



In natural language processing, we see various types of modelling that enable applications to interact with human language. In the recent scenario, we have seen the importance of this modelling in various fields. Topic modelling is also a part of NLP that is used for abstracting topics from a set of different documents and there is various research and work has been done in topic modelling. Top2Vec is also an approach or algorithm for performing topic modelling. In this article, we are going to discuss topic modelling and the Top2Vec algorithm for topic modelling. The major points to be discussed in the article are listed below.
Table of content
- About topic modelling
- Algorithms for topic modelling
- What is Top2Vec?
- Working procedure of Top2Vec model
- Step 1: Generation of embedding vectors and words
- Step 2: Perform reduction in the dimensions of embedding vectors
- Step 3: Perform clustering on reduced vectors
- Step 4: Calculation of centroids of the clusters
- Step 5: Topic assignment to the words
Let’s first understand what topic modelling is.
About topic modelling
Topic modelling is a type of process in natural language processing that deals with the discovery of semantic structure presentation in text documents. We can also compare this modelling with statistical modelling that comes into the picture when there is a need of discovering the abstract topics that occur in the text data. For example in an article, there are words like data science and data analytics then the article will be about data science.
There is a possibility that the article is 60% focused on data science and 40% of the content is about cloud services. Then we can think of it as possessing 1.5 times more data science words than the cloud services words.
Algorithmically we can think of this process as a clustering process where modelling makes the cluster of similar words. This is similar to the other NLP modelling because it also uses a mathematical framework to capture the intuition behind the documents, with the help of the mathematical framework the algorithms examine the documents and discover the topics because in the mathematical framework there is an availability of statistics of the words.
We can also think of topic modelling as a type of probabilistic modelling because the probability is used for discovering the latent semantic structures of a document. In most projects, this modelling can be considered a text-mining tool.

The above image is a representation of the discovery process using a document word matrix, in the image we can see that the columns are representing the document and rows are representing the word.
In the matrix, the cell is used to store the frequency of the word in the document and the intensity of the colour is representing the frequency. Using topic modelling we can make groups of documents that are using similar words and words that have occurred in a similar set of documents. The final result represents the topics.
Are you looking for a complete repository of Python libraries used in data science, check out here.
Algorithms for topic modelling
This type of modelling has been a part of many kinds of research since 1998 when the first time it was explained by Papadimitriou, Raghavan, Tamaki, and Vempala and they called it probabilistic latent semantic analysis(PLSA). LDA (latent Dirichlet allocation) is the most used algorithm for topic modelling.
In a variety of techniques we can see the inclusion of the SVD (singular value decomposition) method and in some of the other techniques usage of the non-negative matrix factorization method can be seen. In recent years when graphs are introduced implementation of the stochastic block model can also be seen.
In this article, we are going to discuss one such technique named as Top2Vec that has represented a potential outcome level in the topic modelling that uses vectors and clustering to complete its work. Let’s introduce the Top2Vec model.
What is Top2Vec?
Top2Vec can be considered as an algorithm for performing topic modelling in a very easy way. We can also say it is a transformer for performing topic modelling. It is not only limited to the topic modelling but can also be used for semantic relation searches in documents. Using this algorithm we can automatically recognize the topic under a text document and this algorithm generates jointly embedded topic, document, and word vectors.
Below we can see the important usage of Top2Vec:
- Obtaining the number of detected documents
- Get content and size of the topics
- Finding the hierarchy in topics
- Using keywords to search topics
- Using topics to search document
- Using keywords to search documents
- Finding similar words
- Finding the same documents.
Atomic features are one thing that’s very important about this algorithm and it also has functions that can work with both long and short text. We can install this algorithm using the following lines of codes.
!pip install top2vec
Its implementation can be found here. In this article, we will take a look at how it works.
Topic modelling with Top2Vec
In the above, we have talked about what can be done using Top2Vec and to perform these tasks the following step is used:
- Generation of embedding vectors and words
- Perform reduction in the dimensions of embedding vectors
- Perform clustering on reduced vectors
- Calculation of centroids of the clusters
- Topic assignment to the words
Let’s explain all the steps one by one.
Step 1: Generation of embedding vectors and words
This step includes the generation of embedding vectors that allows us to represent the text document in the mathematical framework. This framework can be multi-dimensional where the dimension depends on the word or text document. This can be performed using Doc2Vec or Universal Sentence Encoder or BERT Sentence Transformer.
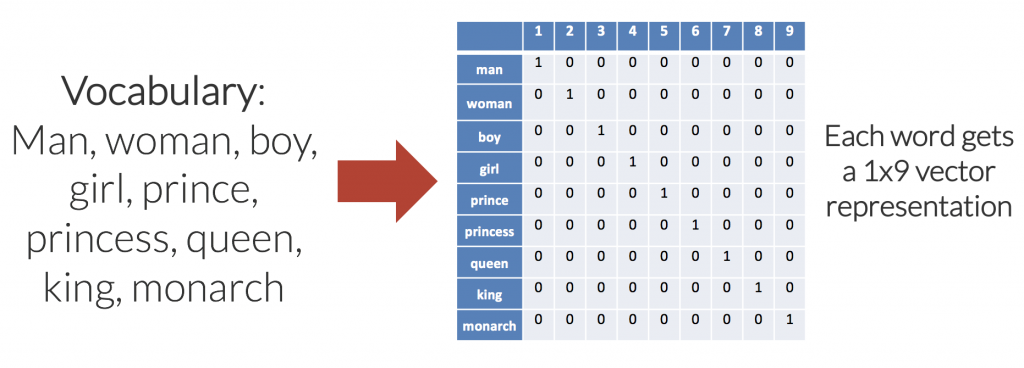
The above image is a representation of the general word vector using the one-hot word embedding system.
Step 2: Perform reduction in the dimensions of embedding vectors
In this step, the generated high dimensional document vectors from the vectors get reduced in their size. This is a basic dimension reduction process and Top2Vec uses the UMAP dimension reduction technique; this one allows the next steps to find a dense area for clustering.

