



If a model is tasked with identifying dogs from a random collection, then one can use named-entity recognition to label any content that does not contain the names of dog breeds. Existing knowledge resources can be combined with such simplistic logic to label training data for using it in a new model.
This labelling function returns ‘None’ more often, which leads to only a few parts of data getting labelled.
Any organisation that looks towards machine learning will have to deal with the challenges that come with data labelling. The need for hand-labelled training datasets becomes obvious right at the beginning of the pipeline.
Data labelling requires the following:
- Collecting labels
- Developing label instructions
- Training subject matter experts to carry those instructions
- Deal with failing training datasets with evolving applications
In order to generate high quality-correlated labels, the researchers at Google introduce Snorkel Drybell, a framework which uses generative modeling technique.
In industry and other domains there has been an increased affinity towards programmatic or otherwise more efficient but noisier ways of generating training labels, often referred to as weak supervision.
Snorkel Drybell, adapts the open-source Snorkel framework to use diverse organizational knowledge resources like internal models, ontologies, knowledge graphs to generate training data for machine learning models at web scale.
Snorkel DryBell, integrates with Google ’s distributed production develops weak supervision strategies over millions of examples in less than thirty minutes.
In this technique, unlike the previous weakly supervised models, an effort is made to build complete systems which can manage multiple sources of weak supervision that take in diverse accuracies and correlations.
Snorkel DryBell enables writing labelling functions that label training data programmatically.
This technique automatically estimates the accuracies and correlation consistently without any ground truth training labels.
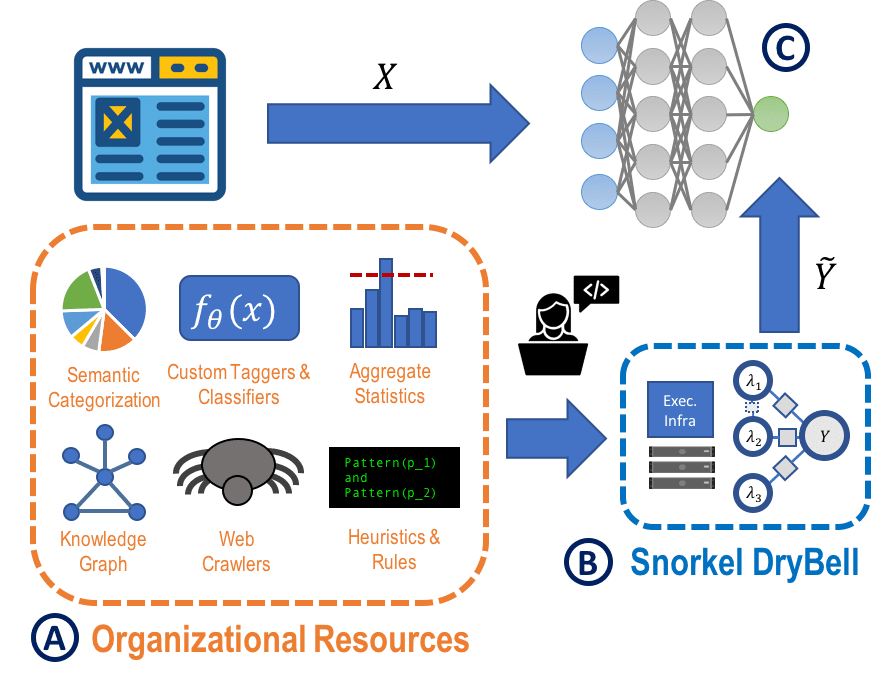
This framework makes use of the following information:
- Heuristics and rules
- Taggers and classifiers
- Aggregate statistics
- Entity graphs
This information is then used to write labelling functions in a MapReduce based pipeline.
Each labelling function takes in a data point and either gives a label or just stays silent.
To achieve accuracy, noisy labels need to be handled and to do this Snorkel DryBell combines the outputs from the labelling functions into a single, confidence-weighted training label for each data point.
And, to evaluate the topic and product classification, the training labels estimated by this framework are used to train logistic regression classifiers with features similar to those in production.
Training is done using the FTLR optimisation algorithm, which is a variant of the stochastic gradient descent. The initial step size here is 0.2 and trains over 10,000 iterations for topic classification task and more than 100K for the product classification task.
Key Findings
- Users can write labelling functions over on unservable feature set and then use the output to train model over different servable feature set.
- This feature boosts performance by an average of 52% on the benchmark datasets.
- Efficient and inexpensive deployment of models.
- A new kind of transfer learning- transferring domain knowledge between different feature sets.
The transfer of knowledge between feature sets has great potential in medical applications where the datasets are large and vague.
There are other challenges that surface while dealing with large data such as data fusion and truth discovery. The aim of data cleaning is to identify and rectify the errors in the datasets. Generative models used in Snorkel DryBell framework can be used for the aforementioned data cleaning challenges.



































































































