



Companies collect large amounts of personal data to develop products based on machine learning. Machine learning models encode information that is supposed to reflect a wide range of patterns that underlie demographic data. To use the machine learning model safely, it is important to quantitatively assess your privacy concerns and ensure that you do not disclose sensitive information about your training data. In this article, we will use the ML Privacy meter to demonstrate attacks on data privacy and analyze these attacks. Following are the topics to be covered.
Table of contents
- What is a privacy attack?
- What are the different types of attacks?
- How do mitigate these attacks?
- Using ML Privacy meter for attacks
Let’s start by talking about privacy attacks on machine learning models.
What is a privacy attack?
The attack on machine learning algorithms either to collect the data used for training purposes and release sensitive information to the surface web or to know about the learner itself, in any way it is considered as a privacy attack on learners. For example, Consider you had major heart surgery and doctors have implanted a heart pacemaker.
This data is stored and utilized for different analysis and training purposes. Now the attacker has your name and other demographic descriptions that are required to know whether you had surgery. After the attack is successful, the attacker has all your biological information and also could monitor your heart pacemaker.
To understand and fight against machine learning threats from a privacy standpoint, it is helpful to establish a broad model of the environment, the many players, and the assets to protect. From the standpoint of a threat model, the actors indicated in this danger model are:
- The proprietors of data, whose information may be sensitive.
- The owners of the models may or may not own the data, and they may or may not choose to share information about their models.
- Model consumers use the services exposed by the model owner, often through some form of programming or user interface.
- Adversaries may also have access to the model’s APIs in the same way that a typical consumer does. They may have access to the model itself if the model owner permits it.
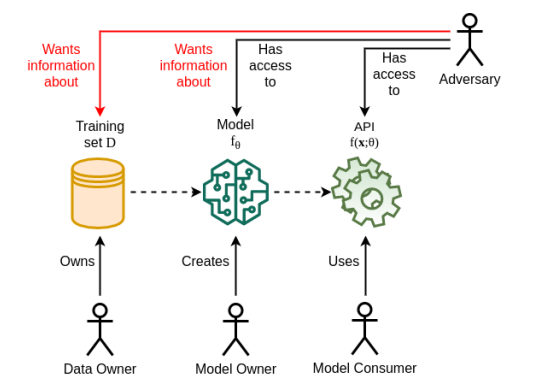
The figure above shows the actors identified as assets under the threat model, as well as the flow of information and possible actions. This threat model is logical and does not rule out the possibility that some of these assets may be integrated or distributed across multiple locations.
The different attack surfaces against machine learning models can be modelled in terms of adversarial knowledge. The range of knowledge varies from limited, e.g., having access to a machine learning API, to knowing the full model parameters and training settings. In between these two extremes, there is a range of possibilities such as partial knowledge of the model architecture, its hyper-parameters, or training setup.
The knowledge of the adversary can also be considered from a dataset point of view. In the majority of the papers reviewed, the authors assume that the adversaries do not know the training data samples, but they may have some knowledge of the underlying data distribution. Based on adversarial knowledge there are two classifications.
- Black-box attacks are those in which the attacker does not know the model parameters, architecture, or training data.
- White-box assaults occur when the adversary gets full access to the target model’s parameters or loss gradients during training. Although some sort of preparation may be necessary, the majority of the works presume complete knowledge of the expected input.
Let’s deep dive into privacy and understand different types of attacks on machine learning algorithms and data sets.
What are the different types of attacks?
The goal of the opponent is to acquire knowledge that should not be shared. Such knowledge may be related to training data or information about the model, or it may be related to extracting information about the properties of the data, such as unintentionally encoded bias. These attacks can be divided into four main categories.
Membership Inference Attacks (MIA)
Membership inference refers to the problem of determining if a data point, given it, is included in the training set.
MIA can directly infringe privacy if its presence in a training set is sensitive in and of itself due to the nature of the work at hand. For example, if photos from a criminal database are used to train a model predicting the likelihood of re-offending, effective membership inference reveals that individual’s criminal past.
When an opponent has complete knowledge of a record, understanding that it was used to train a certain model is an indicator of information leaking through the model. Overall, MIA is frequently regarded as a signal—a type of yardstick—that access to a model leads to potentially major privacy violations.
On the other hand, the MIA can also be used by regulatory agencies to support suspicions that models have been trained with personal data without proper legal grounds or for purposes that are incompatible with data collection. For example, DeepMind was recently found to be using personal medical records provided by the United Kingdom National Health Service for purposes other than direct patient care. Evidence for which the data was collected.
