



PyCaret is One of the most useful and popular libraries of the python programming language used for machine learning. The reason behind this popularity is that it consists of simple and efficient tools for classification, regression, clustering, dimensionality reduction, model selection, etc. On January 12th, 2022, the new version of PyCaret, PyCaret 2.3.6, was released with new exciting features. In this article, we have covered all the useful and important updates and bug fixes included in the new version of PyCaret. The major points to be discussed in this article are listed below.
Table of contents
- What is PyCaret?
- Added features
- Bug fixes
What is PyCaret?
PyCaret is a python open-source machine learning library with the aim of using low code and a low number of hypotheses for insights within a cycle of machine learning experimentation and development. Using this library we can perform end-to-end machine learning experiments efficiently without consuming so much time. As we discussed, one of the most important advantages of using this library is that we require very little code to perform any machine learning experiment. This advantage of PyCaret enables us to perform highly complex machine learning experiments in a very flexible way.
One more advantage of PyCaret is that it is very simple to use, performing operations using this library automatically stored in the PyCaret Pipeline that is fully orchestrated for and towards the development of models. This library provides facilities using which we can go from data analysis to model development and deployment in a very short time. PyCaret also helps in automating many tasks like adding missing values or transforming categorical data, engineering the present features, or optimizing hyperparameters in the present data.
While talking about the integration we can integrate this library with many environments supporting Python such as Microsoft Power BI, Tableau, Alteryx, and KNIME. In the below list there are some examples of tasks that can be performed using this library:
- Data Preparation
- Training A Model
- Hyperparameter Tuning within the Model
- Creating Analysis and Deriving Interpretability
- Model Selection
- Experiment Logging
We can install this library using the below line of code:
!pip install pycaret[full]
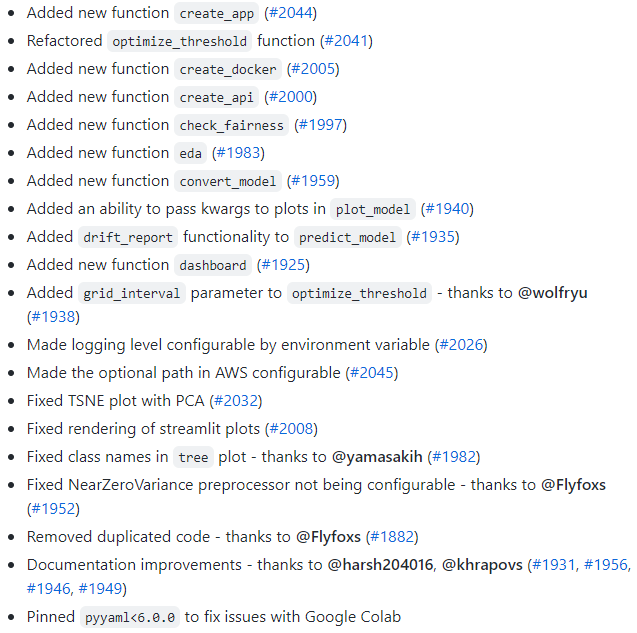
In this article, we are going to discuss new updates (new features or bug fixes) which have come with PyCaret’s new version 2.3.6. So any pre-installed version of PyCaret can be upgraded using the following line of command.
pip install --upgrade PyCaret
To know about the version of PyCaret we can use the following lines of codes.
from PyCaret.utils import version
version()Now, with the new version of PyCaret, we are ready to use the following new updates(new features, bug fixes) of the PyCaret.
(Source)
In the next section of the article, we will discuss the new features and functions which have been added in the new update.
Added features
In the new version of PyCaret, the following new features have been added:
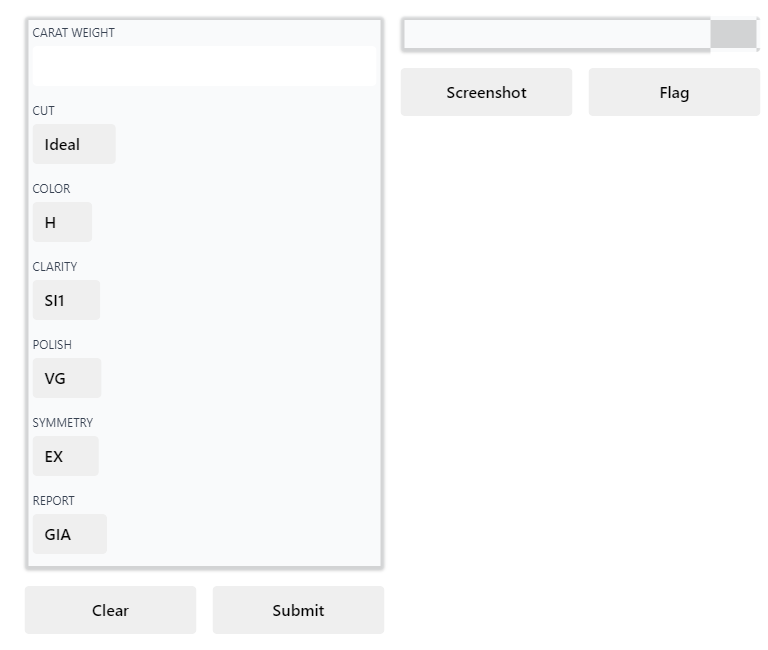
- create_app to create a basic version of the Gradio app: In one of our previous articles, we have seen how we can create a web-based GUI application for machine learning where we have used the sklearn library for making a machine learning model. Using this feature of PyCaret, we can now create web-based applications for regression and classification models developed using the PyCaret library. The below-given codes can be used for the implementation of this new feature.
