



|
Listen to this story
|
At the RAISE summit 2020, PM Narendra Modi said, “Our planet is blessed with several languages. In India, we have several languages and dialects; such diversity makes us a better society. As professor Raj Reddy suggested, why not use AI to breach the language barrier seamlessly?”
To say that the digitalisation efforts in India are successful, the stakeholders – government, the research community and the industry – would need to make conscious efforts to deliver its benefits to all sections of the society. It is a challenge, considering the language barrier that exists in creating these AI models. Most of the Indian languages are low-resource, which means that they have relatively lesser data available for training NLP systems, especially conversational systems.
In this backdrop, the Indian government recently announced the launch of Project Bhashni, which aims to offer easy access to the internet and digital services in their native languages. As per Statista, India was estimated to have over 748 million users in 2020. By 2026, the country is expected to have 1 billion smartphone users, with rural areas driving the sale of internet-enabled phones, reports Deloitte.
Building AI for Indian languages
One such initiative contributing to low-resource language AI in the country led us to AI4Bharat, an open-source research lab for Indian languages. The initiative is supported by Microsoft’s Research Lab and India Development Center (IDC), which provides ‘unrestricted research grants’ towards building open-source technologies. In addition, it is supported by EkStep Foundation with mentorship and software engineering to build and deploy open-source applications for Indian languages.
AI4Bharat looks to contribute in the following areas:
- Data: Create the largest public datasets and benchmarks across various tasks and 22 Indian languages.
- AI Models: Build SOTA, open source, foundational AI models across tasks and 22 Indian languages
- Applications: Design and deploy with partners reference applications to demonstrate the potential of open source AI models.
- Ecosystem: Enable startups, researchers, and government to innovate on Indian language AI tech with educational material and workshops.
Some of the datasets and language generation models launched by AI4Bharat include Indic Corp, IndicNLG Suite, IndicGLUE, IndicXtreme (coming soon), and Naamapadam (coming soon).
IndicCorp consists of large sentence-level monolingual corpora for 11 Indian languages and Indian English containing 8.5 billion words (250 million sentences) from multiple news domain sources. IndicNLG Suite consists of training and evaluation datasets for five diverse language generation tasks spanning 11 Indic languages. It is one of the largest multilingual generation dataset collections across languages.
Meanwhile, IndicGLUE offers a benchmark for six NLU tasks spanning 11 Indian languages containing formal training and evaluation sets. IndicXtreme offers a benchmark for zero-shot and cross-lingual evaluation of various NLU tasks in multiple Indian languages. Naamapadam offers training and evaluation datasets for named entity recognition in multiple Indian languages.
In terms of machine translation, AI4Bharat has developed applications like Samanantar, IndicTrans, and Shoonya.
For instance, Shoonya improves the efficiency of language work (like translation, speech transcription, text validation, optical character recognition, etc.) in Indian languages with AI tools and custom-built UI interfaces and features. The team believes that this is a key requirement to create larger datasets for training AI models like neural machine translation. The current focus of this tool is on translation. The first version of Shoonya (v1) is expected to release later this month.
In the area of machine transliteration, AI4Bharat has launched Aksharantar, IndicXlit, and IndiclangID. IndiclangID is a model for identifying the language of romanised Indian language words in Aksharantar.
Another application developed by AI4Bharat includes Chitralekha, an open-source tool for video transcription with optional translation support focused on Indian languages. The first version of Chitralekha is expected to be launched later this month.
Check out all the open source datasets, models and libraries from AI4Bharat here.
On July 28, 2022 – AI4Bharat will be launching the Nilekani centre. The event will also have a workshop on Indian language technology. The foundation of this centre has been led by technopreneur and Infosys chairman Nandan Nilekani, focusing on open-source language technologies for the public good.
Other contributions
Top educational institutions are also actively contributing to this domain.
Earlier this month, researchers from IIT Guwahati developed a named entity annotation dataset for low resource Assamese language with a baseline Assamese named entity recognition (AsNER) model. The dataset contains about 99K tokens. This includes text from the speech of the Prime Minister of India and an Assamese play.
