



|
Listen to this story
|
Quantization is the process of deploying deep learning or machine learning models onto edge devices such as smartphones, smart televisions, smart watches, and many more. But deploying the huge model on the edge devices is not possible due to the memory constraints and this is where the process of Quantization is employed. It condenses the huge models to deploy on the edge devices flawlessly. This article provides a brief overview of how to condense huge Tensorflow models to light models using TensorFlow lite and Tensorflow Model Optimization.
Table of Contents
- Introduction to Quantization
- Different types of Quantization techniques
- Building a deep learning model from scratch
- Post Training Quantization technique implementation
- Aware Model Quantization technique implementation
- Comparing the Original model and Quantized model prediction
- Summary
Introduction to Quantization
Quantization with respect to deep learning is the process of approximating neural network weights obtained after propagation through the various layers to the nearest integer value or in short lower bit numbers. This conversion facilitates any heavy deep learning models to be easily deployed on edge devices seamlessly as the heavy model will now be condensed to lighter models and the model outcomes can be visualized on the edge devices.
Are you looking for a complete repository of Python libraries used in data science, check out here.
The discrepancy associated with running heavier deep-learning models on lower processing units like smart devices is overcome through Quantization wherein the model’s overall memory consumption will be cut down to almost one-third or to one-fourth of the original Tensorflow model weights.
Now let us see the different types of Quantization techniques.
Different types of Quantization techniques
There are mainly two types of Quantization techniques possible for heavier deep learning models. They are:-
- Post Training Quantization
- Aware Training Quantization
Both the Quantization techniques work under the supervision of the TensorFlow-lite module which is used to condense the heavier models and push them to edge devices.
Post Training Quantization
In the post-training Quantization technique, a heavier TensorFlow model is condensed to a smaller one using the Tensorflow-lite module and in the edge devices, it will probably be deployed as small Tensorflow models. But the issue with this Quantization technique is that only the memory occupancy of the model on the edge device is compressed but the model on the edge devices cannot be used for any of the parameters and even the performance of the model if compared on the basis of accuracy would be less when compared to the Tensorflow model in the testing phase. So this Quantization technique would yield an unreliable model in production showing signs of poor performance.
Aware Training Quantization
The aware training quantization technique is used to overcome the limitations of the post-training technique where this technique is responsible for maturing the heavy TensorFlow model in development to progress through a Quantized model with well-defined parameters and yield a fine-tuned quantized model which can be passed on to the Tensorflow-lite module for fine-tuning and obtaining a complete lighter package of the Tensorflow model developed ready to be deployed on the edge devices.
Building a Deep Learning model from scratch
In this case study, the Fashion MNIST dataset is used to build a Tensorflow model. This dataset has 10 classes of clothes to classify. So let us look into how to build a deep learning model to classify the 10 classes present in the dataset.
The initial steps start with importing the required TensorFlow libraries and acquiring the dataset. This dataset is easily available in the Tensorflow module and this dataset has to be preprocessed by appropriately splitting the dataset into train and test and also perform required reshaping and encoding. Once a complete preprocessed data is available the model building can be taken up with the required number of layers and compiled with appropriate loss functions and metrics. With all this in hand, the model can be finally fitted for the required number of iterations.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Flatten,Dense,Dropout,Conv2D,MaxPooling2D
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical
%matplotlib inline
from tensorflow.keras.datasets import fashion_mnist
(X_train,Y_train),(X_test,Y_test)=fashion_mnist.load_data()
plt.figure(figsize=(15,5))
for i in range(10):
plt.subplot(2,5,i+1)
plt.imshow(X_train[i])
plt.axis('off')
plt.show()