from pycaret.datasets import get_data
data = get_data('diamond')
from pycaret.regression import *
s = setup(data, target = 'Price', silent=True)
dt = create_model('dt')
create_app(dt)
Output:
- create_docker for generating the requirements.txt and Dockerfile file: In development and deployment of any project related to machine learning models requirement.txt if using GitHub and docker files if using docker are the backbones of the project. These files can be easily generated using this new feature of PyCaret. The below-given codes can be used to can be used for the implementation of this new feature for the above-created model.
# create API
create_api(dt, 'my_api')
# create Docker
create_docker('my_api')Output:

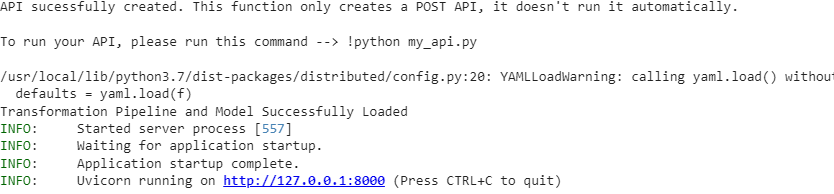
- create_api for making the API for regression and classification models: Using this new feature, PyCaret libraries enable us to generate fast API for regression and classification models built using the PyCaret library. An example of the implementation can be found here. The below-given codes can be used for the implementation of this new feature for the above-created model.
create_api(dt, 'my_api')
!python my_api.pyOutput:
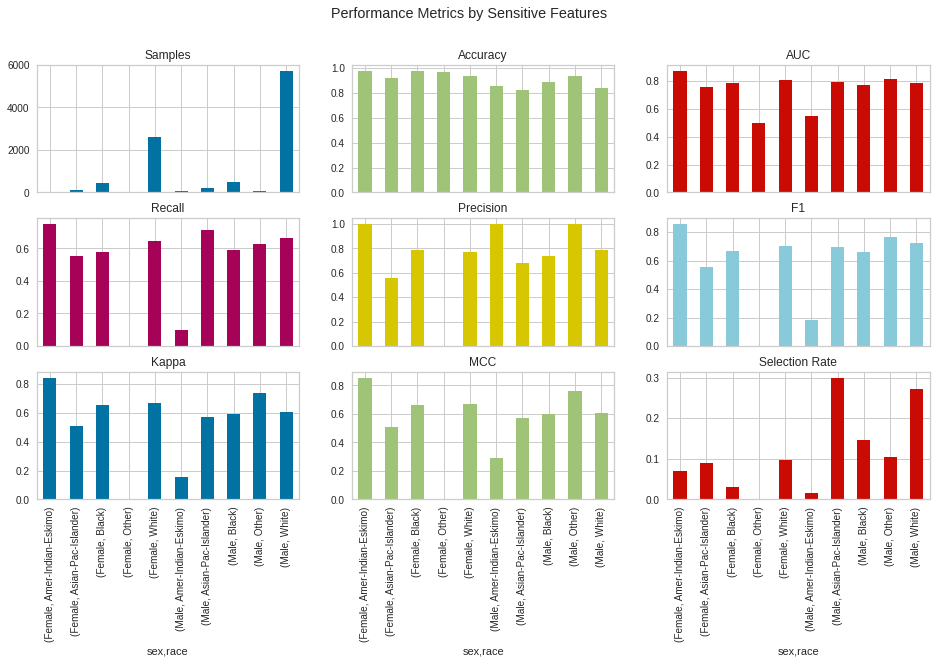
- check_fairness: Fairness refers to the various attempts at correcting algorithmic bias. Using this new feature of the PyCaret, we can check for the fairness of variables on the regression and classification models built using the PyCaret. The below-given codes can be used for the implementation of this new feature.
