






Facebook ReAgent, previously known as Horizon is an end-to-end platform for using applied Reinforcement Learning in order to solve industrial problems. The main purpose of this framework is to make the development & experimentation of deep reinforcement algorithms fast. ReAgent is built on Python. It uses PyTorch framework for data modelling
And training and TorchScript for serving. ReAgent holds different algorithms for data preprocessing, feature engineering, model training & evaluation and lastly for optimized serving. ReAgent was first presented in the research paper – Horizon: Facebook’s Open Source Applied Reinforcement Learning Platform by Jason Gauci, Edoardo Conti, Yitao Liang, Kittipat Virochsiri, Yuchen He, Zachary Kaden, Vivek Narayanan, Xiaohui Ye, Zhengxing Chen, Scott Fujimoto.
The key features of Facebook’s ReAgent are :
- Capable of handling Large-dimension datasets.
- Provides optimized algorithms for data preprocessing, training, etc.
- Gives a highly efficient production environment for model serving.
Algorithms Supported by ReAgent
- Discrete-Action DQN
- Parametric-Action DQN
- Double DQN, Dueling DQN, Dueling Double DQN
- Distributional RL: C51 and QR-DQN
- Twin Delayed DDPG (TD3)
- Soft Actor-Critic (SAC)
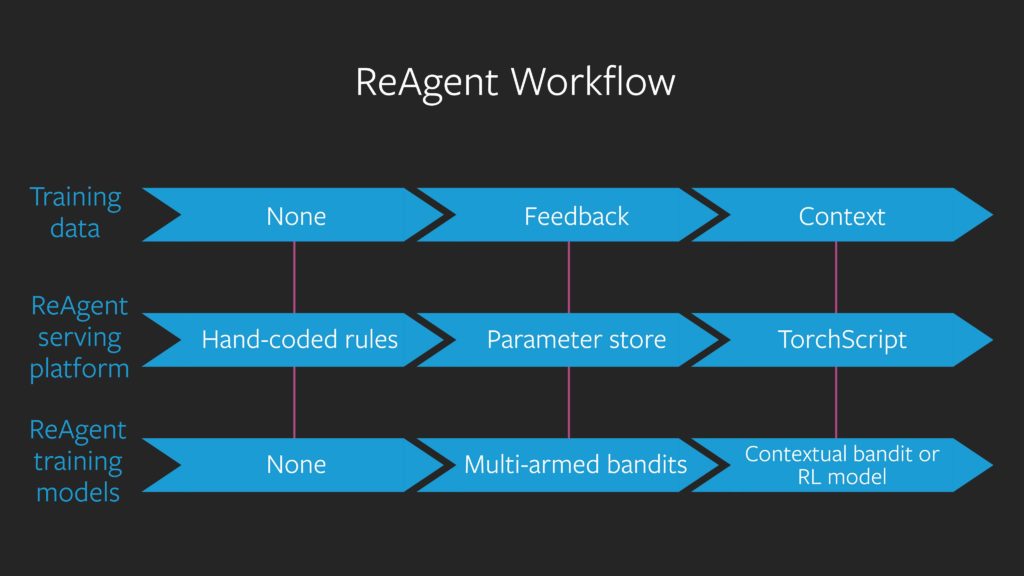
Workflow of ReAgent
The image below shows the overall workflow of ReAgent for decision making and reasoning. It starts its decision-making process by using predefined rules and then with the help of feedback, multi-armed bandits, those decisions are optimized and at last, contextual feedback trains the contextual bandits and reinforcement learning models. These trained models are then deployed via TorchScript library.
Dependencies of ReAgent Platform
Python >=3.7
Installation
ReAgent can be installed using the docker image and manually. In this case, we are cloning the GitHub repository and installing all the required dependencies of ReAgent via pip.
%%bash git clone https://github.com/facebookresearch/ReAgent.git %cd /content/ReAgent/
Then install the required python packages:
!pip install -r requirements.txt
Additionally, install:
!pip install pytorch_lightning !pip install --pre torch torchvision -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html !pip install ".[gym]"
You can check the detailed-installation process here and usage of ReAgent is discussed here.
