




The call for an early detection of risks of default has become louder in the financial world, not least because of the losses incurred in the wake of the financial crisis. The question arises which methods significantly improve the detection rates and deliver this detection at an earlier stage. In the context of a benchmark analysis we discuss and deliver an overview of potential methods and their results. In addition, we quantify the optimisation potential of an established stochastic method versus a new development from the domain of machine intelligence.
The current situation
The aftermath of the financial crisis can be still felt in current insolvency statistics. The number of newly opened insolvency proceedings skyrocketed from 2004 to 2012 (from 95,035 to 137,653) [see Federal Statistical Office, 2013]. This development is reflected in the P&L of banks and jeopardises their profitability. Thus, owing to the increased volume of non-performing loans the provisions for value adjustments and risks of default had to be increased by many institutes.
Understandably, this trend has also mobilised banking supervision and is addressed as a main objective for the latest version of Minimum Requirements for Risk Management (MaRisk) and the “Principles for Effective Risk Data Aggregation and Risk Reporting” published by the Bank for International Settlements (BIS) with respect to the management of loans and an early detection of defaults. However, these alarming signals should not be mistaken for mere forerunners of a future compliance issue. The actual focus of banks should be on the early detection and reduction of credit default risks, thereby reducing the volume of actually defaulted loans and thus the burden on banks’ equity and P&L.
The most effective means against the default of loans is the early identification of non-performing loans. By gaining time, effective measures can be taken to prevent a loss. This could include e.g. the transfer of cash, a change in due date or a restructuring. Sufficient time for a response and taking the correct actions are the biggest assets in successfully handling of a non-performing loan.
Advantages and disadvantages of various early warning systems
What conclusions need to be drawn from these insights to be able to implement an effective as well as efficient early risk detection system? The simple answer is: the system has to offer excellent forecasting abilities to identify non-performing loans early on without delivering too many false positives, i.e. credits incorrectly assessed as being at risk of default. Unnecessarily troubling customers who are not at risk might strain the relationship with the lender beyond repair.
Whether current early warning systems meet these supposedly simple requirements is discussed below. In addition, we demonstrate an alternative to the current practices that fulfils these postulates.
The currently prevalent systems can be categorised as follows:
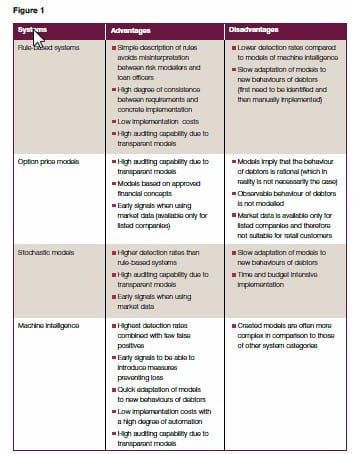
- Rule-based systems
- Option price models
- Stochastic models
Figure 1 summarises the advantages and disadvantages of each system category.
Below, we discuss an alternative in the shape of systems based on machine intelligence:
Early risk warning systems in times of increasing insolvency proceedings
The analysts at Ernst & Young expect that by the end of 2013, 7.8 percent of the loan amount (corresponding to about EUR 940bn) has to be written off as defaulting loans in the Eurozone – a new record [see Ernst & Young, 2013: EY Eurozone Financial Services Forecast]. According to the same source, however, compared to the rest of Europe the German banks are doing relatively well with a share of defaulting loans of 3.2 percent at present.
However, we have experienced a significant increase in the new openings of insolvency proceeding since 2004, leading to an increase of 45 percent till 2012. But if you recall the situation at the beginning of the new millennium, we can assume that this significant increase in the number of newly opened insolvency proceedings need not be the end of the road by any stretch of the imagination. From 2000 to 2006, the number of proceedings in Germany increased by over 600 percent (from 19,698 to 143,781 proceedings) [see Federal Statistical Office, 2014: Insolvenzverfahren: Deutschland, Jahre, Beantragte Verfahren]. This outlook brings the necessity for an effective as well as efficient early risk warning system right at the centre of attention for banks.
Challenges in the implementation of early warning systems
The above insights suggest that an early warning system using powerful forecasting abilities to detect non-performing loans is a key to preventing defaulting credits.
What, then, are the challenges faced when implementing such an early warning system?
The challenges can be summarised in two basic problem areas: on the one hand the use of a data basis that enables an early identification of non-performing loans, and on the other hand the use of a model that enables a precise and specific identification of non-performing loans.
So far early risk warning systems frequently involve loan officers (manually) evaluating balance sheet data and data on the payment behaviour of debtors. These evaluations are at best discussed in cross-departmental committees which furthermore consider the analysis of the current market situation – also frequently in descriptive form and not through a quantitative analysis. For these analyses, data as well as analysis methods stemming from the expertise of the decision makers are used.
The American economist and laureate of the Nobel Prize for Economics, Milton Friedman, once said that he was interested in the results of forecasting models but not in the underlying methods. What does this statement mean? If the forecasts results are correct, then the plausibility of the model emerging from among various models is of secondary importance. In other words: given valid results, one should also allow models and the use of data whose logic with respect to the observable phenomenon one does not necessarily understand. The economic approach to resolving this issue: let’s have the competition for forecasting quality decide over the use of models and data. And this is exactly what we did in the context of a pilot project – as described in the following section.