In May 2022, IIT Kharagpur researchers demonstrated a large-scale analysis of multilingual abusive speech in Indic languages. The team examined different interlingual transfer mechanisms and observed the performance of various multilingual models for abusive speech detection for eight different Indic languages. The languages include Kannada, Bengali, Hindi, English, Malayalam, Marathi, Tamil and Urdu.
Last year, researchers from IIIT Hyderabad and the University of Bath developed an automated framework for Indian language neural machine translation (NMT) systems. This framework aims to address the lack of large-scale multilingual sentence-aligned corpora and robust benchmarks.
IIT (BHU) Varanasi researchers have developed linguistic resources for Bhojpuri, Magahi, and Maithil, where they performed basic statistical measures for these corpora at character, word, syllable, and morpheme levels, alongside understanding their similarity estimates and baselines for three applications.
Jadavpur University researchers developed an end-to-end procedure to improve semantic search performance using semi-supervised and unsupervised learning algorithms on an available Bengali repository to have seven types of semantic properties – namely conceptual, connotative, collocative, social, affective, reflected, and thematic – to develop the system.
C-DAC (The Centre for Development of Advanced Computing), an Indian autonomous scientific society operating under the MeitY, has launched several projects related to low-resource languages. Some of them include C-DAC GIST, multilingual computing, and others.
Besides these, there are startups like Gnani.ai, Reverie Language Technologies, DheeYantra Research Labs, and RaGaVeRa Indie Technologies, and others, are also contributing to the ecosystem.
India’s mission to make AI accessible
Last year, MeitY unveiled a detailed plan in its white paper, ‘National Language Translation Mission,’ also known as Project Bhashni.
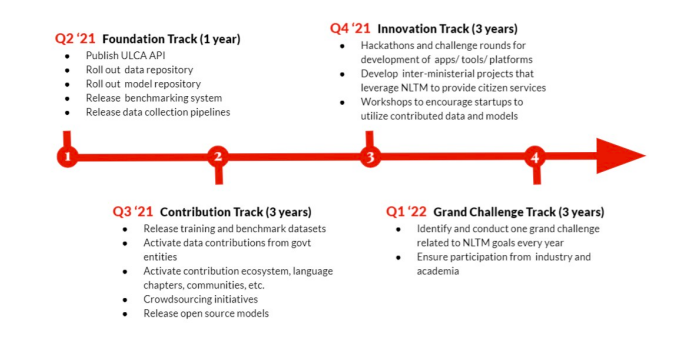
(Source: MeitY)
As per the plan, MeitY will be setting up a process to utilise the contributions received from the ecosystem.
The think tank said that both ‘state and language missions’ and ‘language missions’ would be established across states to focus on data collection and content creation in specific languages. The language missions, on the other hand, would be region specific, depending upon what language is spoken in the region, and there could be multiple language missions across a single state.
Language missions would be responsible for empanelling agencies for data collection, curation and validation activities. Further, it stated that all original or translated data should be collected using a UCLA-compliant process defined by the data management unit (DMU).
Also, the language missions would be responsible for identifying data sources from state government entities and driving crowdsourcing efforts through standard Bhashini tools. Most importantly, MeitY stated that the language missions would run awareness campaigns for crowdsourcing, which would be focused on low-resource languages. On the other hand, the performance of language missions would be measured through a public dashboard.
DMU would also develop in-house resources for certain low-resource languages or specific tasks for quality control. In addition, state language missions would provide resources to DMU for all languages.
For the first two years, MeitY aims to expand training datasets in low-resource languages, including North Eastern and Tribal languages, alongside other languages where sufficient data is not available.
By 2024, MeitY looks to sign MoUs with five more entities each in public and private sectors for data contribution, specifically for low resource languages. Also, drive campaigns for data crowdsourcing, creation, and curation in low-resource languages.














































