So now we have validated the split of the data successfully we can proceed with model building.
model1=Sequential() model1.add(Conv2D(32,kernel_size=2,input_shape=(28,28,1),activation='relu')) model1.add(MaxPooling2D(pool_size=(2,2))) model1.add(Conv2D(16,kernel_size=2,activation='relu')) model1.add(MaxPooling2D(pool_size=(2,2))) model1.add(Flatten()) model1.add(Dense(125,activation='relu')) model1.add(Dense(10,activation='softmax')) model1.summary()

model1.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['accuracy']) model1_fit_res=model1.fit(X_train,Y_train,epochs=10,validation_data=(X_test,Y_test))

print('Model training loss : {} and training accuracy is : {}'.format(model1.evaluate(X_train,Y_train)[0],model1.evaluate(X_train,Y_train)[1]))

print('Model testing loss : {} and testing accuracy is : {}'.format(model1.evaluate(X_test,Y_test)[0],model1.evaluate(X_test,Y_test)[1]))

Now let us save this Tensorflow model as it can be used for Quantization later.
model1.save('TF-Model')
Now let us see how to implement the Quantization techniques using the saved model.
Post Training Quantization
Before performing the quantization let’s observe the overall memory occupancy of the complete Tensorflow in the working environment.
tf_lite_conv=tf.lite.TFLiteConverter.from_saved_model('/content/drive/MyDrive/Colab notebooks/Quantization in neural network]/TF-Model')
tf_lite_mod=tf_lite_conv.convert()
print('Memory of the TF Model on the disk is ',len(tf_lite_mod))

Performing Post-Training Quantization
This Quantization technique is taken up by using the Default Optimization technique of the TensorFlow lite module and the Default optimizations obtained will be converted to a quantized model using the convert function using this model we can validate the memory occupancy of the quantized model using post-training optimization.
post_tr_conv=tf.lite.TFLiteConverter.from_saved_model("/content/drive/MyDrive/Colab notebooks/Quantization in neural network]/TF-Model")
post_tr_conv.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = post_tr_conv.convert()
print('Memory of the Quantized TF Model on the disk is ',len(tflite_quant_model))

So here we can clearly observe the differences in memory occupancy of the original Tensorflow model and the Quantized model wherein we can clearly see that the Quantization technique has condensed the original Tensorflow model to one-third of the original memory occupancy. But as mentioned earlier this technique is more suitable only to compress the model and validate the memory occupancy. So for better evaluation of the model’s performance on edge devices the Aware Training Quantization technique is used.
Aware Model Quantization technique implementation
This Quantization technique is one of the most effective quantization techniques as it not only condenses the heavier models but also yields reliable model performance parameters and also shows considerable performance when the condensed TensorFlow model is deployed in the edge devices. Let us see the steps involved in the implementation of this Quantization technique.
!pip install tensorflow-model-optimization import tensorflow_model_optimization as tfmod_opt quant_aw_model=tfmod_opt.quantization.keras.quantize_model quant_aw_model_fit=quant_aw_model(model1)
So now as we have created a quantized model we have to once again compile the model with appropriate loss functions and metrics and later fit this same model with the split data.
quant_aw_model_fit.compile(loss='sparse_categorical_crossentropy',metrics=['accuracy'],optimizer='adam') quant_aw_model_fit.summary()

quant_mod_res=quant_aw_model_fit.fit(X_train,Y_train,epochs=10,validation_data=(X_test,Y_test))

Evaluating the Quantized model parameters
print('Quantized Model training loss : {} and training accuracy is : {}'.
format(quant_aw_model_fit.evaluate(X_train,Y_train)[0],quant_aw_model_fit.evaluate(X_train,Y_train)[1]))

print('Quantized Model testing loss : {} and testing accuracy is : {}'.
format(quant_aw_model_fit.evaluate(X_test,Y_test)[0],quant_aw_model_fit.evaluate(X_test,Y_test)[1]))
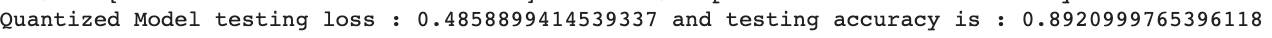
Now let us validate the memory occupancy of the quantized model and the original Tensorflow model using some TensorFlow lite packages.
print('Memory of the TF Model on the disk is ',len(tf_lite_mod))
print()
print('Memory allocation of Quantization Aware Model',len(tflite_qaware_model))

