



In machine learning or deep learning, when we see at the ground level of an algorithm to make the decision or to make the decision accurate, we find the use of mathematics. We can say that machine learning and mathematics are correlated with each other. Various concepts of mathematics are being used for optimizing the algorithms of deep learning and machine learning. The Taylor series is one of the concepts from mathematics that is widely used in the field of machine learning. In this article, we are going to discuss the Taylor series and its uses mainly in deep learning. The Major points to be discussed in this article are listed below.
Table of Contents
- What is the Taylor series?
- Why Do We Use The Taylor series?
- Taylor Series in Machine Learning
- Taylor Series in Deep Learning
- Use cases of the Taylor Series in Deep Learning
Let’s start the discussion by understanding what the Taylor series is.
What is The Taylor Series?
In mathematics, the Taylor series can be considered as a series expansion of a function about a single point. Expansion of any function is an infinite sum of terms of the function’s derivative about any single point. If the derivatives are considered at zero the Taylor series becomes the Maclaurin series.
The Taylor polynomial of the function is a polynomial of degree n where n+1 terms of the Taylor series form the partial sum. Taylor polynomials can also be considered as an approximation of a function where, generally, as the n increases, the approximation becomes better.
Whenever an approximation is done, it introduces an error and the Taylor theorem helps in providing quantitative estimates on the errors. Mathematically, the Taylor series for any function F(x) can be given by:
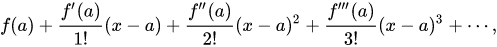
Where,
f(x) is infinitely differentiable,
a is some point where a function needs to be approximated.
The above series can also be represented by a compact sigma formulation, like:

Where,
n! = factorial of n.
f(n)(a) = nth derivative of f evaluated at the point a.
When a = 0, the series becomes the Maclaurin series.
Here we had a basic introduction to the Tyler series. Let’s discuss the uses of the Tyler series.
Why Do We Use the Taylor Series?
Below are some examples where we use the Taylor series:-
- We have already discussed that it can be used as an approximation of a function, by including many sufficient terms. Taylor polynomials of the series can be used as an approximation of the functions.
- We can perform term by term differentiation and integration very easily.
- By extending the analytics function to a holomorphic function on an interval in the complex plane, we can make the machinery of complex analysis available.
- Often by casting and evaluating the polynomial into Chebyshev form we can use the series to compute the function value numerically.
- Mostly in physics, we use the Tyler series to make unsolvable problems possible by using the first few terms from the series.
We have gone through some of the uses of the Taylor series in different fields. Mainly we found that using the Taylor series, we can perform the approximation of any function. Machine learning procedure can be assumed as the combination of many mathematical functions. Let’s see why we need the Taylor series in machine learning.
Taylor Series in Machine Learning
As we’ve discussed, the machine learning procedure can be assumed as the combination of many mathematical functions. Let’s take an example of the cost function in machine learning which is mainly used to measure the amount of error in the description of data and cost optimization can be considered as the procedure of reducing the wrongness in data description as much as possible.
We can say that the Taylor series is a tool to find the minima in the cost function of any machine learning procedure. However, by differentiating the cost function, we can find out the minima of the cost function but not all the functions can be differentiated. Let’s consider the below graph of a function,

The above function is very easy and anyone can think that the global minimum of the function is at zero. But if the function is more complex, let’s consider the below image.

Talking about the first function, we can easily understand where the minima of the function exist by just visualizing it. But in the second function, we can find some difficulties in finding the point where we can obtain the minimum value from the function. Using the Taylor series we can differentiate and approximate the point where the function will be at the point we care about. Talking about the cost function, it should be at a minimum.
So here we have an intuition about why we need the Taylor series in the machine learning procedure. Deep learning is also a part of machine learning and in the next section, we will see why we need the Taylor function in deep learning in detail.
Taylor Series in Deep Learning
In deep learning as well, many of the functions require to be approximated to acquire good results from the procedure. Let’s take an example of the convolutional neural network wherein the blocks use various rectifiers and pooling operations like max pooling. In most of the cases related to CNN, we see that the rectifiers and pooling functions are neither smooth nor convex. In such scenarios, we mostly find use of gradient descent and adam optimization techniques are being used as building blocks for deep learning algorithms. We can also use the Taylor series as an optimization function in the deep learning procedure.
We can also apply the Taylor series expansion to any function of the neural network since the Taylor series expansion of any continuous function reveals many of the characteristics of the function. Talking about the neural networks where various functions are applied together, applying the Taylor expansion on these functions such as the performance function can reveal new insights into the working of neural networks.
In most of the cases, we see that the performance measure of the deep learning networks can be expressed as the objective function to be optimized or the deep learning networks output functions, and the parameters of the functions are weighted, input activation, and output activation. The Taylor series expansion can be applied to this performance measure and enables us to study the details of the objective and output function of the deep neural network.
Applying Taylor expansion to the objective function of the deep neural network is one of the most important uses of Taylor expansion in deep learning. In most cases, sum squared error is being used as the objective function.
Let’s say that E is an objective function of any neural network with 𝛳 = (θ1…., θi ) parameter vector of the neural networks. ∆θi is a perturbation of any parameter then the Taylor series expansion of the E will be,
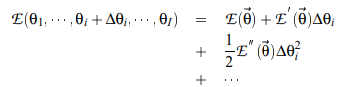
And the change in the error due to perturbation will be,

From the change in error, the first-order error can be used with gradient descent optimization which can lead the neural network to the local minima. The second-order term can be used in optimization to improve the convergence in neural networks.
The same procedure can be applied to any function of the deep neural network and after analyzing the sensitivity of the function we can apply the pruning of the deep neural networks. In many pieces of research, we find the suggestion of applying the pruning after convergence is reached. At the minimum of any function, the derivative of the function becomes approximately zero so we can remove the first term from the change in the error.
Use cases of Taylor series in deep learning
In the above, we have seen an example of applying the Taylor series in deep learning. There are various use cases of the Taylor series in deep learning which can be used to improve and optimize the performance of the deep learning algorithm. Some of the uses of the Taylor series in neural networks are as follows:
- Taylor approximation can be applied to isolate the difficulties like shattered gradients, in the training of neural networks.
- Tylor expansion and approximation can be used for investigating the hypothesis that adaptive optimizers converge to better solutions.
- Taylor’s composition can be used for explaining the prediction from neural networks in a quantitative way.
- As we have already discussed that we can improve the performance of neural networks by studying the performance function, the characteristics of the performance function can be revealed using the Taylor series expansion.
Final words
In this article, we have got a basic understanding of the Taylor series and we have discussed the need for the Taylor series in machine learning and different other fields. Along with this, we have also discussed the uses and requirements of the Taylor series in deep learning using an example of applying Taylor series expansion on the performance and objective function of any neural network.

















