



So far, in measuring the performance of generative networks, metrics like Fréchet Inception Distance (FID) have been popular with the evaluation of GANs. However, these metrics sometimes fail to distinguish between different failure cases owing to their one-dimensional scores.
FID compares the statistics of generated samples to real samples, instead of evaluating generated samples in a vacuum.
In order to maintain consistency in the quality of the images that are generated, Frechet Inception Distance (FID) is used. Lower the FID, the better the quality. Where FID falls short, traditional Precision and Recall have proved to be useful.
Contrary to methods like Inception Score and FID, the topological approach also came in handy as it does not use auxiliary networks and is not limited to visual data.
To rectify the errors surfacing in GAN generator distribution, a rejection sampling-based method was also introduced. The idea behind this method is to improve the quality of trained generators by post-processing their samples using information from the trained discriminator.
Whereas, in the case of the Annealed Importance Sampling approach, the log-likelihood for decoder-based models are evaluated and the accuracy is validated using bidirectional Monte Carlo.
However, these metrics have some limitations. For instance, widely popular FID has two limitations: it requires a trained and a target dataset. This means it is sensitive to new dataset applications and to the size of the dataset.
In a paper, under review for ICLR 2020, the authors define the goodness of fit measure for generative networks which captures how well the network can generate the training data, which is necessary to learn the true data distribution.
A novel way to perform model comparison and early stopping without having to access another trained model as with Frechet Inception Distance or Inception Score.
Finding The Right Fit

A current limitation of metrics for GANs is their dependence on another pre trained deep neural network model. This poses limits as to what dataset GANs can be evaluated on, as well as any internal bias induced by the different models used.
The metric that has been introduced in this new approach is given as follows:
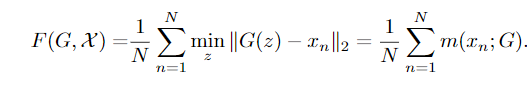
where F is an empirical average least square distance between reference points, the observed input, and Imag(G); image of the generator.
The lack of memoriation in current generative networks is evident when generators experience mode collapse. Mode collapse translates into the absence of approximation of the generator to some parts of the target distribution.
In order to show that this estimate has low variance, the authors bootstrapped the distance calculations to calculate the standard error.
To assess their measures, the authors trained WGAN and DCGAN from their git repositories in order to reproduce their networks. And, to their surprise found that WGAN does not memorise because of the diversity of its generated images. This implies that even though a generator can produce a wide spectrum of images, it can not reproduce the training data.
The main objective of this study is to demonstrate the role of optimal latent space distribution in minimising the error of a trained GAN and how errors are mainly due to under parametrised GANs.
The key takeaways of this study can be summarised as follows:
- Formulated a metric to provide implementation details on computing efficiently.
- Demonstrated how this metric compares to standard Frechet score.
- Demonstrated how this goodness of fit metric allows to gain novel insights into GANs.
- Provided solutions to reduce the approximation error without altering training stability.
- Demonstrated that many errors are due to under parameterised GANs.
Maintaining A Grip On GANs
There are other novel approaches that have shown promising results. For instance, Google Brain introduced Tournament Based method where a tournament is conducted where a single model is rated by playing against past and future versions of itself. This helped to monitor the training process of GANs. And these measurements are classified into two ratings: win rate and skill rating.
The tournament win rate denotes the average rate at which a generator network fools the discriminator network. Whereas, a skill rating system, as its name suggests gives a skill rating for each generator.
The problem of estimating the quality and diversity of the generated images can also be tested by going through the topology of the underlying manifold of generated samples may be different from the topology of the original data manifold, which provides insight into properties of GANs and can be used for hyperparameter tuning.
These approaches are necessary as they provide novel goodness of fit measure for generative networks and pave the way to discover better conditions for optimal usage of generative networks since comparing models by inspecting samples is labour-intensive and potentially misleading.















































