from pycaret.datasets import get_data
data = get_data('income')
from pycaret.classification import *
s = setup(data, target = 'income >50K', session_id = 123)
lightgbm = create_model('lightgbm')
check_fairness(lightgbm, ['sex', 'race'])Output:
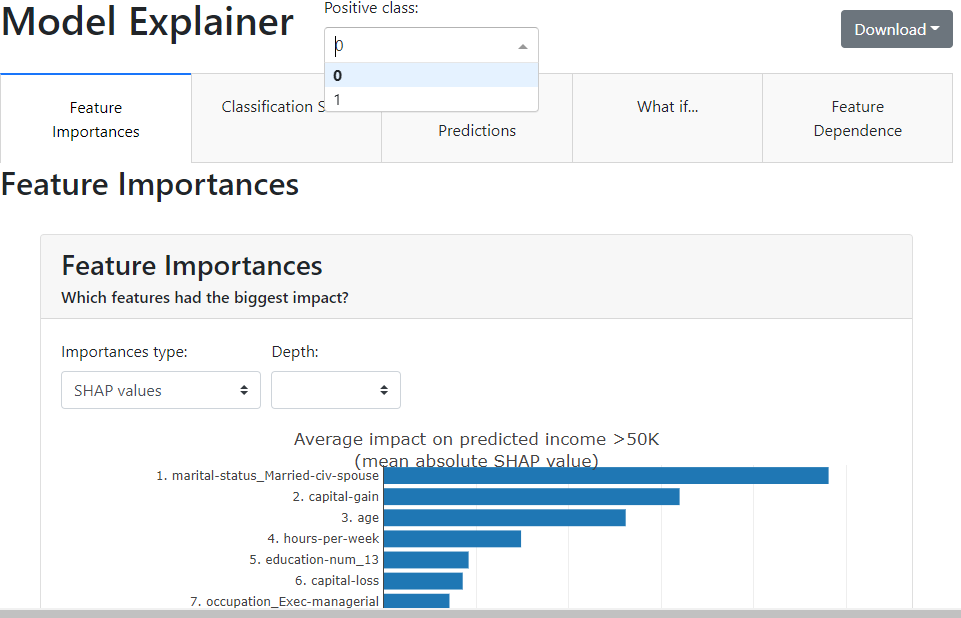
- Dashboard: Most of the time we find that the machine learning models are black-box techniques and for development, every small detail about the model is required and extraction of these details is one of the complex parts of machine learning. This update in the PyCaret allows us to get details about the models like feature importance. The below-given codes can be used for the implementation of this new feature.
dashboard(lightgbm, display_format='inline')
output:
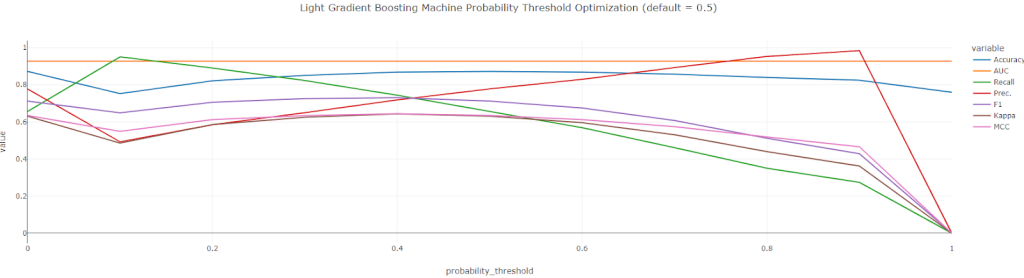
- grid_interval: This is a new feature that can help in the threshold optimization to control the iteration count of a model. This feature is added in the optimize_thershold function. The below-given codes can be used for the implementation of this new feature.
optimize_threshold(lightgbm)
Output:
In this section, we have introduced some of the added features to the PyCaret library which is definitely making the library more user-friendly. There were some small bugs in the library which are also fixed with the new update. In the next section, we look at some of the important bugs which are fixed now.
Bug fixes
Below are some of the important bug fixes in the new release:-
- Custom logging level: In this fix, they have added the CUSTOM_LOGGING_LEVEL variable in the PyCaret.internal.logging module. Now, using this fix we can set a system environment variable to handle logging levels.
- Optional path in the authentication dictionary: This fix now allows us to load models in AWS with a specific path. If any path is not considered in developing the codes which are used for modelling will behave in the same way as they were behaving before.
- t-SNEplot in PCA: Before this fix when we were trying to make the t-SNE plot in clustering using the PCA set up there were some key errors. That is now fixed, we can make an at-SNE plot in clustering when PCA = True in setup.
- Issues related to the non-yellow-brick plot rendering in display_format(streamlit) are fixed.
- With all issues, there were some complaints about the documentation of the tutorials related to the PyCaret which are now fixed, and now we can find all the tutorials with great explanations.
In this section, we have discussed what were the important issues before and with the new updates, contributors of the library have tried and solved them.
Final words
In this article, we have seen what PyCaret is. As they have announced here PyCaret 2.3.6 as their new version, they have committed many additional features on it and also performed fixes to some of the important issues. Using these features and updates the library has become more useful than before.
References:














































































