



Introduced by Arthur P Dempster and developed by Glenn Shafer, the Dempster-Shafer theory was designed to mathematically model and validate the uncertainty involved in statistical inferences. This theory allows one to combine evidence from different sources and arrive at a degree of belief, which is mathematically defined by belief functions (Bel).
Also known as the theory of belief functions, the DST is a general framework for reasoning with uncertainty, with understood connections to other frameworks such as probability, possibility and imprecise probability theories.
What Are Belief Functions
Belief functions were initially proposed as a way to achieve generalised Bayesian inference without priors and mathematically related to random sets. Belief functions combine a set of representations and model data when there is a lack of information.
One can ask two questions about a certain hypothesis say, for example, to be or, not to be. These questions are checked for relatedness and then a belief function is quantified. The degrees of belief themselves may or may not have the mathematical properties of probabilities; how much they differ depends on how closely the two questions are related.
Dempster–Shafer theory is constructed with two fundamental ideas: obtaining degrees of belief for one question from subjective probabilities for a related question, and Dempster’s rule of combining such degrees of belief when they are based on independent items of evidence.
Juggling Belief And Plausibility
Dempster’s rule of combination is sometimes interpreted as an approximate generalisation of Bayes’ rule.
Belief in a hypothesis is calculated as the summation of all these masses of all subsets of the hypothesis-set. The value of belief gives a lower bound on its probability.
Belief(Bel) ranges from 0 to 1 where 0 indicates no evidence and 1 indicates certainty.
Plausibility(Pl) = 1-Bel.
For instance, there is certain news that needs to be checked whether it is fake or factual. Shafer’s framework allows for belief about such propositions(say, the news is real) to be represented as intervals, bounded by two values, belief(that the proposition is right) and plausibility(the chances of the news being really real). Subjective probabilities(masses) are assigned to all subsets of the frame.
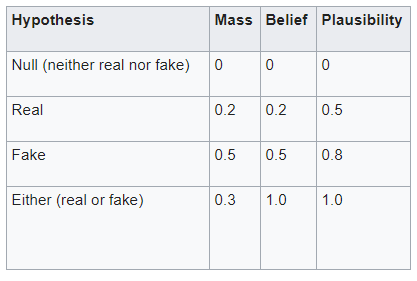
Beliefs from different sources can be combined with various fusion operators to model specific situations of belief fusion, e.g. with Dempster’s rule of combination, which combines belief constraints. The combination (called the joint mass) is calculated from the two sets of masses m1 and m2 in the following manner:The null hypothesis is set to zero by definition (it corresponds to “no solution”). The orthogonal hypotheses “Real” and “Fake” have probabilities of 0.2 and 0.5(assigned randomly), respectively.

How Can D-S Theory Applied In Machine Learning
In logistic regression, the classifiers can be shown to convert higher-level features into Dempster-Shafer mass functions by aggregating them using Dempster’s rule of combination. The mass functions here are more informative than the outputs with a probability distribution. When none of the features provides distinguishable information, these mass functions give insights about the impact of each feature in logistic regression.
Movie reviews and product reviews are the main sources of data to draw inferences for improving the user experience. Since it is impossible to manually read all the reviews, a machine learning model is deployed to do the sentiment analysis. Text and speech are two forms of data that are taken. In the case of text, NLP algorithms come in handy. A sentence gets tokenized into smaller parts and then a semantic relationship is formulated using these individual words. To predict the degree of positivity or negativity associated with a few lines of review requires an aggregation score method. In this paper, the authors demonstrate how the DST does well compared to other aggregation models for conducting document level sentence prediction.
These are only 2 of many other use cases where D-S theory can serve as an alternative to the popular ones. The efficacy of this theory can only be put to test when it is deployed on large scale and in real-world applications.
Conclusion
There is now a dedicated community which deals with the advancements and applications of belief functions, which goes by the name Belief Functions and Applications Society(BFAS).
Dempster–Shafer theory allows one to specify a degree of ignorance in this situation instead of being forced to supply prior probabilities that add to unity. The normalization factor above, 1 − K, can run into the danger of ignoring the conflicting questions and quantify it as a null set. This combination rule for evidence can, therefore, produce counterintuitive results. This renders a decision-making scenario tricky with the difference between risk and ignorance becoming bleak. Situations such as these have put this theory in a spot and it has a hard time getting accepted into the mainstream.














































