The above image represents the word vectors under the documents and we can see that they are dense and can be separated into groups.
Step 3: Perform clustering on reduced vectors
This step divides the dimensionally reduced vectors into different groups using the HDBSCAN clustering technique. This step can give us an approximation of the numbers of the topic in the documents.

The above image is the representation of step 3 where colours are used to separate the vectors of different groups.
Step 4: Calculation of centroids of the clusters
This step can be considered as our start of topic modelling where we calculate the centroid of every dense area of the clusters from step 3 and the final vectors we get from this vector can be called our topic vector.
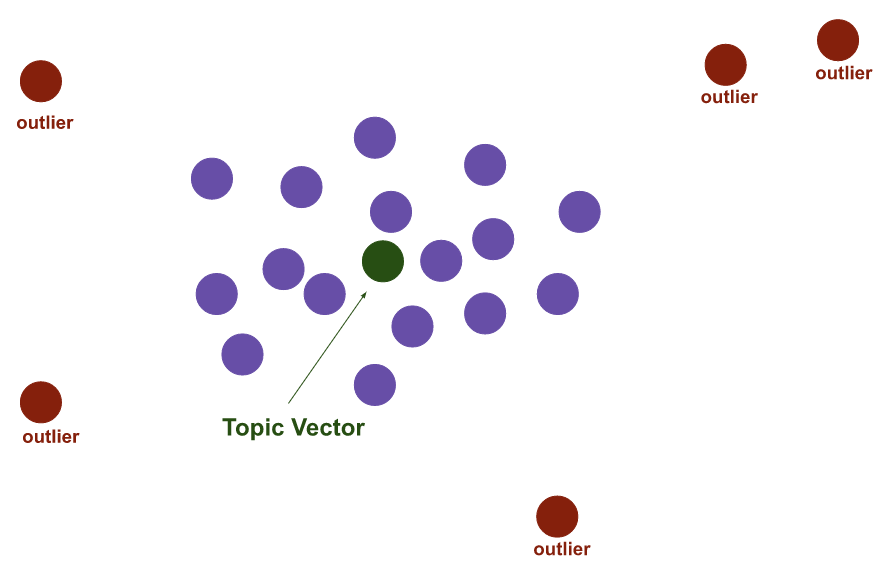
In the above image we can see there are three kinds of dots and the red one is sparse and far from the other dots so they can be considered outlier documents using the blue dots that are dense. The algorithm calculates the topic vector.
Step 5: Topic assignment to the words
This step is the final step of Top2Vec, where it finds the n-closest word vectors and feeds them to the topic vector so that they can become topic words. The below image is the representation of the final step.

Here we can see how the Top2Vec finally gives us the result of topic modelling. We can find its implementation on GitHub here.
Final words
In this article, we have discussed the topic modelling which is a part of natural language processing and the Top2Vec algorithm. We can use the Top2Vec algorithm to perform topic modelling. The implementation I have mentioned above can be utilised to perform Top2Vec.














































































