



Word2vec is considered one of the biggest breakthroughs in the development of natural language processing. The reason behind this is because it is easy to understand and use. Word2vec is basically a word embedding technique that is used to convert the words in the dataset to vectors so that the machine understands. Each unique word in your data is assigned to a vector and these vectors vary in dimensions depending on the length of the word.
The word2vec model has two different architectures to create the word embeddings. They are:
- Continuous bag of words(CBOW)
- Skip-gram model
In this article, we will learn about what CBOW is, the model architecture and the implementation of a CBOW model on a custom dataset.
What is the CBOW Model?
The CBOW model tries to understand the context of the words and takes this as input. It then tries to predict words that are contextually accurate. Let us consider an example for understanding this. Consider the sentence: ‘It is a pleasant day’ and the word ‘pleasant’ goes as input to the neural network. We are trying to predict the word ‘day’ here. We will use the one-hot encoding for the input words and measure the error rates with the one-hot encoded target word. Doing this will help us predict the output based on the word with least error.
The Model Architecture
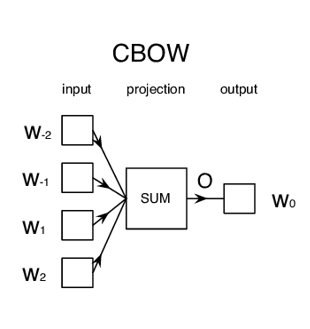
The CBOW model architecture is as shown above. The model tries to predict the target word by trying to understand the context of the surrounding words. Consider the same sentence as above, ‘It is a pleasant day’.The model converts this sentence into word pairs in the form (contextword, targetword). The user will have to set the window size. If the window for the context word is 2 then the word pairs would look like this: ([it, a], is), ([is, pleasant], a),([a, day], pleasant). With these word pairs, the model tries to predict the target word considered the context words.
If we have 4 context words used for predicting one target word the input layer will be in the form of four 1XW input vectors. These input vectors will be passed to the hidden layer where it is multiplied by a WXN matrix. Finally, the 1XN output from the hidden layer enters the sum layer where an element-wise summation is performed on the vectors before a final activation is performed and the output is obtained.
Implementation of the CBOW Model
For the implementation of this model, we will use a sample text data about coronavirus. You can use any text data of your choice. But to use the data sample I have used click here to download the data.
Now that you have the data ready, let us import the libraries and read our dataset.
import numpy as np
import keras.backend as K
from keras.models import Sequential
from keras.layers import Dense, Embedding, Lambda
from keras.utils import np_utils
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
import gensim
data=open('/content/gdrive/My Drive/covid.txt','r')
corona_data = [text for text in data if text.count(' ') >= 2]
vectorize = Tokenizer()
vectorize.fit_on_texts(corona_data)
corona_data = vectorize.texts_to_sequences(corona_data)
total_vocab = sum(len(s) for s in corona_data)
word_count = len(vectorize.word_index) + 1
window_size = 2
In the above code, I have also used the built-in method to tokenize every word in the dataset and fit our data to the tokenizer. Once that is done, we need to calculate the total number of words and the total number of sentences as well for further use. As mentioned in the model architecture, we need to assign the window size and I have assigned it to 2.
The next step is to write a function that generates pairs of the context words and the target words. The function below does exactly that. Here we have generated a function that takes in window sizes separately for target and the context and creates the pairs of contextual words and target words.
def cbow_model(data, window_size, total_vocab): total_length = window_size*2 for text in data: text_len = len(text) for idx, word in enumerate(text): context_word = [] target = [] begin = idx - window_size end = idx + window_size + 1 context_word.append([text[i] for i in range(begin, end) if 0 <= i < text_len and i != idx]) target.append(word) contextual = sequence.pad_sequences(context_word, total_length=total_length) final_target = np_utils.to_categorical(target, total_vocab) yield(contextual, final_target)
Finally, it is time to build the neural network model that will train the CBOW on our sample data.
model = Sequential() model.add(Embedding(input_dim=total_vocab, output_dim=100, input_length=window_size*2)) model.add(Lambda(lambda x: K.mean(x, axis=1), output_shape=(100,))) model.add(Dense(total_vocab, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam') for i in range(10): cost = 0 for x, y in cbow_model(data, window_size, total_vocab): cost += model.train_on_batch(contextual, final_target) print(i, cost)

Once we have completed the training its time to see how the model has performed and test it on some words. But to do this, we need to create a file that contains all the vectors. Later we can access these vectors using the gensim library.
dimensions=100
vect_file = open('/content/gdrive/My Drive/vectors.txt' ,'w')
vect_file.write('{} {}\n'.format(total_vocab,dimensions))
Next, we will access the weights of the trained model and write it to the above created file.
weights = model.get_weights()[0]
for text, i in vectorize.word_index.items():
final_vec = ' '.join(map(str, list(weights[i, :])))
vect_file.write('{} {}\n'.format(text, final_vec))
vect_file.close()
Now we will use the vectors that were created and use them in the gensim model. The word I have chosen in ‘virus’.
cbow_output = gensim.models.KeyedVectors.load_word2vec_format('/content/gdrive/My Drive/vectors.txt', binary=False)
cbow_output.most_similar(positive=['virus'])

The output shows the words that are most similar to the word ‘virus’ along with the sequence or degree of similarity. The words like symptoms and incubation are contextually very accurate with the word virus which proves that CBOW model successfully understands the context of the data.
Conclusion
In the above article, we saw what a CBOW model is and how it works. We also implemented the model on a custom dataset and got good output. The purpose here was to give you a high-level idea of what word embeddings are and how CBOW is useful. These can be used for text recognition, speech to text conversion etc.















































