To know more about ReAgent Serving Platform(RASP), you can check this documentation.
Demo – Reinforcement Learning on CartPole Problem
This demo explains the usage of ReAgent on CartPole reinforcement learning. The code below uses the OpenAI Gym environment.
- Import all the required modules and packages.
from reagent.gym.envs.gym import Gym import pandas as pd from matplotlib import pyplot as plt import seaborn as sns import numpy as np import torch import torch.nn.functional as F import tqdm.autonotebook as tqdm
- Define the environment by passing CartPole to the Gym class.
env = Gym('CartPole-v0')
def reset_env(env, seed):
np.random.seed(seed)
env.seed(seed)
env.action_space.seed(seed)
torch.manual_seed(seed)
env.reset()
reset_env(env, seed=0)
- Next, is to create a policy which contains a simple scorer or Multilayer perceptron network and softmax sampler.
from reagent.net_builder.discrete_dqn.fully_connected import FullyConnected from reagent.gym.utils import build_normalizer norm = build_normalizer(env) net_builder = FullyConnected(sizes=[8], activations=["linear"]) cartpole_scorer = net_builder.build_q_network( state_feature_config=None, state_normalization_data=norm['state'], output_dim=len(norm['action'].dense_normalization_parameters))
The idea behind the policy is that agents will simply execute this cart pole environment.
from reagent.gym.policies.policy import Policy from reagent.gym.policies.samplers.discrete_sampler import SoftmaxActionSampler from reagent.gym.agents.agent import Agent policy = Policy(scorer=cartpole_scorer, sampler=SoftmaxActionSampler()) agent = Agent.create_for_env(env, policy)
- Now, create a trainer that takes reinforcement learning algorithms to train. The following trainer can be created from the commands below:
from reagent.training.reinforce import ( Reinforce, ReinforceParams ) from reagent.optimizer.union import classes trainer = Reinforce(policy, ReinforceParams( gamma=0.99, optimizer=classes['Adam'](lr=5e-3, weight_decay=1e-3) ))
- After creating a Trainer, start the training of the model by creating a function that changes the observed transitions into a training batch and then evaluating the reward for all episodes via RL interaction loop. The code for it is shown below:
import reagent.types as rlt def to_train_batch(trajectory): return rlt.PolicyGradientInput( state=rlt.FeatureData(torch.from_numpy(np.stack(trajectory.observation)).float()), action=F.one_hot(torch.from_numpy(np.stack(trajectory.action)), 2), reward=torch.tensor(trajectory.reward), log_prob=torch.tensor(trajectory.log_prob) )
Run agent on the environment and record the rewards.
from reagent.gym.runners.gymrunner import evaluate_for_n_episodes eval_rewards = evaluate_for_n_episodes(100, env, agent, 500, num_processes=20) Start the loop num_episodes = 200 reward_min = 20 max_steps = 200 reward_decay = 0.8 train_rewards = [] running_reward = reward_min from reagent.gym.runners.gymrunner import run_episode with tqdm.trange(num_episodes, unit=" epoch") as t: for i in t: trajectory = run_episode(env, agent, max_steps=max_steps, mdp_id=i) batch = to_train_batch(trajectory) trainer.train(batch) ep_reward = trajectory.calculate_cumulative_reward(1.0) running_reward *= reward_decay running_reward += (1 - reward_decay) * ep_reward train_rewards.append(ep_reward) t.set_postfix(reward=running_reward)
- Finally, print all the rewards on each training episode in a form of the graph as shown below.

Conclusion
In this write-up, we have discussed ReAgent Platform aka Horizon and its demo with an example of CartPole Problem with reinforcement learning.
Note : The codes mentioned above are not suitable for colab, due to some dependency issues. The following is the Jupyter Notebook file, to reproduce the above experiment.
Official Codes, Docs & Tutorials are available at:


















