
AI Origins & Evolution
Neural network 2.0: a major breakthrough in edge computing
AIPEs powered neural network 2.0 technology can replace conventional MAC operations.

AIPEs powered neural network 2.0 technology can replace conventional MAC operations.
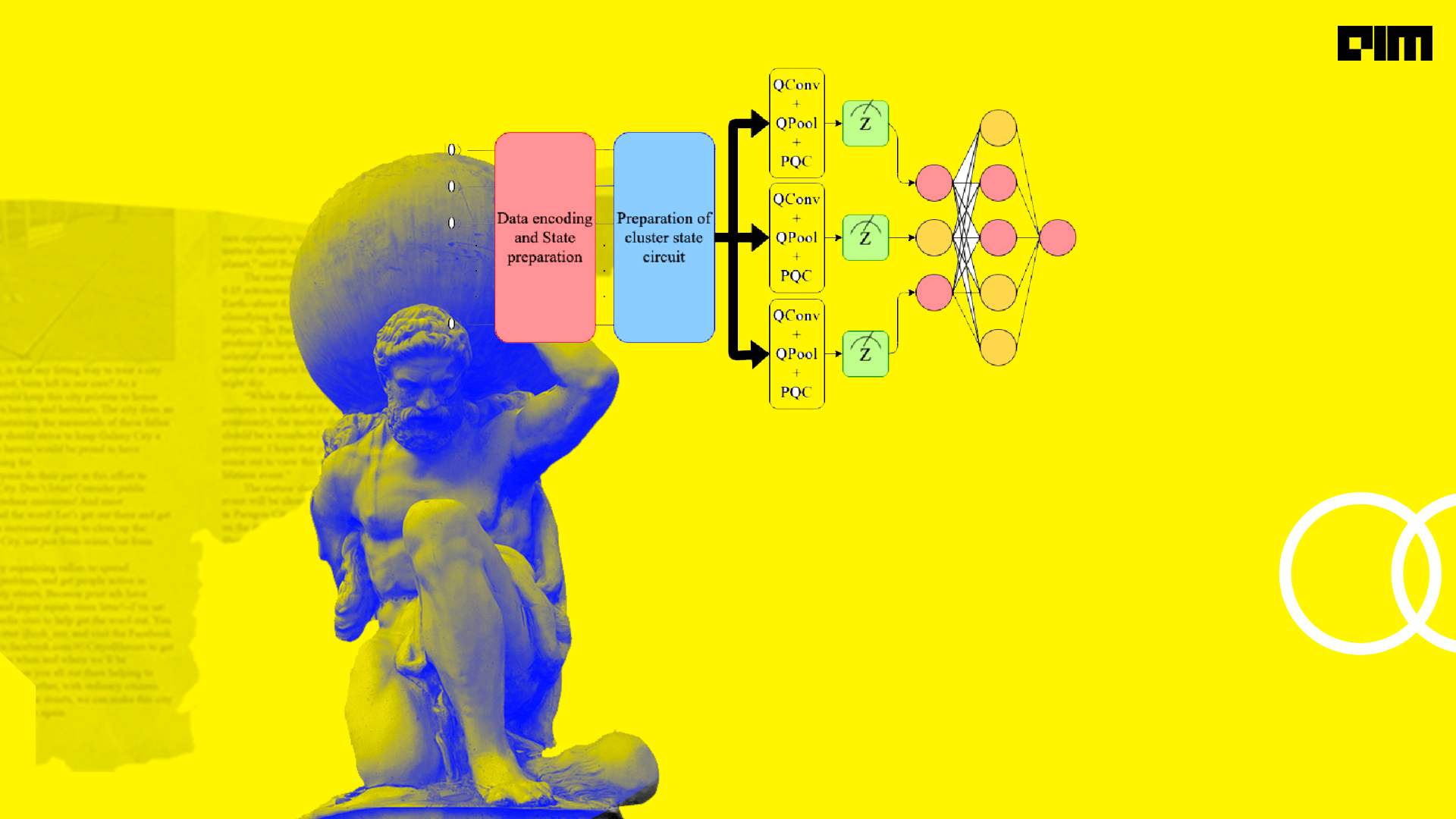
Convolutional Neural Networks have the limitation that they learn inefficiently if the data or model dimension is very large.
GSPMD separates programming an ML model from parallelization and is capable of scaling most deep learning network architectures