So here we can clearly see the difference between the quantized model bits and the original TensorFlow model bits in terms of memory consumption. As we also evaluated certain parameters of both the original Tensorflow model and the Quantized model and any drop in the performance was not observed. For better comparison let us try to compare the classification ability of both the Tensorflow and the Quantized model for correctly classifying the different types of clothes.
Comparing the Original model and Quantized model prediction
y_pred=model1.predict(X_test)
figure = plt.figure(figsize=(15,5))
for i, index in enumerate(np.random.choice(X_test.shape[0], size=15, replace=False)):
ax = figure.add_subplot(3, 5, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(X_test[index]))
predict_index=np.argmax(y_pred[index])
true_index=Y_test[index]
ax.set_title("{} ({})".format(labels[predict_index],
labels[true_index]),
color=("green" if predict_index == true_index else "red"))
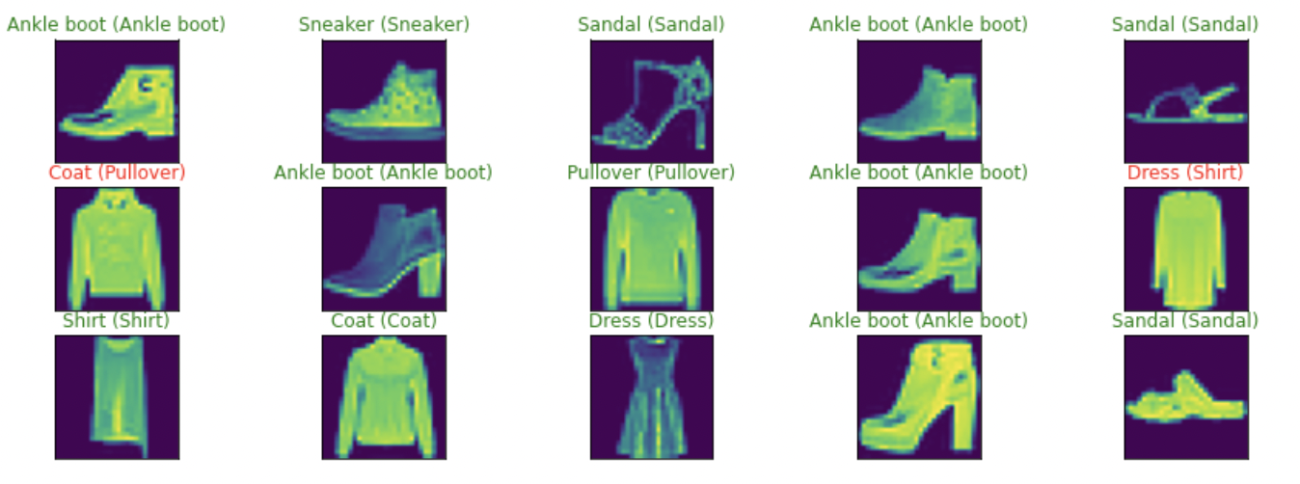
As we have visualized the ability of the original TensorFlow model to classify the clothes, let us try to validate if there are any misclassifications by the Quantized model that would be deployed to production in edge devices.
y_pred_quant_aw=quant_aw_model_fit.predict(X_test)
figure = plt.figure(figsize=(15,5))
for i, index in enumerate(np.random.choice(X_test.shape[0], size=15, replace=False)):
ax = figure.add_subplot(3, 5, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(X_test[index]))
predict_index=np.argmax(y_pred[index])
true_index=Y_test[index]
ax.set_title("{} ({})".format(labels[predict_index],
labels[true_index]),
color=("green" if predict_index == true_index else "red"))

Summary
So as mentioned clearly in this article this is how different Quantization techniques are used to condense huge deep learning models into smaller bits by reducing the overall memory occupancy of the mode developed into one-third or one-fourth of the model’s total memory occupancy and deploying it on edge devices which would relatively be of lower memory. So if the quantization technique is taken up any complex deep learning models can be condensed to lighter models and be deployed on edge devices.














































































