



Last month, enliteAI released Maze, a new framework for applied reinforcement learning (RL). enliteAI is a technology provider for artificial intelligence specialised in reinforcement learning and computer vision.
(The source code of its latest framework is available on GitHub. Also, check out enliteAI’s ‘GettingStarted‘ notebooks to start experimenting with Maze.)
According to enliteAI, Maze supports scalable state-of-the-art (SOTA) algorithms capable of handling multi-agent and hierarchical RL settings with dictionary action and observation spaces. It also helps build powerful perception learners with building blocks for graph-convolution, self-and graph attention, recurrent architectures, action and observation masking, and more.
Plus, it offers support for complex workflows such as limitation learning from teacher policies and fine-tuning; customisable event logging; customisation of trainers, wrappers, environments, and other components; leverages best practices such as reward scaling, action masking, observation normalisation, KPI monitoring; and easy and flexible configuration.
How is Maze different from other RL Frameworks?
Compared to other RL frameworks that follow a more narrow approach by prioritising algorithms while building RL driven applications, Maze offers a command-line interface (CLI) and an application programming interface (API). It uses PyTorch for its network.
Besides Maze, some notable RL frameworks include Panda Gym, Acme, DeeR, Dopamine, Frap, RLgraph, etc.
enliteAI team talked about how every practical RL use case would be considerably more complex than CartPole-v0, which need to be debugged, behaviour recorded, and interpreted components configured and customised. Maze offers several features that support you in mitigating and resolving those problems.
Some of them include:
- Event-based logging system for recording and understanding agent’s behaviour in detail
- Allows flexibility in how an environment is represented in the action and observation space
- Based on Hydra, Maze enables users to quickly change the agent and environment composition without changing a single line of code
The team added that Maze is entirely independent of other RL frameworks. For example, in RLIib, agents can be trained with RLLib’s algorithm implementations while operating within Maze.
Maze design principles
enliteAI team mentioned it is being used in applied and practical RL framework, supporting users in developing RL solutions to real-world problems. This includes supply chain management, design optimisations, chip design, games, and others.
Ensuring best results, enliteAI follows guiding principles and best software engineering practices in up-to-date documentation, testing, hyperparameters, code quality, usability, reproducibility, and customizability.
In terms of supported algorithms, enliteAI aims to include SOTA, scalable, and practically relevant algorithms. Currently, Maze supports the following algorithms: A2C, PPO, Impala, SAC, behavioural cloning, and evolutionary strategies. Soon, it plans to include SACID, AlphaZero, and MuZero. In addition to this, Maze offers support for advanced training workflows like imitation learning from teacher policies and policy fine-tuning.
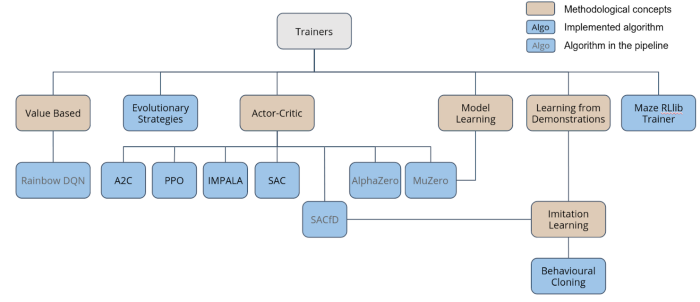
Supported algorithms (Source: enliteAI)
Use cases
enliteAI said it takes minimal code setup to get Maze up and to run. For instance, at the ‘learning to run a power network’ (L2RPN) challenge, a specified power grid has to be kept running by avoiding blackouts. The team re-implemented last year’s winning solution with Maze. (Check out the code on GitHub.)
Besides this, the team has utilised Maze to optimise the stock replenishment process for the steel producer voestalpine. However, the source code of this project is not available as it is not open-source. “More open-source projects are in our pipeline and will be announced shortly,” said the enliteAI team.
Conclusion
With Maze, enliteAI looks to enable AI-based optimisation for a wide range of industrial decision processes and make RL as a technology accessible to industry and developers. It aims to cover RL applications’ complete development life cycle, ranging from simulation engineering up to agent development, training, and deployment. “We hope that Maze is as useful to others as it is to us and look forward to seeing what the RL community at large will build with it,” concluded team enliteAI.













































































