



The advances in computing hardware technology have paved way for easier implementations of machine learning and artificial intelligence applications to solve real-world problems. But most of these developments in computer architecture have focussed more on parallel scaling rather than frequency scaling. This technological digression is unfavorable for applications which has sequential ML algorithms. Therefore, this requires to have a general framework for ML models to work efficiently in the parallel computing environment.
In this article, we will discuss GraphLab (now called Turi), which is a distribution framework written in C++. It was originally developed by academics at Carnegie Mellon University for handling ML tasks, but now has extended to data mining applications as well. It provides a high-level programming interface for graphical ML algorithms, and is mostly suitable for sparse data and iterative algorithms. It also has a Python library to meet ML algorithmic requirements. It enables easy and efficient design of parallel ML algorithms by taking care of computation requirements, data consistency and scheduling.
Graphical ML Models: The Basis For Creating GraphLab
Carlos Guestrin, the founder of GraphLab, recalls that the platform was developed to speed up graphical ML model computations. These models were difficult to run on computation frameworks such as Hadoop which also took a really long time. Since the graphs were computation-intensive, they demanded a computation framework for ML algorithms, specifically that contained graphical data. Thus emerged GraphLab, a platform that it could address data as well as their computations simultaneously on a shared-memory architecture.
This is also made possible by providing a high-level data abstraction for users, which is evident in the data graphs. Hence, GraphLab obtains a fine balance between low-level abstractions such as POSIX threads, and high-level abstractions such as MapReduce models, without confusing ML experts with many intricate details. As mentioned earlier, GraphLab considers sparse data and iterative computations to achieve this balanced level of abstraction.
The GraphLab Data Model
According to the design developed by Carlos Guestrin and team at Carnegie Mellon University, the data model in GraphLab consists of a data graph and a shared data table. In the words of the researchers,
“The data graph G = (V, E) encodes both the problem specific sparse computational structure and directly modifiable program state. The user can associate arbitrary blocks of data (or parameters) with each vertex and directed edge in G. We denote the data associated with vertex v by Dv, and the data associated with edge (u → v) by Du→v. In addition, we use (u → ∗) to represent the set of all outbound edges from u and (∗ → v) for inbound edges at v. To support globally shared state, GraphLab provides a shared data table (SDT) which is an associative map, T [Key] → Value, between keys and arbitrary blocks of data.”
The researchers make use of Loopy belief propagation coupled with Markov Random Fields (MRF) for GraphLab’s framework to demonstrate its functionality in line with ML.
The Structure For Developing A Parallel Model In GraphLab
Referring back to the design for executing parallel ML algorithms, GraphLab follows on the three key steps which are put forth below:
- User-defined computation: GraphLab’s computation criteria stems from an ‘update function’ from the data, which is defined by the user. The computation can also be invoked through a sync mechanism that works with the graphical data.
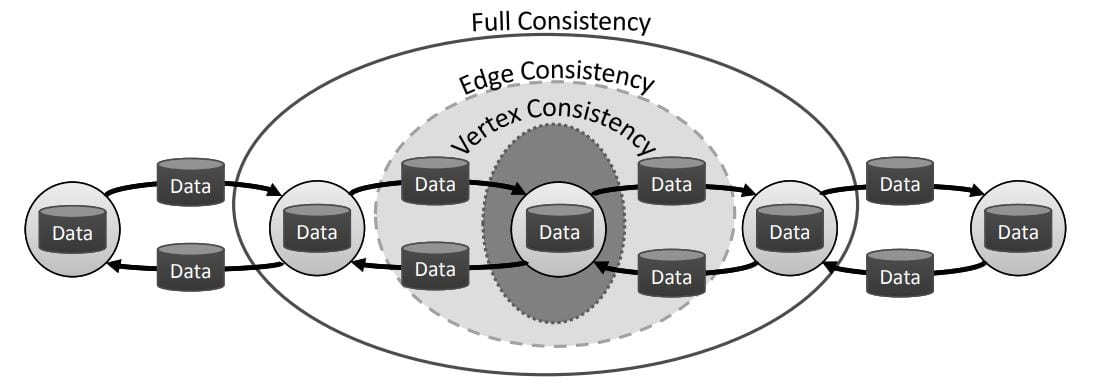
- Data consistency: GraphLab provides three data models to balance consistency and system performance. They are labelled as full consistency model, edge consistency model and vertex consistency model. Considering the scope or the extent of data [f(v)] for the project, the full consistency model permits execution of function along the vertex data on a graph. The edge consistency model focuses on the edges of the whereas the vertex consistency model focuses on the vertex. Therefore, it is essential that the appropriate model is thought-out for ML models with a parallel computing function. The consistency models are illustrated below.

Consistency models depiction (Image courtesy: Carlos Guestrin) - Scheduling: The ‘update schedule’ function takes care of the update functions applied to the vertices based on the consistency model, and is represented by a data structure called scheduler. This scheduler maps a dynamic list of vertex-functions combination and is executed in the GraphLab engine. The schedulers can be modified according to the ML algorithms, for example, in a residual neural network with backpropagation, there are task schedulers such as FIFO scheduler and Priority Schedulers that assigns ML tasks accordingly.
In order for a GraphLab program to execute successfully, these steps must be followed in a sequential order.
Conclusion
Parallel ML algorithms or models built with GraphLab provide a computing environment for parallel data structures. This means that much of the data structure features are yet to be fully realised in terms of their ML as well as computational potential. With GraphLab’s API, this can be achieved and ML professionals can easily import algorithms from other frameworks such as MapReduce.







































































