



Last month, OpenAI unveiled a new programming language called Triton 1.0 which enables researchers with no CUDA experience to write highly efficient GPU code.
GPU programming is complicated.”Although a variety of systems have recently emerged to make this process easier, we have found them to be either too verbose, lack flexibility or generate code noticeably slower than our hand-tuned baselines,” according to OpenAI’s blog post.
CUDA vs Triton
In this article, we explore the key differences between OpenAI Triton and NVIDIA CUDA. But, before that, let’s take a look at the basic architecture of a GPU, as shown in the image below.
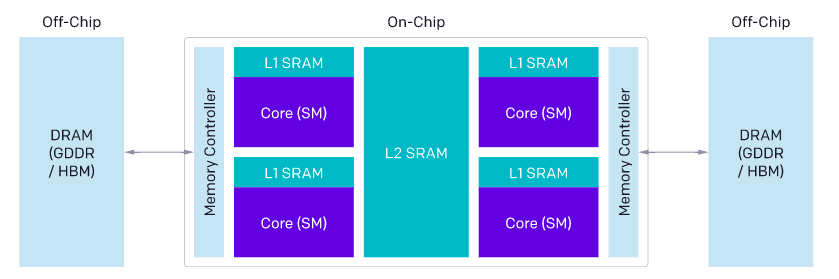
The architecture of GPU (Source: OpenAI)
Modern GPUs constitute three major components: DRAM, SRAM and ALUs — each of which must be considered when optimising CUDA code:
- Memory transfer from DRAM must be fused into large transactions to leverage the large bus width of modern memory interfaces.
- Data is manually uploaded to SRAM before being re-used and managed to minimise shared memory bank conflicts upon retrieval.
- Computations must be partitioned and scheduled carefully, both across and within streaming multiprocessors (SMs), to promote instruction/thread-level parallelism and leverage special-purpose ALUs (Tensor Cores)
“Reasoning about all these factors can be challenging, even for seasoned CUDA programmers with many years of experience,” according to the OpenAI blog. However, Triton has automated such optimisations so that developers can focus on the high-level logic of their parallel code.
Triton does not automatically schedule work across SMs, leaving important algorithmic considerations to developers’ discretion. Algorithmic considerations may include tiling, inter-AM synchronisation, etc.

CUDA
Released in 2007, CUDA is available on all NVIDIA GPUs as its proprietary GPU computing platform. It includes third-party libraries and integrations, the directive-based OpenACC compiler, and the CUDA C/C++ programming language.
Today, five of the ten fastest supercomputers use NVIDIA GPUs, and nine out of ten are highly energy-efficient. CUDA is implemented in its device driver, but the compiler (nvcc) and libraries are packaged in the CUDA toolkit and software development toolkit (SDK). It contains many use cases and libraries, along with NVIDIA Nsight, an extension for Microsoft Visual Studio, and Eclipse (for Linux) for interactive GPU profiling and debugging.
NVIDIA Nsight offers code highlighting, a unified GPU and CPU trace of the application, and automatic identification of GPU bottlenecks. NVIDIA Visual Profiler is a standalone cross-platform application for profiling CUDA programs, and CUDA versions for debugging and memory checking also exist.
How is Triton different from CUDA?
In 2019, Harvard researchers, in a paper titled Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations, laid out the differences between CUDA and the Triton programming model.
The execution of CUDA code on GPUs is supported by an SPMD programming model, where each kernel is associated with an identifiable thread block in a launch grid. The Triton programming model works the same way, but each kernel is single-threaded (though automatically parallelised) and associated with a set of global ranges that varies from instance to instance.
The approach leads to simpler kernels in which CUDA-like concurrency primitives are nonexistent. The concurrency primitives include shared memory synchronisation, inter-thread communication, etc.
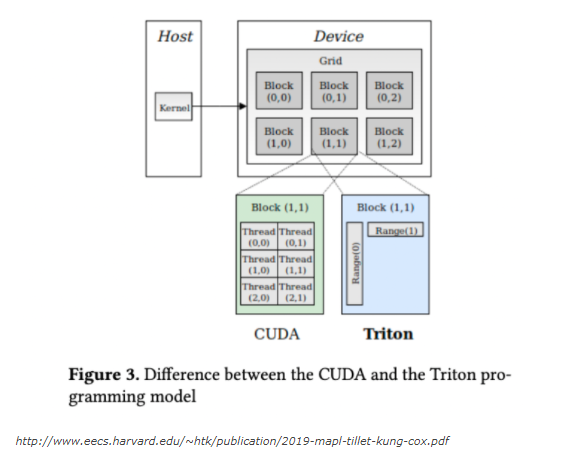
Triton is similar to Numba, an open-source JIT compiler that translates a subset of Python and NumPy into fast machine code. In Numba, kernels are defined as decorated Python functions and launched concurrently with different instances.
Wrapping up
Deep Learning research ideas are typically implemented leveraging a combination of native framework operators. However, this approach requires many temporary tensors, which can put a damper on the performance of neural networks at scale. Specialized GPU kernels can take care of such issues. But it’s difficult to manage owing to the complexities of GPU programming.
Triton automatically optimises specialised kernels and converts them into a code for execution on NVIDIA GPUs. The compiler currently uses block-level data-flow analysis, a technique used for scheduling iteration-block statically based on the control-and data-flow structure of the target programme, to solve the challenge of scheduling.







































