There are many cases where we get the requirements of probabilistic models and techniques in neural networks. These requirements can be filled up by adding probability layers to the network that are provided by TensorFlow.
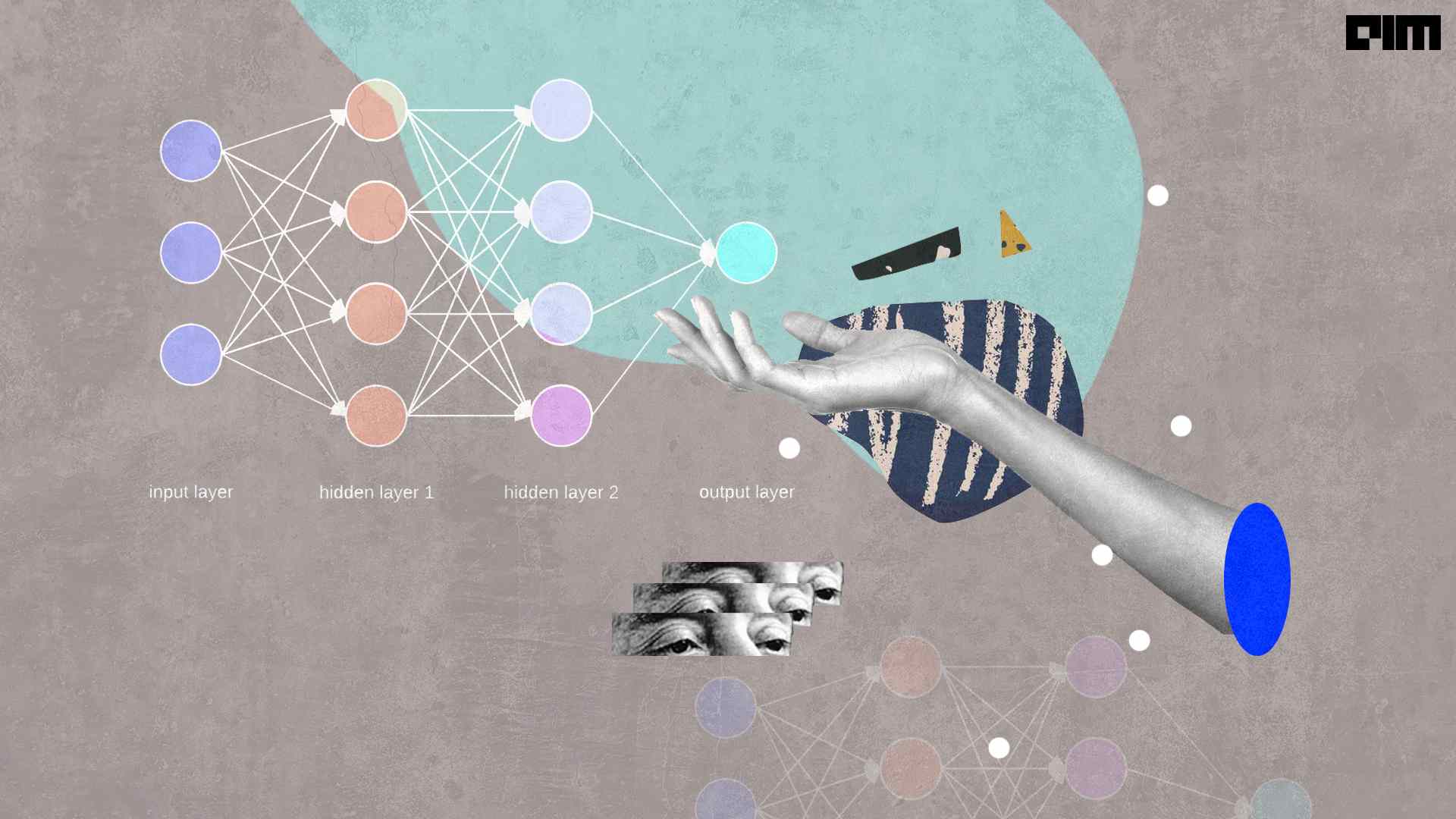
In many of the cases, we see that the traditional neural networks are not capable of holding and working on long