Benchmark analysis: stochastic models vs. machine intelligence
The authors have created two early warning models, one for a promising approach from the category of “stochastic models” as a reference model and one for a new representative from the category of “machine intelligence”. The reference model works with standardised key performance indicators (KPIs) that were calculated on the basis of financial figures of Swiss small and medium-sized enterprises (SMEs) and uses the method of logistic regression. (Detailed information on the data used is available from the authors upon request).
The model of machine intelligence additionally uses trends and time series that were determined with the help of market and macroeconomic data. Furthermore, it has the ability to combine methods in order to use the advantages of a specific approach while reducing or eliminating its weaknesses through the other methods.
As a result, non-linear relationships of complex patterns are also detected. The model combines the following methods: ensemble decision tree, automatically detected non-linear functional combinations of attributes, risk-based scaling and logistic regressions.
Apart from the decision on the methods to be used, the question also arises about the point in time when system support should be provided for identifying non-performing loans. On the one hand, this is necessary when monitoring the current credit portfolio of an institute at regular intervals in order to avert impending defaults. On the other hand, for cost reasons potentially defaulting debtors need to be identified at the beginning of the lending process, meaning no loan is granted to representatives of this risk group in the first place and the complex process of handling non-performing loans can be avoided as much as possible.
The forecasting quality of the models is crucial
For determining corporate clients at risk of default in the existing credit portfolio, it is irrelevant for the lending party how well the model forecasts “good risks”, i.e. corporate clients who are not at risk. When evaluating the creditworthiness of applicants at the beginning of the lending process, the system not only has to detect applicants with a high potential credit risk (true positives). In addition, it also has to ensure that not too many applications are rejected whose applicants actually have a low credit risk but were falsely classified as “at risk” by the system (false positives), as otherwise the credit institute would miss out on valid income.
Instead, the forecasting quality in the rating categories with a high risk of default is far more important. As seen in Figure 2, compared to the stochastic model the model of machine intelligence detects approx. 60 percent more defaults for both the highest rating classes.
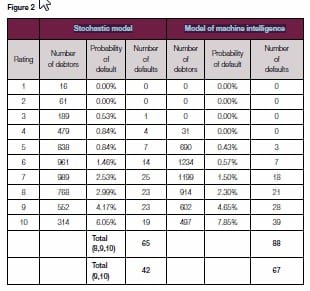
The number of debtors, the extent of the realised probability of default and the number of realised defaults relate to the debtors assigned in this rating class. When quantifying the losses detected with the help of the different models using the default data of a medium-sized credit institute, the following results emerge:
- The stochastic model (reference model) can at an early stage detect losses in the range of EUR 110m in the three categories with the highest risk of default (classes 8-10).
- The model based on machine intelligence (alternative model) can at an early stage detect losses in the range of EUR 150m in the three categories with the highest risk of default (classes 8-10).
- Assuming that a loss cannot be completely avoided in all the cases detected early on, meaning only up to 10 percent in the reference model and up to 30 percent in the alternative model (improvement due to the optimisation of the model in terms of early detection), then the comparison of models indicates that the model based on machine intelligence delivers additionally averted losses amounting to approx. EUR 35m or 17 percent of the total loss per annum.
The analysis assumes net additions to adjustments and provisions in the credit business amounting to about EUR 200m p.a. that are booked in the P&L.
The temporal aspect of early detection
We now need to address the question whether the assumption is justified that by using the model based on machine intelligence 30 percent instead of 10 percent of detected potential losses can be prevented. As mentioned above, the temporal aspect is crucial for the success of any measures taken. If we not only compare the results of better detection, as in the figure above, but also consider this temporal effect, then the picture becomes even more clear. Figure 3 shows that the model based on machine intelligence is as well in the lead in this discipline. Almost 20 percent of the defaults are detected two years before the stochastic model, and over 50 percent are detected at least one year ahead of the reference model. When one gets a minimum of one year of additional time for 70 percent of the impending losses to identify appropriate measures to avert loan default together with the client, then in our opinion this substantiates the above assumption.

Summary
Credit institutes face a situation where we see an increasing number of loan defaults. This trend is likely to intensify with rising interest rates, as the first years of the new millennium suggest. Therefore, now even regulators demand the implementation of early warning systems helping to detect risks early on and with high confidence.
These criteria were used as target values of a benchmark analysis for the data of Swiss SMEs. For the purposes of this analysis, a model was prepared for two representatives from the most promising system categories. The analysis shows that the models from the field of machine intelligence deliver superior results. In the above example of a medium-sized credit institute, additional losses amounting to approx. EUR 35m p.a. could have been prevented by using this model.
Given these results, it should only be a matter of time until the methods of machine intelligence are used more frequently to monitor credit risks. This holds even more true in the light of the constant urge to identify and leverage available potentials to reduce costs.
Authors:
Michael Strumpf
Michael Strumpf has a 15 years experience in consulting of various risk management topics with a strong focus on the application of machine learning techniques since 6 years. He covers topics like early warning systems for market, credit and liquidity risk, fraud detection (card, payment and internal fraud) as well as sales optimization and client segmentation. He holds a Master in Economics from the University of Zurich and the Financial Risk Manager of GARP (Global Association of Risk Professionals).
michaelstrumpf1968@gmail.com
Christian Schaefle
Christian Schaefle, CEO System Design Consulting Prospero AG (www.prospero.ch), has 25 years professional experience in controlling and management information and the design and realization of decision relevant information systems. The special focus are business solutions based on machine intelligence. He holds an MBA from the university of St. Gallen.
www.prospero.ch
c.schaefle@prospero.ch
