Model Inversion
Given some access (either black-box or white-box) to a model, model inversion approaches attempt to deduce class characteristics and/or generate class representations.
In these techniques, the derived functions characterize the entire class, except in the case of pathological overfitting where the training sample represents the entire membership of the class, even if the training data is not particularly characterized. May be described as infringing on your privacy.
An attacker, for example, can depend on classifier outputs to deduce sensitive information used as inputs to the model itself. An attacker could guess sensitive patient features based on the model and certain demographic information about a patient whose records are utilized for training. Then, using “hillclimbing” on the output probabilities of a computer-vision classifier, they uncover individual faces from the training data.
Property Inference
The capacity to extract dataset attributes that were not explicitly encoded as features or that were unrelated to the learning goal. These features may also be utilized to get further insight into the training data, which can lead to adversaries exploiting this knowledge to develop similar models or have security consequences when the learned attribute can be used to discover system weaknesses. Even well-generalized models may learn traits relevant to the whole input data distribution, which is sometimes inevitable or even required for the learning process.
An example of property inference is to extract the male / female ratio information in a patient record if it is not a coded attribute or record label. Or a neural network that can perform gender classification and infer whether people in the training dataset are wearing glasses. In some environments, these types of leaks can affect your privacy.
From an adversarial standpoint, what is more, intriguing are qualities that can be deduced from a small subset of training data, or eventually about a specific individual.
Model Extraction Attacks
Model extraction is a type of black-box attack in which the adversary attempts to extract information and perhaps completely rebuild a model by constructing a model that acts extremely similar to the model under attack. For alternative models, there are two primary areas of concentration.
- To build models that match the goal model’s accuracy in a test set taken from the input data distribution and relevant to the learning task.
- To develop a replacement model that fits the under attack model at a collection of input points that are not necessarily linked to the learning goal.
Knowledge of the target model’s architecture is a prerequisite for some attacks, but it is not required if the attacker chooses an alternative model that is as complex or more complex than the model being attacked.
Apart from creating surrogate models, we focused on extracting information from the target model such as hyperparameters of the target function and information on various neural network architecture properties such as activation type, optimization algorithm, number of layers, etc. There is also an approach.
How do mitigate these attacks?
Cryptography, or more specifically encryption, can be used to protect the confidentiality of your data. In the context of ML and general data analysis/processing, two key primitives are involved.
- SMC allows two or more parties to jointly calculate a function over their inputs while keeping those inputs hidden from one another. SMC protocols are often built around technologies such as garbled circuits, secret sharing, and oblivious transmission.
- Fully Homomorphic Encryption (FHE) is an encryption system that permits the processing of the underlying cleartext data while it is still encrypted and without revealing the secret key. To put it another way, FHE enables (nearly) arbitrary computation on encrypted data.
Differential Privacy (DP) tackles the contradiction of learning nothing about a person while gaining relevant information about a population. In general, it gives rigorous, statistical assurances against what an opponent may deduce from understanding the outcome of a randomized process. Individual data subjects’ privacy is often protected by introducing random noise while compiling statistics using differentially private procedures. In other words, DP ensures that an individual faces the same privacy risk whether or not her data is subjected to differentially private analysis.
Using ML Privacy Meter for attacks
For evaluating the privacy of machine learning algorithms we need to install the GitHub repository of ML Privacy Meter.
Once the ML privacy meter is all set up, load the data set and train your learner it could be any learner discriminative or generative. Now you are all set to evaluate the model privacy risk. Before you need to initialize the data handler which will handle the data for the attacks that need to be performed on the machine learner. You can use both with box attack and black box attack by using the ml_privacy_meter attribute “attack”.
It can attack the learner at different stages and levels depending on the learner been used. The difference between both black box and white box attacks has been explained above. That last report could be generated with the help of “test_attack” and below are the plots that can be generated.


(Source)
The left figure depicts a histogram of membership probability for training set member data and population non-member data. A greater membership probability indicates that the model anticipated that the data is part of the training data. The curve for the Receiver Operating Characteristic (ROC) for the membership inference attack is shown on the right. It also displays the plot’s AUC value.
Closing thoughts
As machine learning becomes more widespread, there is growing interest from the scientific community. From the perspective of security, privacy, fairness and accountability, it has its benefits and side effects. To comply with data protection requirements, we must analyze these risks and implement any necessary mitigation steps. With this article, we could understand privacy attacks on machine learning.
















