



As spreadsheets are converted from their spreadsheet form into a corporate database, a by product of that conversion is the creation of what can be called the “mnemonic” dictionary. The mnemonic dictionary does not contain values of data found on the spreadsheet. Instead, the mnemonic dictionary contains the metadata that is found on the spreadsheets. It is important to note that the metadata that is captured is not the metadata from all of the spreadsheets in the corporation. Instead, the metadata that is captured is only the metadata that is headed for corporate data.
Fig 1 shows that the mnemonic dictionary is a by-product of the processing of spreadsheets into corporate data.

The data that goes into the mnemonic dictionary is the metadata found on the spreadsheet. The normal metadata for any given value found on the spreadsheet is – column name and row id name. Each value in the spreadsheet is uniquely valued by the association with a column name and a row id name, as seen in Fig 2 –

The column name and row id name become the criteria by which a value is distinguished on the spreadsheet, as seen by the rifle scope sighting in on a value in Fig 3 –
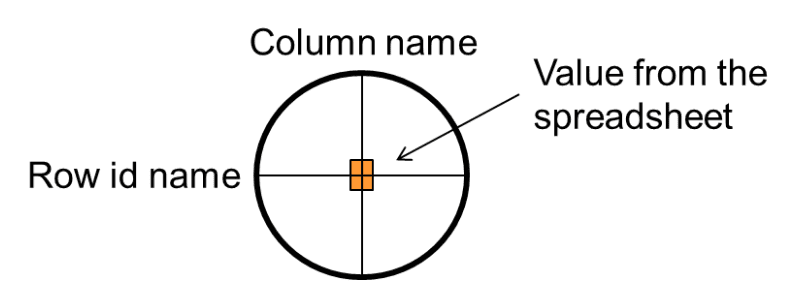
The metadata then that is found on the spreadsheet is the intersection of column name and row id name. This metadata information then becomes the contents of the mnemonic dictionary.
Fig 4 shows the contents of the mnemonic dictionary –

In addition to column name and row id name, the other data that is found in the mnemonic dictionary is
- Spreadsheet system name
- Date of creation
The spreadsheet system name is necessary because there is a need to associate elements of metadata with a particular spreadsheet. The date of creation is necessary because the metadata on a spreadsheet is fluid, changing from one day to the next or even from one hour to the next. The metadata that was found on a spreadsheet one day may not be the same metadata found on the sheet on another day.
The mnemonic dictionary then becomes a guide to what kind of data is found in the spreadsheets of the corporation. Note that the actual values that are found on the spreadsheet are not found in the mnemonic dictionary. They are found in the actual corporate database instead.
The value of the mnemonic dictionary is to serve as a guide as to what data can be found in the different spreadsheets in the corporation.
Fig 5 shows that the mnemonic dictionary serves as a guide to the contents of the spreadsheets in the corporation
Bill Inmon – the “father of data warehouse” – has written 57 books published in nine languages. Bill was named by ComputerWorld as one of the ten most influential people in the history of the computer profession. Bill lives in Castle Rock, Colorado.
Bill’s latest book is TURNING TEXT INTO GOLD, Technics Publications, a book that shows how text can be turned into business value. TURNING TEXT INTO GOLD is available on Amazon.com.







































































