



Federated learning can be considered as an environment where machine learning models and projects learn about the data. Speech emotion recognition is a task that can be used to recognize the emotion type using human speech as data. In this article, we will discuss why and how federated learning for speech emotion recognition is useful and a better option than the other type of learning. The major points to be discussed in part one of the article are listed below.
Table of Contents
- Introduction to federated learning
- What is speech emotion recognition?
- Federated learning for speech emotion recognition
- System architecture
Introduction to federated learning
In the field of machine learning, federated learning can be considered as an approach to make algorithms learned using multiple decentralized devices and data samples. Because of the nature of learning from a decentralized environment, we can also call federated learning collaborative learning. One of the major features of federated learning is that it enables us to use common machine learning without sharing the data in a robust mechanism. This feature also enhances data security and data privacy.
Since there is always a need for data privacy and data security in the fields like defence, telecommunications, IoT, and pharmaceutics, this machine learning technique is emerging very rapidly. This learning aims at training machine learning algorithms using the data which is located at different locations without exchanging it with each other. We can think of this learning machine as a process training model by exchanging the parameters in different locations without exchanging the data.
The main difference between distributed learning and federated learning is that federated learning aims at learning using heterogeneous data while distributed learning aims at training the models at parallelizing computing settings. We can categorize federated learning into the following three categories:
- Centralized federated learning: In this type of federated learning, coordination between different data centres during the learning period of the model is done by a centralized server. Also, this server is responsible for orchestrating the different steps of the algorithms.
- Decentralized federated learning: in this type of federated learning, we make different data centres to be capable of coordinating themselves to obtain the global model. This setting aims to prevent single point failure as any updates in the model are exchanged only between connected data centres without the orchestration of the central server.
- Heterogeneous federated learning: In this type of federated learning, using the dynamical computation on non-iid data we try to train heterogeneous local models while producing a high-performing global inference model.
In this article, we aim to understand how and why we should use Federated learning for speech emotion recognition. More information about federated learning can be found here. In this article, our motive is to find why we should follow the federated learning for speech emotion recognition, so in the next section of the article, we will discuss the introduction to speech emotion recognition.
What is speech emotion recognition?
For humans, speech is one of the ways to express themselves. There is nothing new for a human to define emotion using speech. Making a machine to understand the emotions of speech can be considered as the speech emotion recognition in machine learning. Talking about the most common features using which a machine can understand the emotions behind the speeches are:
- Lexical features(the vocabulary used)
- Visual features (the expressions the speaker makes)
- acoustic features (sound properties like pitch, tone, jitter, etc.)
If a machine is capable of analyzing any or more of the above-given features it can easily perform speech emotion recognition. Using the lexical features for speech emotion recognition will simply require a transcript of the speech which can be extracted from the speech using technologies like text extraction from speech. Using the visual features will require a video of the conversation where speech has been given.
At last, the acoustic features can also be used for speech emotion recognition. One of the most important points about analyzing speech using the acoustic feature is that we are not required to transform the data in any other format and this is why we can perform it easily in real-time when the speech or conversation is taking place. After analysis of the audio data we are required to represent the emotion of the speech that can be done in two ways:
- Discrete classification: Classifying emotions in discrete labels like anger, happiness, boredom, etc.
- Dimensional Representation: Using the dimensions such as low to large scale as activation, active to passive scale as dominance for representing the emotions.
So if we are choosing to analyze the audio data using the acoustic features we can utilize the following features of audio data or speech data:
- MFCC (Mel Frequency Cepstral Coefficients)
- Mel Spectrogram
- Chroma
The choice of any of the features from audio data depends on our flexibility. Since there are various projects in which we can find the use of MFCC we can utilize them. Talking About the Mel spectrogram these are plots that include frequency and time in the graph that can be used in frequency analysis and plotting the amplitude of audio on the Mel we can make the frequency as perceived frequency.
In the above section, we have discussed what are the features and labeling methods that can be used for speech emotion recognition. We can take an idea of a solution pipeline for speech emotion recognition from the below image.

By looking at the above image we can say that the project flow starts with taking a raw audio file as an input that is next passing through the feature extraction block where one or more features from the above-given feature are extracted. After extraction and preprocessing in feature extraction block dimensionally redacted audio file goes through the model block where we can use various ML algorithms like SVM, XGB, CNN-1D(Shallow), and CNN-1D on our 1D data frame and CNN-2D on our 2D-tensor to recognize and classify the emotion of the speech.
