






 The 2008 financial crisis was a black swan moment for millions of people both inside and outside the tech world when they realised that the computing systems and the infrastructure is not always robust. Non-stop computing systems, especially, require round-the-clock monitoring. Basically, a large volume of incoming time-series data is monitored here for bugs or anomalies. The scale at which this data is gathered makes it difficult to detect anomalies.
The 2008 financial crisis was a black swan moment for millions of people both inside and outside the tech world when they realised that the computing systems and the infrastructure is not always robust. Non-stop computing systems, especially, require round-the-clock monitoring. Basically, a large volume of incoming time-series data is monitored here for bugs or anomalies. The scale at which this data is gathered makes it difficult to detect anomalies.
Current models encounter a large number of false positives; and with changing characteristics of the time-series, these models require additional training.
In a paper titled AnoGen: Deep Anomaly Generator, researchers at Facebook make an attempt to generate a realistic time-series with anomalies by overcoming challenges like validation and testing. This work by Nikolay Laptev of Facebook is highly inspired by the repeated success of VAEs and GANs.
Examples of Time-Series Anomaly Trends
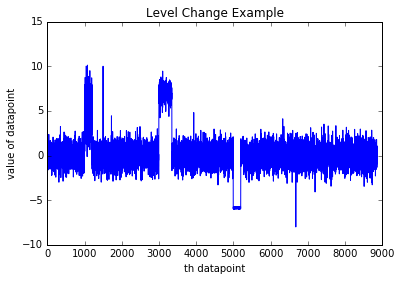
Upward and downward level changes
For example, assume you have been monitoring the number of requests per day to a web service over a period of time, and the number of requests appears to stay within a certain range. However, after an update to the web service, the number of requests to that web service changes. The new trend might be either higher or lower than the original trend; both upward and downward spikes can be detected.
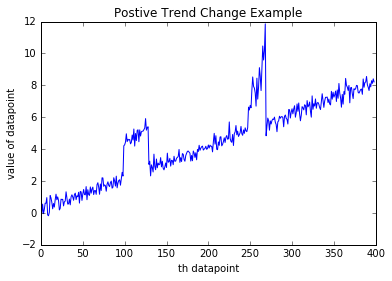
Positive or negative trends changes
For example, assume you are monitoring the length of a queue on a service support site. A persistent upward trend might indicate an underlying service issue. In other cases, a persistent negative trend might be the anomaly. For example, if you are monitoring memory usage on a server when free memory size shrinks, it could indicate a potential memory leak.
Deep Time-Series Anomaly
A simple way of generating an anomaly is by picking up some anomaly features from a random distribution.
AnoGen learns the time-series normal and abnormal distributions using the VAEs. To generate possible outliers, sampling is done in the outlier region of latent variable z.
In practice, for time-series data, the results produced by the generative adversarial model and by the variational autoencoder are similar with the variational autoencoder being significantly faster and easier to train. The training was done on about 100K series and it works as follows,
Data: Init
Result: Time-series with anomalies
while Length of result time-series not met do
read current idx; if idx is not anomaly then
sample from normal space and add point to result;
else
sample from anomalous z region and add to result;
end
end
Sampling this latent space ‘z,’ enables the model to generate a rare time-series behaviour. An example of the resulting time-series with an anomaly in the middle of the time-series is shown below.

via AnoGen paper by Facebook research
The machine learning model used for Anomaly Detection is differentiated as a simple binary classifier that for every time-step ‘t,’ gives an output of 1 in case of an anomaly or else 0.
By leveraging the true time-series, AnoGen was able to capture representative series behavior which was used to train the model to significantly outperform the same Anomaly Detection model trained using the baseline method on the manually labeled test-set.
Lack of labeled data makes it difficult to iteratively improve an anomaly detection model. Therefore, instead of a pure synthetic time-series and anomaly data is used to make model deliver decent results for outlier detection. In this paper, AnoGen, uses a Variational Autoencoder to learn the latent space representation of real time series to generate a representative time-series with anomalies by sampling from the learned latent space. The results indicate superior performance for training an Anomaly Detection machine learning model. This is an important first step towards reducing the reliance on manually curated time-series data for anomaly detection model training.
The goal here is to utilize Machine Learning and statistical approaches to classify anomalous drops in periodic, but noisy, traffic patterns. Lack of labelled examples makes it impossible to directly apply supervised learning for anomaly classification.
Time-series data gathering is prevalent across a wide range of domains and it gets cumbersome with non-linear data where this data can be verified for taking instantaneous actions like in the case faulty credit card usage or over few decades in case of effects of climate change as illustrated below.

Visualising how certain properties characteristically change over time enables us to predict and prepare in case of a catastrophe. There are many anomaly detection methods emerging from the hoods of giants like Google and Facebook.
Google uses TensorFlow to train models including deep neural networks, recurrent neural networks and LSTMs to predict a certain value in the time series using regression. Whereas, Microsoft has a built-in-house module for Time Series Anomaly Detection in its Azure Machine Learning Studio.
There are many such ingenious solutions and there are many more to be discovered because detecting these outliers (anomalies) is crucial in fast-paced environments like digital banking or medical diagnoses where a catastrophe is just around the corner.


















