|
Listen to this story
|
Convolution is a fundamental function in Convolutional Neural Networks (CNNs) that applies a kernel to overlapping sections of data that have been moved across the data. Convolutional kernels, on the other hand, re-learn redundant data due to the significant correlations in real-world data. Network deconvolution is a method that eliminates channel-wise and pixel-wise correlations before the data is fed into each layer. This article will focus on the reasons to use deconvolution layers in DL. Following are the topics to be covered.
Table of contents
- What is deconvolution?
- When to use deconvolution in deep learning
- How do deconvolution works?
Deconvolution simply reverses the process of convolution. Let’s start with a high level understanding of deconvolution.
What is deconvolution?
Deconvolution is a quantitative approach that uses the picture as an estimate of the real specimen intensity and conducts the mathematical inverse of the imaging process to generate an improved estimate of the image intensity using a formula for the point spread function.
The deconvolution operation is an upsampling procedure that both upsamples feature maps and keeps the connectivity pattern. The deconvolutional layers essentially increase and densify the input by employing convolution-like procedures with numerous filters. Deconvolution, unlike previous scaling algorithms, has trainable parameters. During network training, the weights of deconvolutional layers are constantly updated and refined. It is accomplished by inserting zeros between the consecutive neurons in the receptive field on the input side, and then one convolution kernel with a unit stride is used on top.
Difference between transpose convolution and deconvolution
A deconvolutional layer reverses the process of a typical convolutional layer, i.e. it deconvolutes the output of a standard convolutional layer.
The spatial dimension created by the transposed convolutional layer is the same as the spatial dimension generated by the deconvolutional layer. Transposed convolution reverses the ordinary convolution by dimensions only, not by values.
Are you looking for a complete repository of Python libraries used in data science, check out here.
When to use deconvolution in deep learning
Deep learning deconvolution is not concerned with repairing a damaged signal or picture; rather, it is concerned with mapping a set of data values to a larger range of data values.
A mathematical technique that reverses the effect of convolution. Consider feeding input into a convolutional layer and collecting the output. Now run the output through the deconvolutional layer to obtain the same input back. It is the multivariate convolutional function’s inverse. It is used when to understand the learning of a convolution neural network.
For example, training a CNN based on VGG19 architecture to segment birds. With the help of deconvolution, the developer could exactly know the filters used, which part of the images are been masked for the learning process and could also discriminate pixels for reducing the noise in the images. So, to know more about the black box.
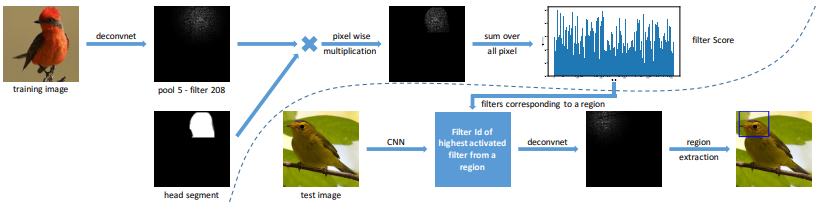
How do deconvolution works?
Pooling in a convolution network is used to filter noisy activations in a lower layer by abstracting activations in a receptive field and assigning them a single representative value. While it aids categorization by maintaining only strong activations in the top layers, spatial information within a receptive field is lost during pooling, which may be crucial for accurate localization necessary for semantic segmentation. To address this issue, deconvolution networks include unpooling layers, which conduct the opposite action of pooling and recreate the original size of activations. It saves the locations of the maximum activations chosen during the pooling procedure in switch variables, which are then used to return each activation to its original pooled position.

An unpooling layer produces an expanded but sparse activation map. The deconvolution layers densify the sparse activations acquired by unpooling with several learnt filters using convolution-like techniques. Deconvolutional layers, on the other hand, correlate a single input activation with numerous outputs, as opposed to convolutional layers, which connect multiple input activations within a filter window to a single activation. The deconvolutional layer produces an expanded and dense activation map. We clip the boundaries of the larger activation map to maintain the output map the same size as the one from the previous unpooling layer.
Deconvolutional layers’ learnt filters correspond to the bases used to recreate the form of an input object. As a result, a hierarchical structure of deconvolutional layers, similar to the convolution network, is employed to record varying levels of form features. Lower-layer filters tend to capture an object’s general form, but higher-layer filters encode class-specific tiny features. In this manner, the network explicitly considers class-specific shape information for semantic segmentation, which is sometimes overlooked in previous systems based only on convolutional layers.
Example for explaining the above explanation
To achieve a clean image after deconvolution there are two problems to be solved. First, look for local patterns on small patches to recover little details. Second, investigate the interplay of far-apart pixels to capture the image’s distortion pattern. The network must extract spatial characteristics from several picture scales to do this. It is also essential to understand how these characteristics will alter when the resolution changes. There are several approaches offered to acquire the findings. But for this article, using an iterative deconvolution (IRD) method.
In this method, residual blocks are employed as implicit pieces of spatial feature extraction and are then fed into an iterative deconvolution (IRD) algorithm. At the output, they are concatenated to achieve multiscale deconvolution. A distorted picture at various scales is supplied into the network’s input. When training a network, the weights from the network’s branches for lesser scales are reused, and the residual connection is utilised to help train branches for bigger scales. This decreases the number of factors and facilitates learning.
This is a multiscale learning approach that may totally forsake kernel evaluation and end-to-end modelling of a clear image. The main notion is that by co-learning the network at multiple sizes and connecting them via modified residual blocks, a full-fledged regression may be performed. The objective is not to find the blur kernel, but rather to approximate a clear image in spatial dimensions (for example, the intensity of the pixels at a specific location in an image).
Conclusion
Deconvolution helps the developers to understand the results of the convolution network but there are high chances that deconvolution itself could be a black box. With this article, we have understood deconvolution in neural networks.