



|
Listen to this story
|
In a blog post last week, Google AI introduced ‘PaLI’, a jointly-scaled multilingual language-image model that is trained to perform various tasks in over 100 languages.
The goal of the project is to examine how language and vision models interact at scale, with a keen focus on the scalability of language-image models.
The recently unveiled model would carry out tasks spanning vision, language, multimodal image and language applications—such as visual question answering, object identification, image captioning, OCR, and text reasoning.
The researchers have used a collection of public images, which includes automatically collected annotations in 109 languages called the ‘WebLI dataset’. The PaLI model, pre-trained on WebLI, is claimed to achieve state-of-the-art performance on challenging image and language benchmarks, such as COCO-Captions, CC3M, TextCaps, nocaps, VQAv2, and OK-VQA.
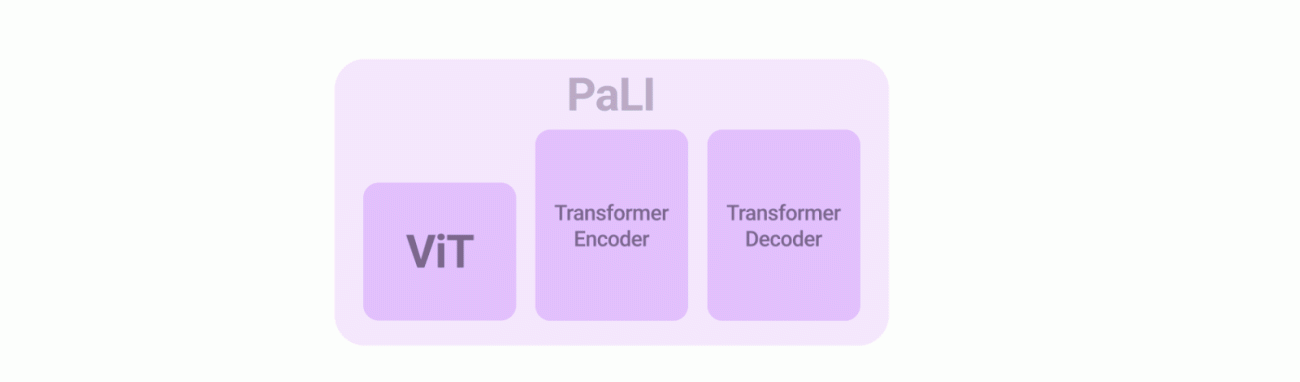
The architecture of the PaLI model is said to be simple, scalable and reusable. Input text is processed with the help of a Transformer encoder along with an auto-regressive Transformer decoder that generates the output text. The input to the Transformer encoder additionally includes “visual words” that represent an image that has been processed by a Vision Transformer (ViT).
Deep learning scaling research suggests that larger models need more datasets to train efficiently. According to the blog, the team created WebLI—a multilingual language-image dataset made from images and text readily available on the public web—in order to unlock the potential of language-image pretraining.
It further adds that, “WebLI scales up the text language from English-only datasets to 109 languages, which enables us to perform downstream tasks in many languages.The data collection process is similar to that employed by other datasets, e.g. ALIGN and LiT, and enabled us to scale the WebLI dataset to 10 billion images and 12 billion alt-texts.”
PaLI is believed to outperform prior models’ multilingual visual captioning and visual question answering benchmarks. The team hopes that the work inspires further research in multi-modal and multilingual models. Researchers believe that in order to accomplish vision and language tasks, large scale models in multiple languages are required. In addition, they claim that further scaling of such models is likely to be beneficial for achieving these tasks.





































