and large information. attention layer can help a neural network in memorizing the large sequences of data.
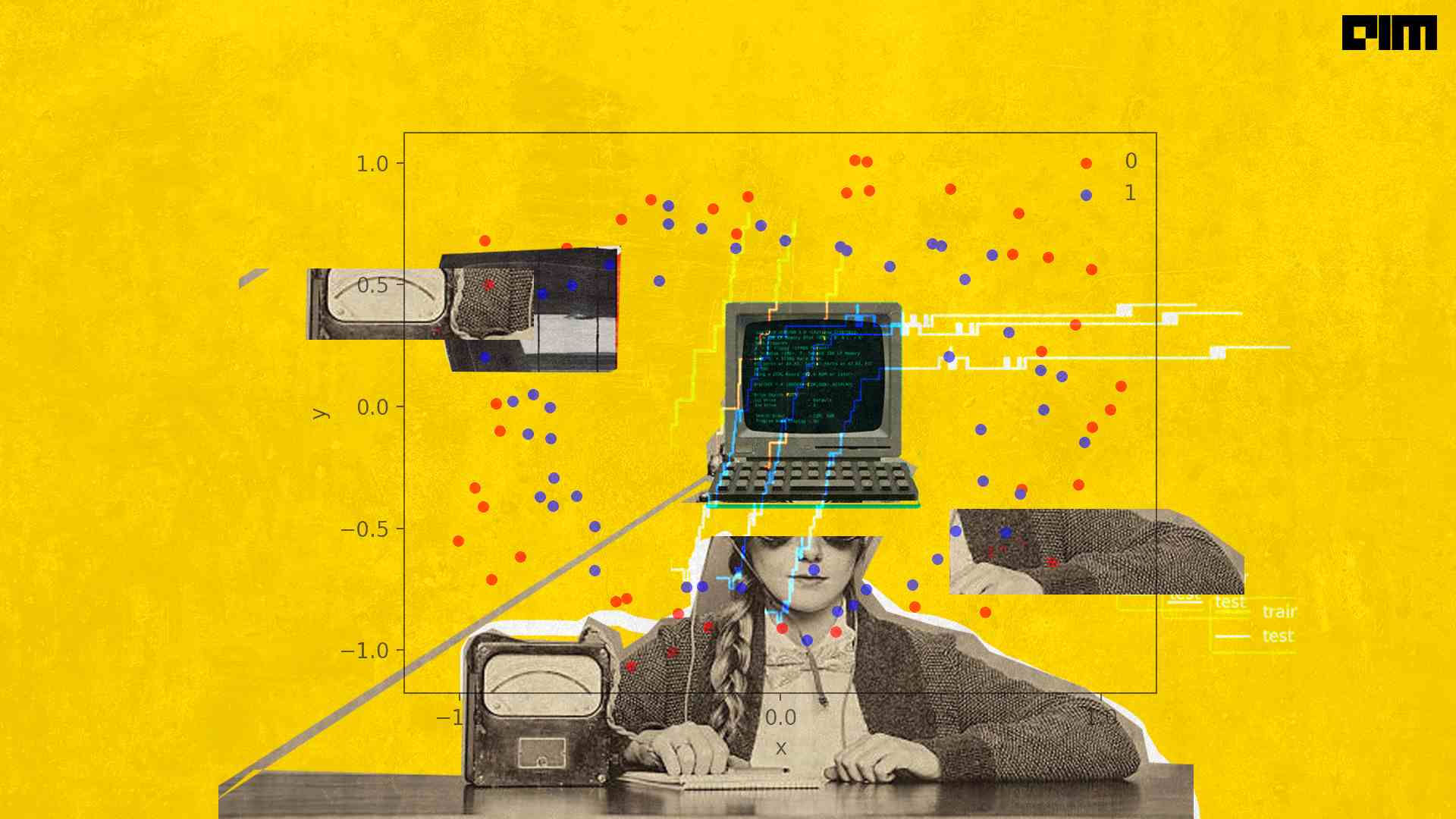
Deep neural networks are sophisticated learning models that are prone to overfitting because of their ability to memorize individual training set patterns rather than applying a generalized approach to unrecognizable data.