There are various speech emotion recognition projects available which are mainly using the following open-source audio data:
- Toronto emotional speech set (TESS)
- SAVEE (Surrey Audio-Visual Expressed Emotion)
- Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS)
- CREMA-D is an audio-visual data set for emotion recognition
We can freely use this dataset for our speech emotion recognition dataset. Till now in this article we have seen what federated learning is, what is speech emotion recognition and how can we manage to perform it using audio files. In conclusion, we can say that federated learning is a way to perform collaborative machine learning, and speech emotion recognition is a process of classifying the audio or speech data in the context of emotion. In the next section of the article, we will discuss why we use federated learning in speech emotion recognition.
Federated learning for speech emotion recognition
By looking at the above portions of the article we can say that speech emotion recognition (SER) is a rapidly emerging area of machine learning projects and research. When using a perfect system we can recognize human emotion using machines. We can understand that speech data is also one of the most confidential data and transferring speech data from end devices to the models and any other devices requires a lot of security.
Using speech data we can extract a lot of information about speakers like age, identity, language, and gender, Which can be a confidential part. In the federated learning part of the article, we were more focused on the data privacy part. By understanding federated learning we can say that a federated learning environment can provide great control over user data privacy and also high-performance modelling experience. If performing modelling in such an environment it can be incorporating privacy with distributed training and aggregation across a population of client devices.
We can find out many projects on the SER where the performance of the system is quite appreciable but when considering the data privacy we can not expect this from them. For which we are required to have environments like federated learning. We can utilize federated learning for speech emotion recognition. For example, we can train CNN and RNN classifiers in federated learning and can activate a high-performance level.
System architecture
In this section of the article, we will discuss a proposed system architecture that can utilize the federated learning environment for speech emotion architecture. Using this link, we can find out an architecture for the motive of the article. The below image is a representation of the system architecture of federated learning in a distributed network of clients with SER applications.
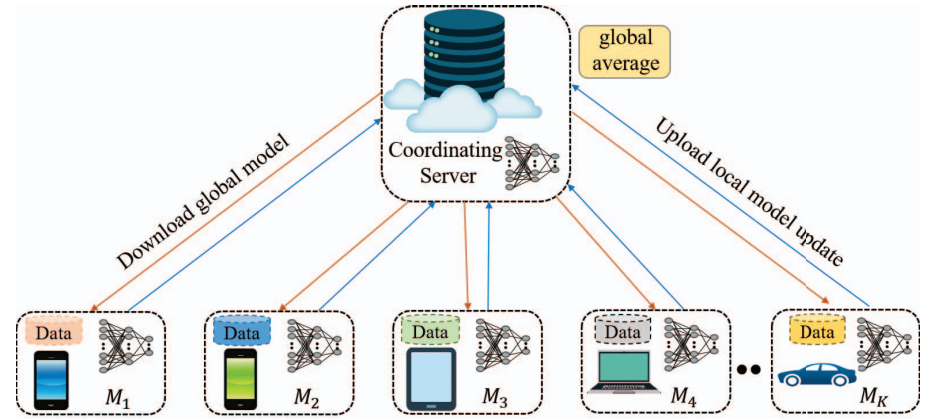
(Source)
This architecture is based on the heterogeneous federated learning for SER. in such an architecture a client or data centre can be any device and computation on the data doesn’t require sharing the data with the main server. In a three-step protocol, we can perform this collaborative learning as,
- All the data centres or clients or devices require to download the model and its updates that are available on the main server.
- The downloaded model is used by participants to compute the local data.
- Updated weights from all the devices are uploaded on the main server where aggregation of these uploads updates the global model in the main server.
Repetition of these protocols makes the model reach the convergence of certain criteria. In the case of SER, this architecture is useful because the client needs only to share updated weights with the main server instead of speech data which reduces the chances of data leakage. Since every client is producing weights they can also participate in approximating the global objective function and stochastic gradient descent can be used for the optimization of aggregated weights.
Final words
In this article, we have discussed federated learning and speech emotion recognition. Along with that, we have discussed why we should use speech emotion recognition in a federated learning environment. We also discussed the architecture which can be used in federated learning for speech emotion recognition.















































































