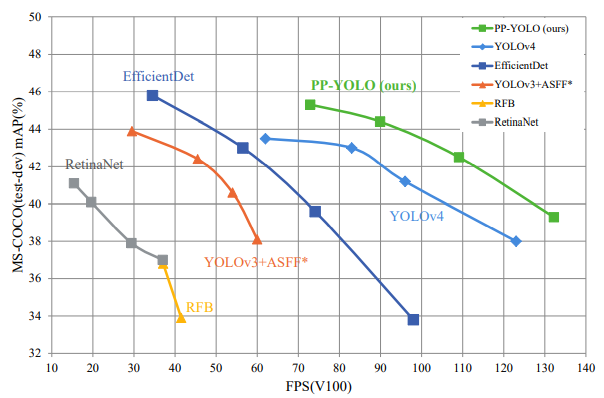
Comparison of PP-YOLO with other state-of-the-art Algorithms
PP-YOLO achieved a balance between effectiveness (45.2% mAP) and efficiency (72.9 FPS), in comparison with the existing state-of-the-art detectors such as EfficientDet and YOLOv4.
Requirements
- OS 64-bit operating system
- Python2 >= 2.7.15 or Python 3(3.5.1+/3.6/3.7), 64-bit version
- pip/pip3(9.0.1+), 64-bit version operating system is
- CUDA >= 9.0
- cuDNN >= 7.6
Install the PaddlePaddle framework with gpu. The dependency table is given here.
#If your machine is installed with CUDA10, please run the following command to install python -m pip install paddlepaddle-gpu==1.8.4.post107 -i https://mirror.baidu.com/pypi/simple # Confirm that PaddlePaddle is installed successfully in your Python interpreter import paddle.fluid as fluid fluid.install_check.run_check() #Confirm PaddlePaddle version !python -c "import paddle; print(paddle.__version__)"
Installation
Install PaddleDetection via git.
!git clone https://github.com/PaddlePaddle/PaddleDetection.git %cd /content/PaddleDetection
Make sure the test below is passed for using PP-YOLO pre-trained models.
!python ppdet/modeling/tests/test_architectures.py
The output of above test should be:

Pre-trained model prediction
Use the pre-trained model to predict the image and quickly experience the model prediction effect.
!python tools/infer.py -c configs/ppyolo/ppyolo.yml -o use_gpu=true weights=https://paddlemodels.bj.bcebos.com/object_detection/ppyolo.pdparams --infer_img=demo/000000014439.jpg
Quick start on Small Dataset
This demo fine-tunes a small dataset by using a pre-trained object detection model and learns PaddleDetection quickly.
- Specify the gpu to be used by:
!export CUDA_VISIBLE_DEVICES=0
- Download the dataset, here we are using fruit dataset for object detection. The dataset is available at here or, you can download by
!python dataset/fruit/download_fruit.py
- Train the dataset. Here we are using yolov3_mobilenet_v1_fruit.yml to fine-tune the model from the COCO dataset.
!python -u tools/train.py -c configs/yolov3_mobilenet_v1_fruit.yml --eval
- Evaluate the model by running the command below:
!python -u tools/eval.py -c configs/yolov3_mobilenet_v1_fruit.yml
- Draw inference from the trained model. Below is the input picture in the trained-model.

By calculating the inference via this command,
!python -u tools/infer.py -c configs/yolov3_mobilenet_v1_fruit.yml \ -o weights=https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_fruit.tar \ --infer_img=demo/orange_71.jpg
The output is shown as:

You can check the full demo, here.
EndNotes
In this article, we have covered the PP-YOLO framework which is much faster and accurate than other existing object detection frameworks. You can check out the advanced tutorials here.
Official codes, docs & Tutorials are available at:
You can also check some other articles at:












































