The main job of an activation function is to introduce non-linearity in a neural network.

The Bayesian statistics can be used for parameter tuning and also it can make the process faster especially in the case of neural networks. we can say performing Bayesian statistics is a process of optimization using which we can perform hyperparameter tuning.

Learning rate is an important parameter in neural networks for that we often spend much time tuning it and we even don’t get the optimum result even trying for some different rates.
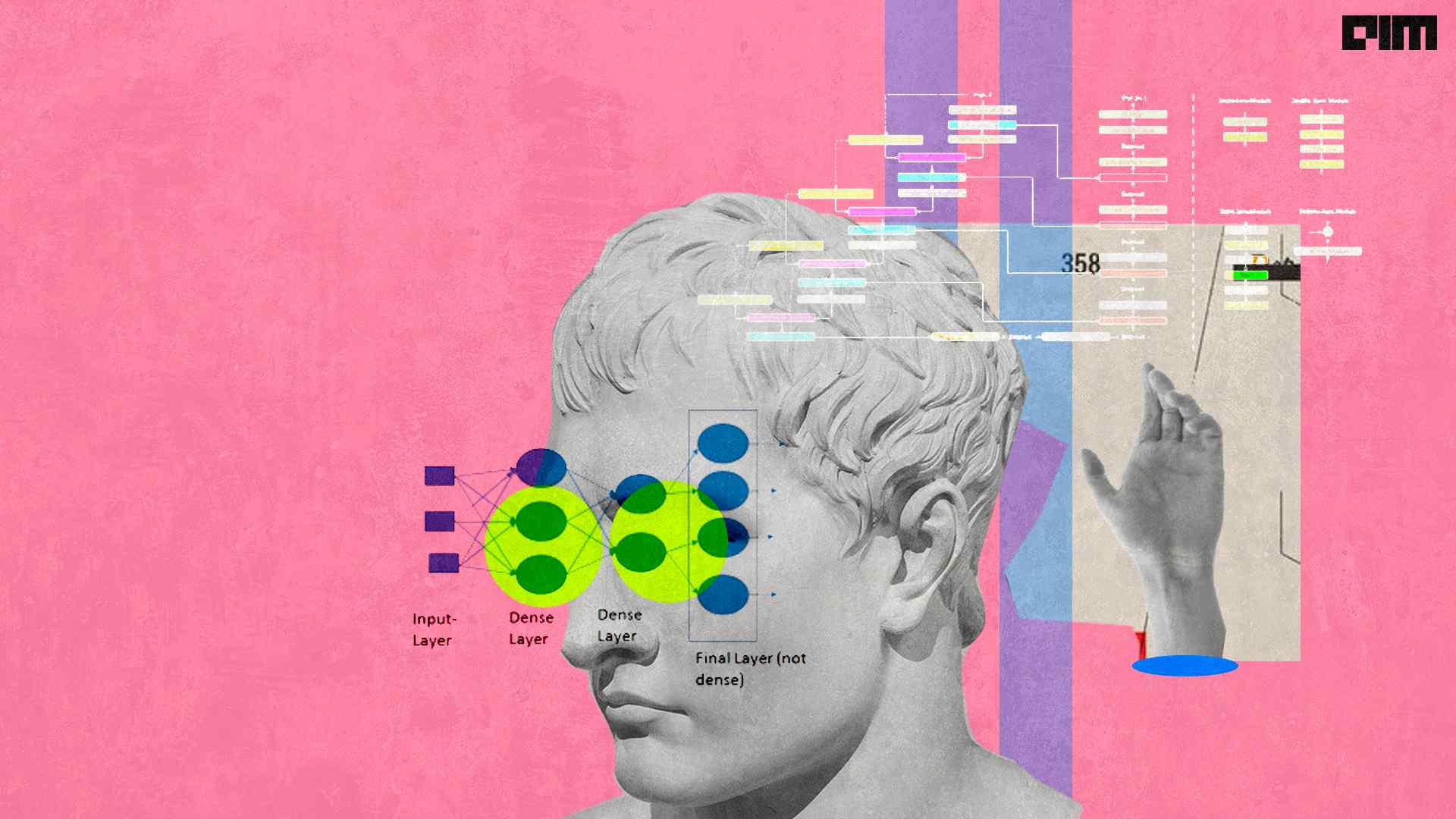
the lambda layer has its own function to perform editing in the input data. Using the lambda layer in a neural network we can transform the input data where expressions and functions of the lambda layer are transformed.

