


 The reliability of a machine learning model is assessed based on how erroneous it is. Lesser the number of errors, better the prediction. In theory, ML models should be able to predict, classify and recommend right every single time. However, when deployed in the real world, the model has a very good chance of running into information that has never appeared during training. To prepare the model for such untimely adversities, adversarial techniques have been developed.
The reliability of a machine learning model is assessed based on how erroneous it is. Lesser the number of errors, better the prediction. In theory, ML models should be able to predict, classify and recommend right every single time. However, when deployed in the real world, the model has a very good chance of running into information that has never appeared during training. To prepare the model for such untimely adversities, adversarial techniques have been developed.
Adversarial examples are inputs to machine learning models that an attacker has intentionally designed to cause the model to make a mistake.
What Do Adversarial Examples Look Like

In the above example, the image of the panda is given an adversarial input. This input is overlaid on a typical image to cause a classifier to miscategorize a panda as a gibbon.
But how critical is the monitoring of adversarial attacks on model?
For instance, attackers could target autonomous vehicles by using stickers or paint to create an adversarial stop sign that the vehicle would interpret as a ‘yield’ or other sign. A confused car on a busy day is a potential catastrophe packed in a 2000 pound metal box.
Nevertheless, extreme cases need not only be scenarios of life and death but also can be a flawed facial recognition system installed at a money lending machine or a smart door system that doesn’t recognise its owner.
The whole idea of introducing adversarial examples to a model during training is to ensure AI safety. In short, avoid misclassification.
Preparing For Unforeseen Attacks
Notably, common classification benchmarks often do not naturally provide such protections on their own. Further, besides explicitly incorporating this information, they give away if the learning algorithms are inferring good similarity structure.
In an attempt to fortify a model’s defense strategy to avoid misclassification, researchers at Open AI introduce a new metric, UAR (Unforeseen Attack Robustness), which evaluates the robustness of a single model against an unanticipated attack, and highlights the need to measure performance across a more diverse range of unforeseen attacks.

If one looks at the picture above, they can make an educated guess that it is a picture of a black swan. They can also see the distortions in the image but that’s fine. It doesn’t make much of a difference to a human. However, change in pixel values ends up confusing the machine learning model.
A model can be trained to detect adversities such as the above distortions. These learnings need not necessarily be transferred for future unforeseen distortions.
The researchers propose a 3-step method to tackle the above challenge, which can be summarized as follows:
- Evaluate models against adversarial distortions that are not similar to those used in training. Consider L_1, L_2 JPEG, Elastic, and Fog attacks as a starting point. They provide implementations, pre-trained models, and calibrations for a variety of attacks in our code package
- Choose a calibrated range of distortion sizes by evaluating against adversarially trained models
- Compute the UAR scores of adversarially trained models for several different distortion types. A UAR score near 100 against an unforeseen adversarial attack implies performance comparable to a defense with prior knowledge of the attack
UAR (Unforeseen Attack Robustness) normalizing the accuracy of a model M against adversarial training accuracy(ATA) is given as:
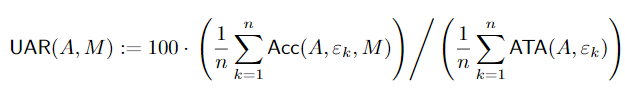
An UAR score greater than 100 means that a defense is outperforming an adversarially trained model on that distortion.
Envisioning AI Safety Through Adversity
Since increasing robustness against one distortion type can decrease robustness against others, the authors in their paper, insist on measuring performance on different distortions is important to avoid overfitting to a specific type, especially when a defense is constructed with adversarial training.
The researchers also find “Common” visual corruptions such as (non-adversarial) fog, blur, or pixelation to be rich with solutions to achieve adversarial robustness. Fog or blur effects on images have emerged as another avenue for measuring the robustness of computer vision models. The robustness to such common corruptions is considered to be linked to adversarial robustness and proposes corruption robustness as an easily computed indicator of adversarial robustness.
However, researchers at OpenAI believe that reliability of a machine learning model shouldn’t just stop at assessing robustness but future research should also focus on building a diverse toolbox for understanding machine learning models, including visualization, disentanglement of relevant features, and measuring extrapolation to different datasets or to the long tail of natural but unusual inputs to get a clearer picture.















































































