



Traditional data storage and analytic tools can no longer provide the agility and flexibility required to deliver relevant business insights. With the volume of data generated being large, separating storage and compute enables scaling of each component is required.
The captured data should be pulled and put together and the benefits of collection should outweigh the costs of collection and analysis.
A data lake is a centralised repository that allows the user to store both structured and unstructured data at any scale. It also enables ad-hoc analysis by applying schemas to read, not write. In this way, the user can apply multiple analytics and processing frameworks to the same data.
Data lakes are often confused with data warehouses and it is important to know how data lakes can generate multiple warehouses.
Data Lakes vs Data Warehouses

A typical organisation will require both a data warehouse and a data lake as they serve different needs, and use cases.
Data Warehouses can be built from using resources of the data lakes. Because data lakes store relational data from specific applications of businesses and also non-relational data from social media sites and IoT devices.
Data lakes store all kinds of information without any hint of what it will be used for. Data lakes enable an organisation of diverse query capabilities, data science use-cases.
Components Of Data Lakes
Any data lake would have to conduct three main operations- data ingestion, storing and processing. AWS offer multiple options within these operations and here are few:
Ingestion:
AWS has plenty of ingestion options.

The above figure illustrates the different options that AWS has to offer for data ingestion.
Amazon Kinesis is one such platform. Kinesis makes data streaming easy. It helps build custom applications that process or analyse streaming data using standard SQL queries.
Kinesis allows the user to create availability zones which act as data centres. These zones take in data from various sources like websites or mobile apps.
And then push it to archives like S3 or for sliding window analysis with DynamoDB.
Kinesis streams offer various stream processing choices for apps running on EC2, Lambda, Apache Spark, Apache Flink.
If a user is interested only in particular hashtag, then they can go to Kinesis analytics and give a query regarding the hashtag.
A simple streaming query would look like this:
SELECT STREAM ROWTIME, author, text
FROM Tweets
WHERE text LIKE ‘%#DonaldTrump%’
The output(data collection for ingestion) of this query which is all the Donald Trump hashtags on twitter would go to Kinesis analytics.
And this data can be stored on S3.
Building Catalogue
The catalogue consists of information regarding key aspects of stored data like its format, classification or the tags that they need to be associated so that they can be searched in the data lakes for future use. Whether the stored data can be exposed as metadata and other such information can be accessed from a catalogue. Here the metadata can be the storage location.
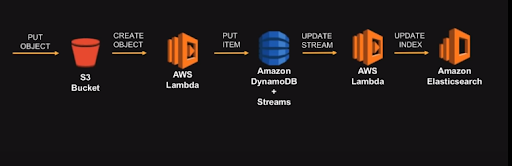
A catalogue can be built in the following steps:
- Put an object into S3 and then create an object from an S3 bucket in AWS Lambda. When an object is stored in a bucket, then an event is triggered. Here an event is a piece of code which can be invoked in any infrastructure the user is working on. This code is usually a logic written by the user for a specific application.
- The code that is invoked can be used to extract metadata; the format of the stored object etc. The extracted object can be stored in a NoSQL database like Amazon DynamoDB.
- This data can again be picked up by AWS lambda service and push it into an Elasticsearch which can be used by different teams to query data to skim through the catalogue.
- These pipelines can be customised by the users and can use a different set of options in the pipeline.
Amazon lets the users/teams to access metadata through APIs by allowing them to build one on top of metadata. AWS’s API Gateway service can be used to build an API which in turn can be used to build a website which can be used for searching through the data lake.
These APIs connects the components on the backend like AWS Lambda or even EC2 or any public endpoint where the catalogue is built.
Processing
Processing data have different uses and different techniques for different entities. The tools which the data scientists find interesting might not be the same for Analysts.
AWS offers different processing and serving options like Amazon EMR, Redshift, Athena etc.
For example, Amazon EMR performs the following functions:
- Manage Cluster platforms
- Run Hadoop, Spark
- Deploy and resize clusters
- Cost-effectively process large amounts of data.
Whereas, Amazon Redshift offers faster and cheaper services; relational data warehouses, HDD and SSD platforms.
AWS supports the user by offering data lake solutions, which are an automated reference implementation that deploy a highly available, cost-effective data lake architecture on the AWS Cloud along with a user-friendly console for searching and requesting datasets.
Setting Up A Data Lake
- Log in to the AWS Management Console and click the button below to launch the data-lake-deploy AWS CloudFormation template.
- On the Select Template page, verify that you selected the correct template and choose Next.
- On the Specify Details page, assign a name to your data lake solution stack.
- Under Parameters, review the parameters for the template, and modify them as necessary
- On the Review page, review and confirm the settings.
- Choose Create to deploy the stack
- Launching the stack will be followed with an email with a link to console.
- After a successful set up of the password, the user can sign in to their respective console.
Check more about DATA LAKES management on AWS here


































































