L1 and L2 regularization techniques can be used for the weights of the neural networks. using regularization of weights we can avoid the overfitting problem of the network

Implementing neural networks necessitates the use of a variety of specialized building elements, such as multidimensional arrays, activation functions, and automatic differentiation.

Despite being quite effective in a variety of tasks across industries, deep learning is constantly evolving, proposing new neural network (NN) architectures such as the Spiking Neural Network (SNN).

A team of software engineers at Facebook, led by Software Engineer Bertrand Maher, recently released a JIT compiler for CPUs based on LLVM, called NNC, for “Neural Network Compiler.”

There are a number of studies in which we can see that neural networks are generalized and can be applied to the regular grid structure which is helpful in working on arbitrarily structured graphs

Non-deep networks could be utilised to create low-latency recognition systems, rather than deep networks.

A method called Task Affinity Groupings (TAG) has been proposed by Google AI that determines which tasks should be trained together in multi-task neural networks.

GNNs can be deployed in computer vision, NLP, traffic network to solve different problems

Dynamic Neural networks can be considered as the improvement of the static neural networks by adding more decision algorithms we can make neural networks learning dynamically for the input.

TTFS is a time-coding technique in which neurons’ activity is proportionate to their firing delay.

A probabilistic neural network (PNN) is a sort of feedforward neural network used to handle classification and pattern recognition problems.

Data Scientists at CRED, Ravi Kumar and Samiran Roy explained the essence of using graph neural networks and how the emerging technology is being utilised by CRED.

In the future, we plan to optimise these models further and apply them to new tasks, such as zero-shot learning and self-supervised learning.
Neural network subspaces contain diverse solutions that can be ensembled, approaching the ensemble performance of independently trained networks without the training cost.

This post explains most underlined
Plateau phenomenon and it’s remedies
which is related to optimization of ML model.

Neural network pruning, which comprises methodically eliminating parameters from an existing network, is a popular approach for minimizing the resource requirements at test time.

A paper titled “ETA Prediction with Graph Neural Networks in Google Maps” presents a graph neural network estimator for an estimated time of travel (ETA).

Not Quite My Tempo: Why Should We Care About AI Generated Music?

A deep neural network is created by sandwiching “hidden” layers between the input and the output.

Long Short Term Memory in short LSTM is a special kind of RNN capable of learning long term sequences. They were introduced by Schmidhuber and Hochreiter in 1997. It is explicitly designed to avoid long term dependency problems. Remembering the long sequences for a long period of time is its way of working.

Join the forefront of data innovation at the Data Engineering Summit 2024, where industry leaders redefine technology’s future.