



A key balancing act in machine learning is choosing an appropriate level of model complexity: if the model is too complex, it will fit the data used to construct the model very well but generalise poorly to unseen data (overfitting); if the complexity is too low the model won’t capture all the information in the data (underfitting).
In deep learning or machine learning scenarios, model performance depends heavily on the hyperparameter values selected. The goal of hyperparameter exploration is to search across various hyperparameter configurations to find a configuration that results in the best performance. Typically, the hyperparameter exploration process is painstakingly manual, given that the search space is vast and evaluation of each configuration can be expensive.
Also Read:
Hyperparameters help answer questions like:
- The depth of the decision tree
- How many trees are required in random forest
- How many layers should a neural network have
- The learning rate for gradient descent method
Why Are Learning Rates Significant
Learning rate is a parameter, denoted by α(alpha), which is used to tune how accurately a model converges on a result (classification/prediction, etc.). This can be thought of as a ball thrown down a staircase. And a higher learning rate value is equivalent to the higher speed of the descending ball. This ball will leap skipping adjacent steps, and reach the bottom quickly but not settle immediately because of the momentum it carries.
Learning rate is a scalar, a value that tells the machine how fast or how slow to arrive at some conclusion. The speed at which a model learns is important and it varies with different applications. A super-fast learning algorithm can miss a few data points or correlations which can give better insights into the data. Missing this will eventually lead to wrong classifications.
And, to find the next step or the adjacent data point, the gradient descent algorithms multiply the gradient by learning rate (also called step size).
For example, if the gradient magnitude is 1.5 and the learning rate is 0.01, then the gradient descent algorithm will pick the next point 0.015 away from the previous point.
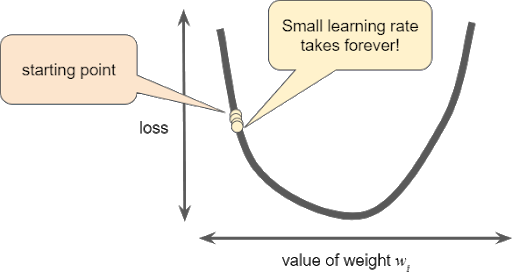
If a learning rate is too small, learning will take too long:
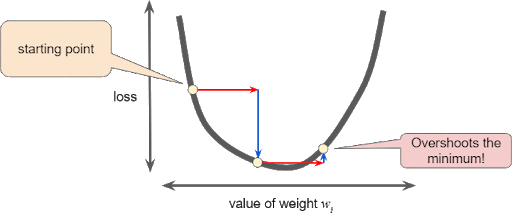
And if a learning rate is too large, the next point will perpetually bounce haphazardly across the bottom of the valley:
This momentum can be controlled with three common types of implementing the learning rate decay:
- Step decay: Reduce the learning rate by some factor every few epochs. Typical values might be reducing the learning rate by a half every 5 epochs, or by 0.1 every 20 epochs.
- Exponential decay has the mathematical form α=α_0e^(−kt), where α_0,k are hyperparameters and t is the iteration number.
- 1/t decay has the mathematical form α=α0/(1+kt) where a0,k are hyperparameters and t is the iteration number.
Tuning The Learning Rate
There is no one stop answer to finding out the method in which hyperparameters can be tuned to reduce the loss; more or less a trial and error experimentation.
Hyperparameters are adjustable parameters you choose to train a model that governs the training process itself. For example, to train a deep neural network, you decide the number of hidden layers in the network and the number of nodes in each layer prior to training the model. These values usually stay constant during the training process.
To bottle down on the values, there are few methods to skim through the parameter space to figure out the values that align with the objective of the model that is being trained:
- Adagrad is an adaptive learning rate method. Weights with a high gradient will have low learning rate and vice versa.
- RMSprop adjusts the Adagrad method in a very simple way to reduce its aggressive, monotonically decreasing learning rate. This approach makes use of a moving average of squared gradients.
- Adam is almost similar to RMSProp but with momentum.
Know more about the application of learning rates here














































































