


 In a previous article, it was stated that data scientists are trying to find meaningful patterns and correlations in structured data and machine generated data and were not having much luck. Like the fisherman who has been fishing in one place and not having luck, at some point the fisherman pulls the line and bait up and moves the boat.
In a previous article, it was stated that data scientists are trying to find meaningful patterns and correlations in structured data and machine generated data and were not having much luck. Like the fisherman who has been fishing in one place and not having luck, at some point the fisherman pulls the line and bait up and moves the boat.
So where has the data scientist NOT been examining? The answer is that the data scientist has not been looking in textual data and spreadsheet data. Fig 1 shows where the data scientist has not been looking.
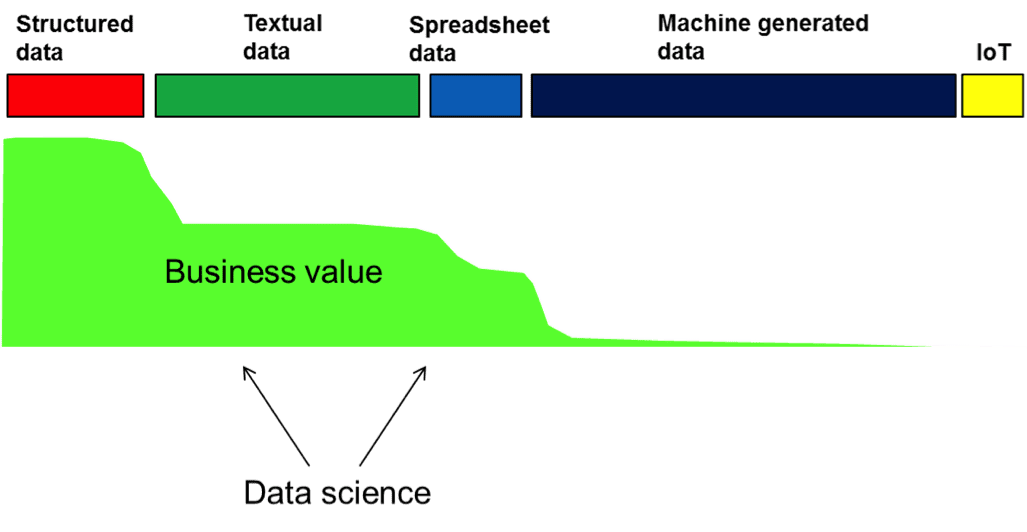
In Fig 1 it is seen that the places where the data scientist has not extensively looked is in textual data and spreadsheet data. Compared to other places the exploration of these types of data is practically nil.
(Actually, the data scientist has tried to use NLP (natural language processing) technology for exploring text, to some extent. But because of the inherent limitations of NLP technology, the results have been less than scintillating.)
And unfortunately, it is in these places where there is MUCH opportunity – much business value – that has not been touched. So is there a reason why data science has not explored text and spreadsheets to any great extent? There are several reasons. But foremost among them is the fact that text and spreadsheets cannot be read and analyzed in the same way that structured and machine-generated data can be read and analyzed.
Data from structured systems and machine generated systems fits conveniently inside a standard data base management system. In structured data and machine-generated data there is the recurring structure of data that occurs over and over. In a word it is easy to get one’s hands on structured and mechanically generated data. But such is not the case at all with text and spreadsheet data. Fig 2 shows that there is an opaque shield surrounding text and spreadsheet data.

So why is there a protecting shield of opaqueness sitting over textual data and spreadsheet data? There are lots of reasons for this protecting shield of opaqueness. The primary reason is that text does not fit conveniently into a standard data base structure. If there ever were the case of putting a square peg in a round hole it is this. In the BEST of circumstances, putting text into a data base management system is an awkward fit. In the worst case it is no fit at all.
A second reason is that text is complex. There are MANY nuances to language that escape the computer. When a child learns to speak a language the child learns these nuances and the nuances come naturally. But trying to teach the computer all those nuances is another matter altogether.
But the misfit with a data base management system and the nuances of language are only the basic reasons why there is a shield of opaqueness sitting over textual data. Another – and even more insidious reason – why text is impervious to analysis is that analyzing text involves looking at BOTH text and context. In many cases context is more important than the text itself. But determining the context of text is very difficult to do.
For these reasons then there is a very real layer of opaqueness that sits over textual data.
Asking the data scientist to start to analyze and make sense of text is like asking an English speaking person to learn and read, speak and write Japanese fluently before a serious analysis can begin. The data scientist wants to produce results. The data scientist doesn’t have the time to learn to read and write Japanese before he/she can get to the data science that is so important to the data scientist. So the data scientist just doesn’t bother with text and spreadsheets.
To a lesser extent the same opaqueness is true of spreadsheet data. Spreadsheet data involves the same issues of context, except that spreadsheets are very different from text. Nevertheless, reading and interpreting data on a spreadsheet has its own separate issues.
So there are some very good reasons why the data scientist has chosen to not attack textual data and spreadsheet data, despite the fact that there is a very large business value there and despite the fact that the business value has – for all intentional purposes – never been explored.






































































