



|
Listen to this story
|
Researchers for Meta AI, alongside Carnegie Mellon University, University of Southern California and Tel Aviv University, today unveiled LIMA, a 65 billion parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinsurance learning or human preference modelling.
Check out the research paper: LIMA: Less Is More for Alignment
Meta’s AI chief Yann LeCun said that this is on par with GPT-4 and Bard in terms of performance.
The researchers said that LIMA has shown strong capabilities in learning specific response formats with minimal training examples. They said that it can effectively handle complex queries, ranging from planning travel itineraries to speculating about alternate history.
Interestingly, one of the notable aspects of this new language model’s performance is its ability to generalise well to unseen tasks that were not part of its training data. In other words, LIMA can apply its learned knowledge to new and unfamiliar tasks, demonstrating a level of flexibility and adaptability, shared by the researchers.
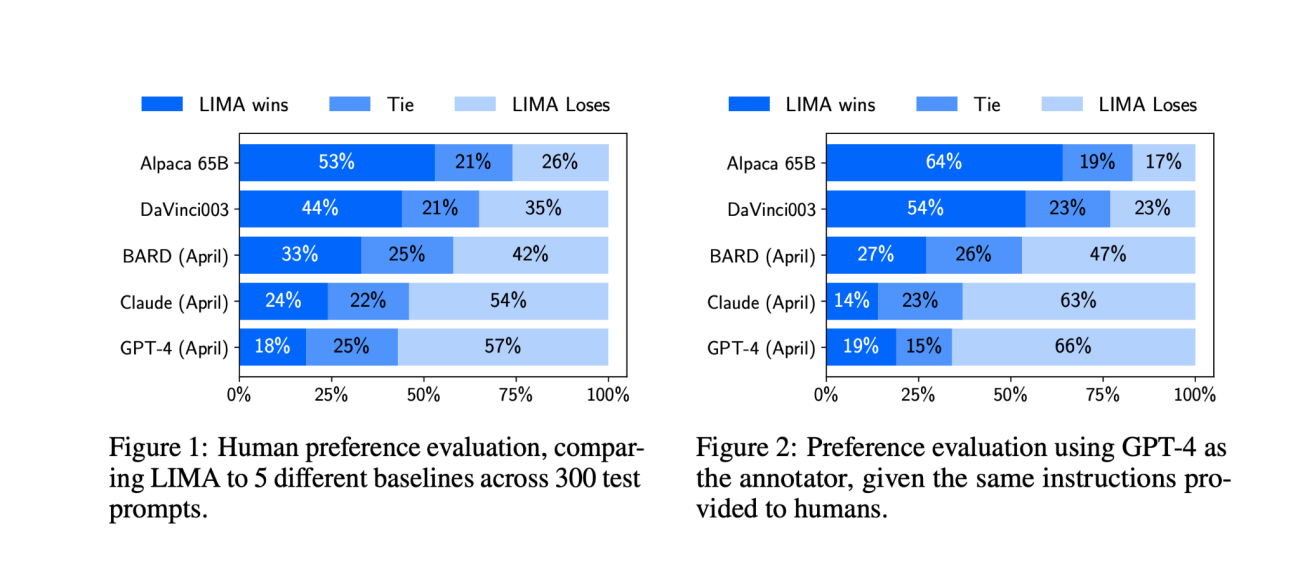
In comparison to human-controlled responses, specifically GPT-4, Bard, and DaVinci-003 (trained with human feedback), the responses generated by LIMA were quite impressive. For instance, in 43% of cases, responses from LIMA were either equivalent to or preferred over GPT-4. In the case of Bard, LIMA was preferred in 58% of cases. In the case of DaVinci-003, the preference rose to almost 65%.
It is interesting to note that with only limited instruction tuning data, models like LIMA can generate high-quality output.
A few weeks back, Meta also released MEGABYTE, a scalable architecture for modelling long sequences. This new technique has outperformed existing byte-level models across a range of tasks and modalities, allowing large models of sequences of over 1 million tokens.














































































