






|
Listen to this story
|
Image, video, and 3D generation has been taking big leaps with the development of diffusion models and Neural Radiance Fields (NeRF). In August, Google Researcher from London, Ben Mildenhall, developed a 3D reconstruction model on the open-source project MultiNeRF, called RawNeRF which created 3D scenes from a set of 2D images.
Recently, Google AI Research released two research papers in this domain. First, LOLNeRF: Learn from One Look, that can model 3D structures and appearances from a single view of objects. And second, InfiniteNature Zero, an algorithm that can generate natural free flowing scenes from a single image.
3D models from a single view of an object
The initial implementations of NeRF were to remove noise, improve lighting, and synthesise a set of images into 3D spaces with modifiable depth of field effects. The challenge in computer vision to generate images is now a task easily achievable by AI tools like DALL-E, Midjourney, and StableDiffusion using diffusion models. However, generating 3D structures from those output images is a field that is still in works and NeRF has shown groundbreaking results in the task.
While most models that work on NeRF like RawNeRF, RegNeRF, or Mip-NeRF require multi-view data to generate information, Google Researchers Daniel Rebain, Mark Matthews, Kwang Moo Yi, Dmitry Lagun, and Andrea Tagliasacchi developed LOLNeRF that only requires a single image of an object to infer its 3D structural information. The depth estimation and novel view synthesis is achieved by combining NeRF with Generative Latent Optimization (GLO).
Combining NeRF with GLO—the researchers were able to generalise latent codes by understanding the common structure in the data input by a neural network and re-create a single element—the model was able to reconstruct multiple objects. Since NeRF is inherently 3D, the combination was able to learn common 3D structures from single view images across instances, while retaining the specificity of the dataset.

An important factor for depth estimation in this process is knowing the exact camera angle and location relative to the object. The researchers used MediaPipe Face Mesh to identify and extract five prominent locations from the subject image. This works by understanding the consistency of features of an object like the tip of the nose or the edge of the ears etc. Then with this mesh, the algorithm can point canonical 3D locations and feed them into the system to measure the distance between the camera and that specific point.

Since the model is generated using a single image, there is a certain amount of blur and loss of information. This was addressed by separating the background and foreground using the MediaPipe Selfie Segmenter that identifies the created mesh as a solid object of interest and removes distraction from background, hence increasing the quality.
You can find the paper for LOLNeRF here.
Creating infinite self-supervised natural videos from a single image
We have seen text-to-image generators and 3D models creators. But Google Researchers from Cornell University, Zhengqi Li, Qianqian Wang, and Noah Snavely, along with Angjoo Kanazawa from UC Berkeley have now made it possible to create infinite drone-like videos from a single image of a landscape using Perpetual View Generation.
InfiniteNature-Zero builds on Infinite Nature, introduced in late 2021 by Google Researchers led by Andew Liu, Richard Bowen, and Richard Tucker. Where InfiniteNature-Zero stands out is given in its name; it is trained without any additional data. While Infinite Nature was trained with point maps that described 3D terrain, physical locations, and video data that processed the camera movement using generated information, the “Zero” version was trained and tested on individual images gathered from the internet.

How it works is that the algorithm recursively generates one forward frame starting from the input image. Each generated image is used to predict and create the next image, eventually sequencing all images into frames of a seamless video.
During training, the model is exposed to an altered version of the input image as previous and next frames of the “to be generated” video. Unlike the previous version’s supervised learning technique where missing regions were created with inpainting supervision, the “Zero” version treats the input image as the next view for the video allowing a cyclic virtual camera trajectory that flies like a drone.
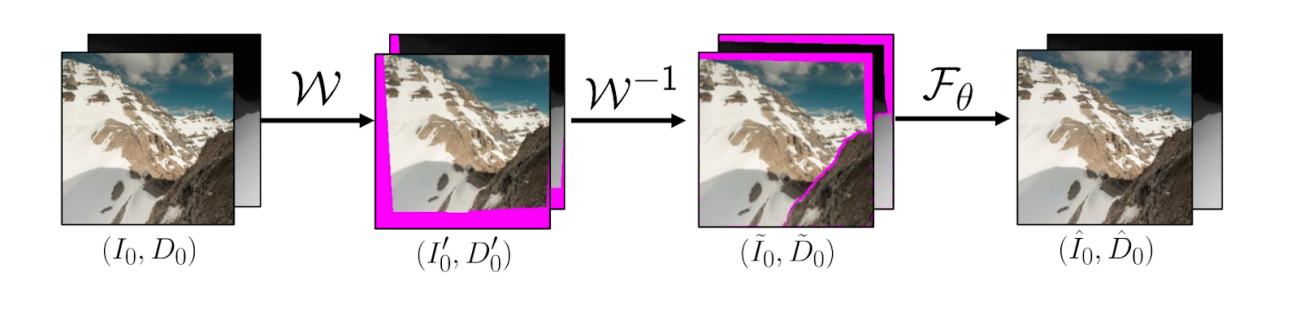
Since the sky is an important part of a landscape photograph, the team devised a method to stop redundantly outpainting a similar sky in each image and used GAN inversion to create a canvas of higher resolution field of view and treating sky as an infinite object.
During testing, without learning from a single video during training, the approach can create long drone-like camera trajectories, generate new views from a single input image, and create realistic and diverse content. A limitation pointed out by the researchers was that there was a lack of consistency in object generation in the foreground and to a certain extent, globally as well—which can be addressed by creating 3D world models.
When compared to other video synthesis models that rely on multi-view inputs and a ton of training data, the self-supervised model generated state-of-the-art outputs using a single image. Though the code is yet to be released, the developers hail it as one of the crucial steps for creating open-world 3D environments for games or the metaverse.
For a guide to Perpetual View Generation, click here.

















