



CDC 1604 was a second generation 48-bit word size computer that could handle 100,000 operations per second. It was designed to automate the missile control for the US Navy. But trying to run an iPhone on CDC 1604, it would have a hard time rendering a single pixel of your selfie. So your palm-sized phone could have handled multiple missile systems which otherwise would have taken a room-sized computer.
Computer architectures were initially designed to specialise in serial processing and then use up DRAMs to optimise high-density memory. Memory-on-chip area is expensive and adding large amounts of memory will only make things worse. A typical neural network’s memory has to store input data, activations and weight parameters.
In the paper titled Training Deep Neural Networks with 8-bit Floating Point Numbers authors Naigang Wang, Jungwook Choi, Daniel Brand, Chia-Yu Chen, Kailash Gopalakrishnan of IBM Watson Research Centre, introduce novel techniques to successfully train DNNs using 8-bit floating point numbers (FP8) while fully maintaining the accuracy.
“Historically, high-performance computing has relied on high precision 64 and 32-bit floating point arithmetic. This approach delivers accuracy critical for scientific computing tasks like simulating the human heart or calculating space shuttle trajectories,” say the researchers behind this breakthrough.
But, for tasks like image classification or speech recognition, approximation seems to be of more importance than high precision that 64 or 32 bit has to offer.
As we lower the floating point limit, the engines become smaller. For instance, 16-bit precision engines are typically 4 times smaller than comparable blocks with 32-bit precision; this gain in area efficiency directly translates into a significant boost in performance and power efficiency for both AI training and inference workloads.
So, here high precision is being traded for computational enhancements and in this paper, the researchers demonstrate novel training techniques that eventually quicken the compression methods by a factor of 40-200x.
Back in 2015, IBM Research had shown how to fully preserve model accuracy while going from 32 bits to 16 bits.
Now, 16-bit training and 8-bit inference system have been inculcated into the industry as a standard. While works are underway for making 8-bit precision and 4-bit precision for inference, a thing.
The main challenges associated with training networks below 16 bits:
- Is the maintenance of fidelity of the gradient computations and weight updates during back-propagation.
- When weights, errors and gradients used in matrix multiplication are reduced to 8 bits, deep neural networks take a hit and there is a significant degradation in its final accuracy.
- Also, there is a noticeable impact on the convergence during network training.
- 32-bit weight updates, used in today’s systems, require an extra copy of the high-precision weights and gradients to be kept in memory, which is expensive.
How To Work Around An 8-bit FP
A new technique called chunk-based computations, when applied, allows operations like convolution to be computed using 8-bit multiplications and 16-bit additions instead of 16 and 32 bits, respectively. And, a floating point stochastic rounding for the weight updating process.
In chunk-based computations, the accumulated computations are broken up into chunks. These chunks consist of deep learning dot products. Researchers have tested this technique to train ResNet50 model. Many of these techniques have been tested using chips of size 14 nm. The results indicate that chunk-accumulation engines can be used along with reduced-precision dataflow engines without increasing hardware overheads.
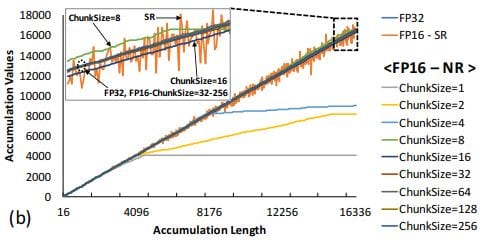
As a baseline, accumulation in FP-32 increases linearly with vector length. A typical FP-16 accumulation with the nearest rounding (i.e., ChunkSize=1) significantly suffers swamping errors (the accumulation stops when length ≥ 4096).
This is where the chunk-based accumulation can be used to compensate for the errors, as the effective length of accumulation is reduced by chunk size to avoid swamping. The effectiveness of the stochastic rounding can be seen below; although there exists a slight deviation at large accumulation length due to the rounding error, stochastic rounding consistently follows the FP-32 result.
This success paves way for a new era of hardware training platforms which perform twice as well as the current systems.
This Paper Introduces:
- A new FP-8 floating point format that, in combination with DNN training insights, allows general matrix multiplication(GEMM) computations for Deep Learning to work without a loss in model accuracy.
- A new technique called chunk-based computations that when applied hierarchically allows all matrix and convolution operations to be computed using only 8-bit multiplications and 16-bit additions (instead of 16 and 32 bits respectively).
- An applied floating point stochastic rounding in the weight update process which allows these updates to happen with 16 bits of precision (instead of 32 bits).
- The wide applicability of the combined effects of these techniques across a suite of Deep Learning models and datasets – while fully preserving model accuracy.
Approximate computing lies at the root of this approach where an attempt has been made to tweak in the hardware to make models more robust along with high energy-efficient computing gains with purpose-built architectures.















































































